Compare commits
50 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
9ec99143d4 | ||
|
|
575a710ef8 | ||
|
|
7c16307643 | ||
|
|
e816529260 | ||
|
|
8282e59a39 | ||
|
|
a96bdb8d13 | ||
|
|
f7f1c3e871 | ||
|
|
632250083f | ||
|
|
0ebfe43133 | ||
|
|
bb367fe79e | ||
|
|
3a4d405c8e | ||
|
|
8f8adcddbb | ||
|
|
394c831b05 | ||
|
|
bb8b3a3bc3 | ||
|
|
6c5c932b98 | ||
|
|
9a151a5d4c | ||
|
|
f24595687b | ||
|
|
aa130d2d25 | ||
|
|
bccc49508e | ||
|
|
ad6db7ca97 | ||
|
|
b95d35d6fa | ||
|
|
3bf0cf5fbc | ||
|
|
dbdc0c818d | ||
|
|
e156c34e23 | ||
|
|
ee782e3794 | ||
|
|
90aa77a23a | ||
|
|
d4251c8b44 | ||
|
|
6f684e67e2 | ||
|
|
18cf202b5b | ||
|
|
54b2b71472 | ||
|
|
44ba47bafc | ||
|
|
7eb72634d8 | ||
|
|
5787d3470a | ||
|
|
1fce045ac2 | ||
|
|
794aa74782 | ||
|
|
b2e49a99a7 | ||
|
|
d208d53375 | ||
|
|
7158378eca | ||
|
|
0961d8cbe4 | ||
|
|
6ef5d11742 | ||
|
|
45e1d8370c | ||
|
|
420f995977 | ||
|
|
dbe1f91bd9 | ||
|
|
770c5fcb1f | ||
|
|
665d1ffe43 | ||
|
|
14ed221152 | ||
|
|
c41b9c1e32 | ||
|
|
17d4d68cbe | ||
|
|
b5a23fe430 | ||
|
|
2747be4a21 |
@@ -3,6 +3,20 @@ import os
|
||||
import time
|
||||
import re
|
||||
import sys
|
||||
from ADC_function import *
|
||||
import json
|
||||
|
||||
version='0.10.6'
|
||||
|
||||
def UpdateCheck():
|
||||
html2 = get_html('https://raw.githubusercontent.com/wenead99/AV_Data_Capture/master/update_check.json')
|
||||
html = json.loads(str(html2))
|
||||
|
||||
if not version == html['version']:
|
||||
print('[*] * New update '+html['version']+' *')
|
||||
print('[*] * Download *')
|
||||
print('[*] '+html['download'])
|
||||
print('[*]=====================================')
|
||||
|
||||
def movie_lists():
|
||||
#MP4
|
||||
@@ -48,6 +62,10 @@ def rreplace(self, old, new, *max):
|
||||
return new.join(self.rsplit(old, count))
|
||||
|
||||
if __name__ =='__main__':
|
||||
print('[*]===========AV Data Capture===========')
|
||||
print('[*] Version '+version)
|
||||
print('[*]=====================================')
|
||||
UpdateCheck()
|
||||
os.chdir(os.getcwd())
|
||||
for i in movie_lists(): #遍历电影列表 交给core处理
|
||||
if '_' in i:
|
||||
|
||||
110
README.md
110
README.md
@@ -1,17 +1,59 @@
|
||||
## 前言
|
||||
  目前,我下的AV越来越多,也意味着AV要集中地管理,形成媒体库。现在有两款主流的AV元数据获取器,"EverAver"和"Javhelper"。前者的优点是元数据获取比较全,缺点是不能批量处理;后者优点是可以批量处理,但是元数据不够全。<br>
|
||||
  为此,综合上述软件特点,我写出了本软件,为了方便的管理本地AV,和更好的手冲体验。
|
||||
# AV Data Capture 日本AV元数据刮削器
|
||||
# 目录
|
||||
* [前言](#前言)
|
||||
* [捐助二维码](#捐助二维码)
|
||||
* [效果图](#效果图)
|
||||
* [免责声明](#免责声明)
|
||||
* [如何使用](#如何使用)
|
||||
* [下载](#下载)
|
||||
* [简明教程](#简要教程)
|
||||
* [模块安装](#1请安装模块在cmd终端逐条输入以下命令安装)
|
||||
* [配置](#2配置proxyini)
|
||||
* [运行软件](#4运行-av_data_capturepyexe)
|
||||
* [异常处理(重要)](#5异常处理重要)
|
||||
* [导入至EMBY](#7把jav_output文件夹导入到embykodi中根据封面选片子享受手冲乐趣)
|
||||
* [输出文件示例](#8输出的文件如下)
|
||||
* [写在后面](#9写在后面)
|
||||
* [软件流程图](#10软件流程图)
|
||||
* []()
|
||||
# 前言
|
||||
  目前,我下的AV越来越多,也意味着AV要**集中地管理**,形成本地媒体库。现在有两款主流的AV元数据获取器,"EverAver"和"Javhelper"。前者的优点是元数据获取比较全,缺点是不能批量处理;后者优点是可以批量处理,但是元数据不够全。<br>
|
||||
  为此,综合上述软件特点,我写出了本软件,为了方便的管理本地AV,和更好的手冲体验。<br>
|
||||
  希望大家可以认真耐心地看完本文档,你的耐心换来的是完美的管理方式。<br>
|
||||
  本软件更新可能比较**频繁**,麻烦诸位用户**积极更新新版本**以获得**最佳体验**。
|
||||
|
||||
**可以结合pockies大神的[ 打造本地AV(毛片)媒体库 ](https://pockies.github.io/2019/03/25/everaver-emby-kodi/)看本文档**<br>
|
||||
**tg官方电报群:[ 点击进群](https://t.me/AV_Data_Capture_Official)**<br>
|
||||
**推荐用法: 按照 [如何使用](#如何使用) 使用该软件后,对于不能正常获取元数据的电影可以用[ Everaver ](http://everaver.blogspot.com/)来补救**<br>
|
||||
**推荐用法: 使用该软件后,对于不能正常获取元数据的电影可以用[ Everaver ](http://everaver.blogspot.com/)来补救**<br>
|
||||
暂不支持多P电影<br>
|
||||
[回到目录](#目录)
|
||||
|
||||
|
||||
# 效果图
|
||||
**由于法律因素,图片必须经马赛克处理**<br>
|
||||
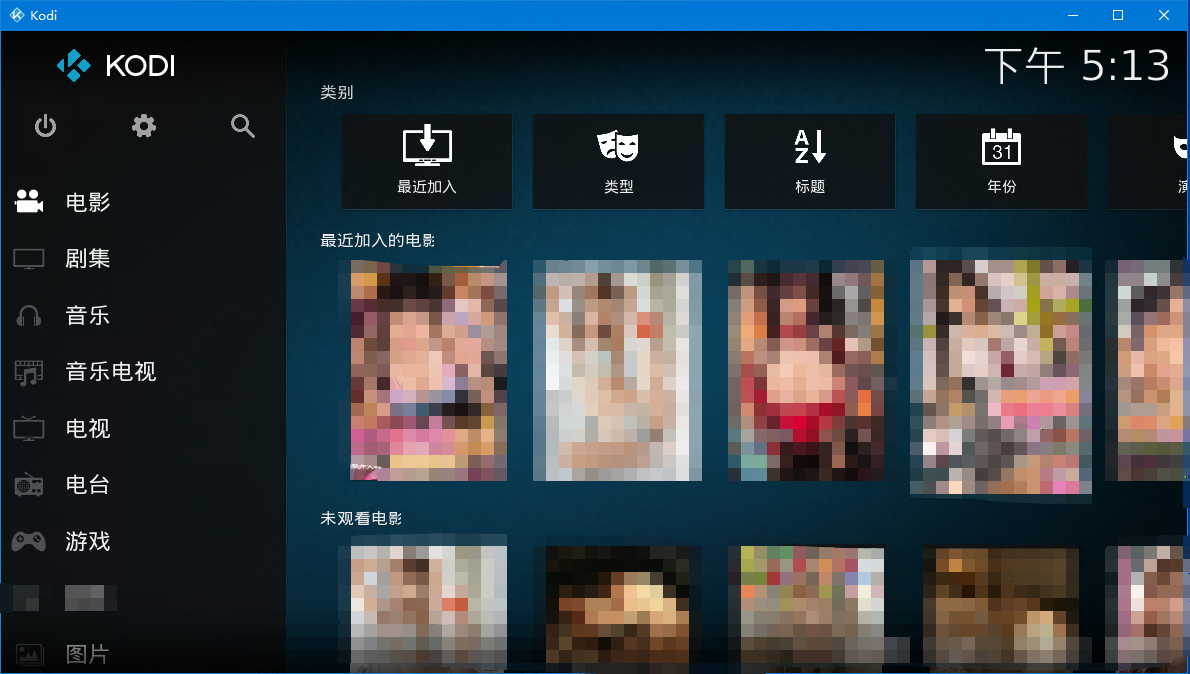
|
||||
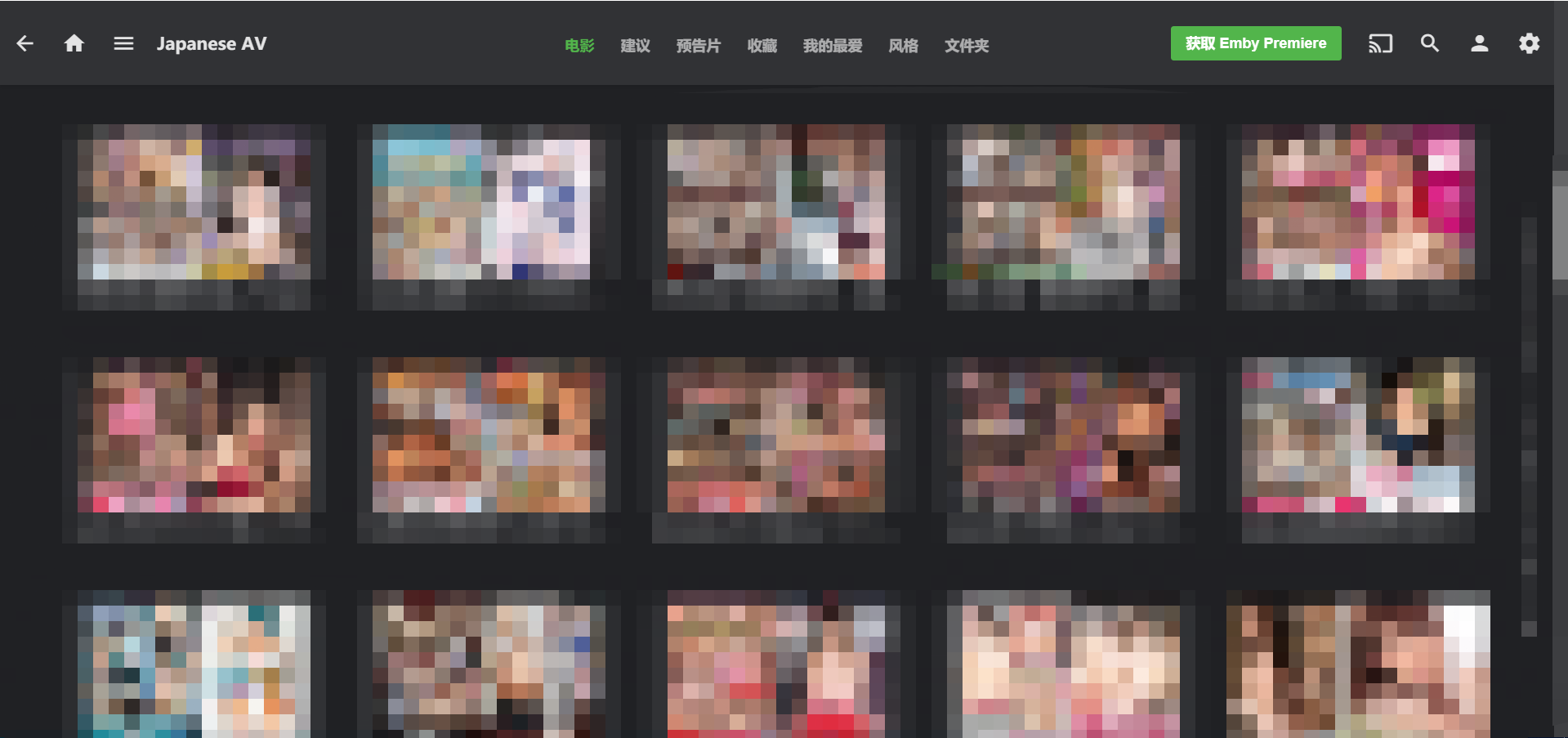<br>
|
||||
[回到目录](#目录)
|
||||
|
||||
# 捐助二维码
|
||||
如果你觉得本软件好用,可以考虑捐助作者,多少钱无所谓,不强求,你的支持就是我的动力,非常感谢您的捐助
|
||||
<br>
|
||||
[回到目录](#目录)
|
||||
|
||||
# 免责声明
|
||||
1.本软件仅供技术交流,学术交流使用<br>
|
||||
2.本软件不提供任何有关淫秽色情的影视下载方式<br>
|
||||
3.使用者使用该软件产生的一切法律后果由使用者承担<br>
|
||||
4.该软件禁止任何商用行为<br>
|
||||
[回到目录](#目录)
|
||||
|
||||
# 如何使用
|
||||
release的程序可脱离python环境运行,可跳过第一步<br>
|
||||
下载地址(仅限Windows):https://github.com/wenead99/AV_Data_Capture/releases
|
||||
### 下载
|
||||
* release的程序可脱离python环境运行,可跳过 [模块安装](#1请安装模块在cmd终端逐条输入以下命令安装)<br>下载地址(**仅限Windows**):https://github.com/wenead99/AV_Data_Capture/releases
|
||||
* Linux,MacOS请下载源码包运行
|
||||
### 简要教程:<br>
|
||||
**1.把软件拉到和电影的同一目录<br>2.设置ini文件的代理<br>3.运行软件等待完成<br>4.把JAV_output导入至KODI,EMBY中。<br>详细请看以下教程**
|
||||
**1.把软件拉到和电影的同一目录<br>2.设置ini文件的代理(路由器拥有自动代理功能的可以把proxy=后面内容去掉)<br>3.运行软件等待完成<br>4.把JAV_output导入至KODI,EMBY中。<br>详细请看以下教程**<br>
|
||||
[回到目录](#目录)
|
||||
|
||||
## 1.请安装模块,在CMD/终端逐条输入以下命令安装
|
||||
```python
|
||||
@@ -35,12 +77,16 @@ pip install pillow
|
||||
```
|
||||
###
|
||||
|
||||
## 2. 配置
|
||||
#### 1.针对网络审查国家或地区
|
||||
|
||||
[回到目录](#目录)
|
||||
|
||||
## 2.配置proxy.ini
|
||||
#### 1.针对网络审查国家或地区的代理设置
|
||||
打开```proxy.ini```,在```[proxy]```下的```proxy```行设置本地代理地址和端口,支持Shadowsocks/R,V2RAY本地代理端口:<br>
|
||||
例子:```proxy=127.0.0.1:1080```<br>
|
||||
**如果遇到tineout错误,可以把文件的proxy=后面的地址和端口删除,并开启vpn全局模式,或者重启电脑,vpn,网卡**
|
||||
**(路由器拥有自动代理功能的可以把proxy=后面内容去掉)**<br>
|
||||
**如果遇到tineout错误,可以把文件的proxy=后面的地址和端口删除,并开启vpn全局模式,或者重启电脑,vpn,网卡**<br>
|
||||
[回到目录](#目录)
|
||||
|
||||
#### 2.(可选)设置自定义目录和影片重命名规则
|
||||
**已有默认配置**<br>
|
||||
@@ -57,11 +103,22 @@ pip install pillow
|
||||
>outline = 简介<br>
|
||||
>runtime = 时长<br>
|
||||
##### **例子**:<br>
|
||||
>目录结构:'JAV_output/'+actor+'/'+actor+' '+' ['+year+']'+title+' ['+number+']'<br>
|
||||
>影片命名(上面目录之下的文件):'['+number+']-'+title
|
||||
>目录结构规则:location_rule='JAV_output/'+actor+'/'+number **不推荐修改目录结构规则,抓取数据时新建文件夹容易出错**<br>
|
||||
>影片命名规则:naming_rule='['+number+']-'+title<br> **在EMBY,KODI等本地媒体库显示的标题**
|
||||
[回到目录](#目录)
|
||||
## 3.把软件拷贝和AV的统一目录下
|
||||
## 4.运行 ```AV_Data_capture.py/.exe```
|
||||
你也可以把单个影片拖动到core程序<br>
|
||||
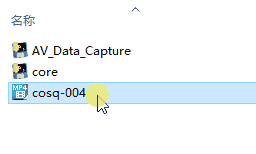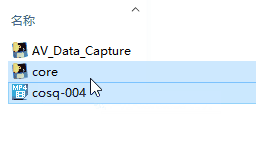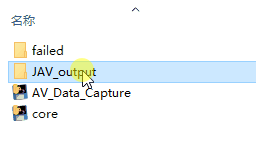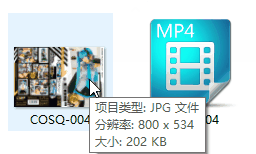<br>
|
||||
[回到目录](#目录)
|
||||
## 5.异常处理(重要)
|
||||
### 关于连接拒绝的错误
|
||||
请设置好[代理](#1针对网络审查国家或地区的代理设置)<br>
|
||||
|
||||
## 3. 关于番号提取失败或者异常
|
||||
**目前可以提取元素的影片:JAVBUS上有元数据的电影,素人系列(需要日本代理):300Maan,326scp,326urf,259luxu,siro,FC2系列**<br>
|
||||
|
||||
[回到目录](#目录)
|
||||
### 关于番号提取失败或者异常
|
||||
**目前可以提取元素的影片:JAVBUS上有元数据的电影,素人系列:300Maan,259luxu,siro等,FC2系列**<br>
|
||||
>下一张图片来自Pockies的blog:https://pockies.github.io/2019/03/25/everaver-emby-kodi/ 原作者已授权<br>
|
||||
|
||||
|
||||
@@ -73,22 +130,25 @@ COSQ-004.mp4
|
||||
```
|
||||
|
||||
文件名中间要有下划线或者减号"_","-",没有多余的内容只有番号为最佳,可以让软件更好获取元数据
|
||||
对于多影片重命名,可以用[ReNamer](http://www.den4b.com/products/renamer)来批量重命名
|
||||
对于多影片重命名,可以用[ReNamer](http://www.den4b.com/products/renamer)来批量重命名<br>
|
||||
[回到目录](#目录)
|
||||
|
||||
## 4. 把软件拷贝和AV的统一目录下
|
||||
## 5. 运行 ```AV_Data_capture.py/.exe```
|
||||
你也可以把单个影片拖动到core程序<br>
|
||||

|
||||
|
||||
## 6. 软件会自动把元数据获取成功的电影移动到JAV_output文件夹中,根据女优分类,失败的电影移动到failed文件夹中。
|
||||
## 7. 把JAV_output文件夹导入到EMBY,KODI中,根据封面选片子,享受手冲乐趣
|
||||
## 6.软件会自动把元数据获取成功的电影移动到JAV_output文件夹中,根据女优分类,失败的电影移动到failed文件夹中。
|
||||
## 7.把JAV_output文件夹导入到EMBY,KODI中,根据封面选片子,享受手冲乐趣
|
||||
cookies大神的EMBY教程:[链接](https://pockies.github.io/2019/03/25/everaver-emby-kodi/#%E5%AE%89%E8%A3%85emby%E5%B9%B6%E6%B7%BB%E5%8A%A0%E5%AA%92%E4%BD%93%E5%BA%93)<br>
|
||||
[回到目录](#目录)
|
||||
## 8.输出的文件如下
|
||||
|
||||
|
||||
|
||||
|
||||
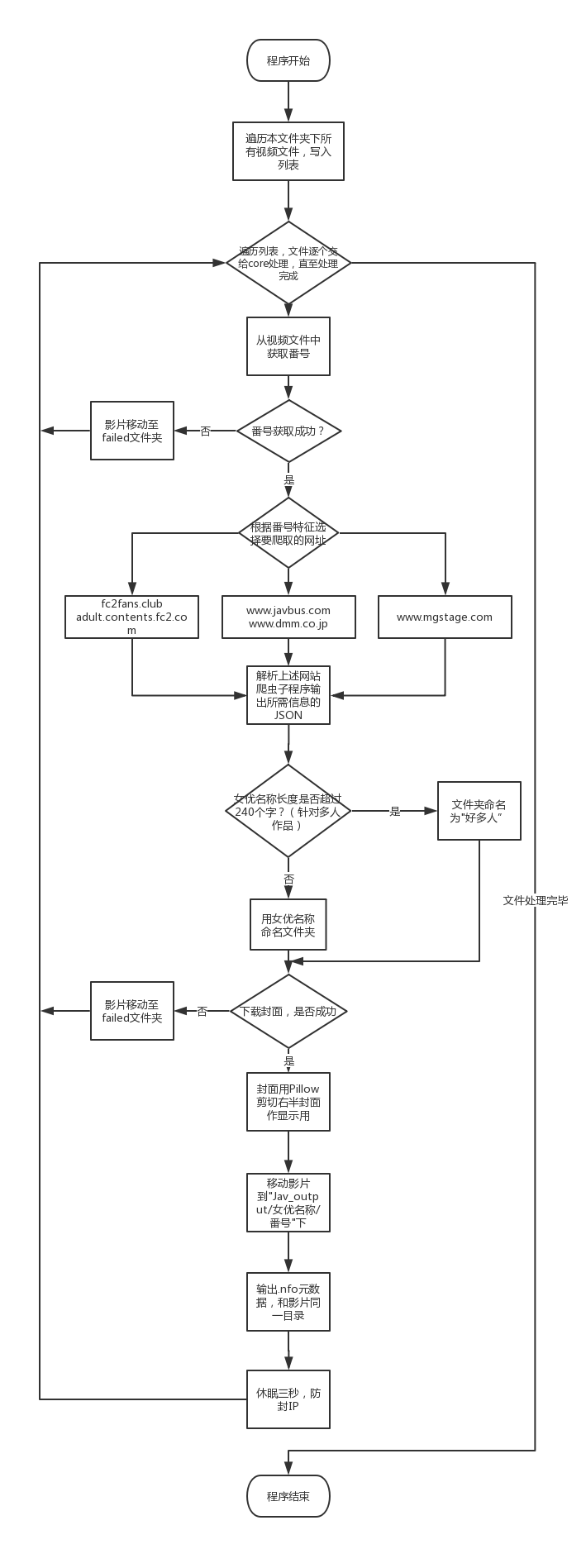
## 软件流程图
|
||||
|
||||
<br>
|
||||
[回到目录](#目录)
|
||||
## 9.写在后面
|
||||
怎么样,看着自己的AV被这样完美地管理,是不是感觉成就感爆棚呢?<br>
|
||||
[回到目录](#目录)
|
||||
## 10.软件流程图
|
||||
<br>
|
||||
[回到目录](#目录)
|
||||
|
||||
|
||||
|
||||
|
||||
92
core.py
92
core.py
@@ -55,6 +55,7 @@ def getNumberFromFilename(filepath):
|
||||
global cover
|
||||
global imagecut
|
||||
global tag
|
||||
global image_main
|
||||
|
||||
global naming_rule
|
||||
global location_rule
|
||||
@@ -76,8 +77,8 @@ def getNumberFromFilename(filepath):
|
||||
filename0 = str(re.sub(".*?\.com-\d+", "", filename1))
|
||||
file_number2 = str(re.match('\w+', filename0).group())
|
||||
file_number = str(file_number2.replace(re.match("^[A-Za-z]+", file_number2).group(),re.match("^[A-Za-z]+", file_number2).group() + '-'))
|
||||
if not re.search('\w-', file_number).group() == 'None':
|
||||
file_number = re.search('\w+-\w+', filename).group()
|
||||
#if not re.search('\w-', file_number).group() == 'None':
|
||||
#file_number = re.search('\w+-\w+', filename).group()
|
||||
#上面是插入减号-到番号中
|
||||
print("[!]Making Data for [" + filename + "],the number is [" + file_number + "]")
|
||||
# ====番号获取主程序=结束===
|
||||
@@ -107,32 +108,10 @@ def getNumberFromFilename(filepath):
|
||||
except: #添加 无需 正则表达式的规则
|
||||
# ====================fc2fans_club.py===================
|
||||
if 'fc2' in filename:
|
||||
json_data = json.loads(fc2fans_club.main(file_number.strip('fc2_').strip('fc2-')))
|
||||
json_data = json.loads(fc2fans_club.main(file_number.strip('fc2_').strip('fc2-').strip('ppv-').strip('PPV-')))
|
||||
elif 'FC2' in filename:
|
||||
json_data = json.loads(fc2fans_club.main(file_number.strip('FC2_').strip('FC2-')))
|
||||
|
||||
#========================siro.py========================
|
||||
elif 'siro' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif 'SIRO' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '259luxu' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '259LUXU' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '300MAAN' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '300maan' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '326SCP' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '326scp' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '326URF' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '326urf' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
|
||||
json_data = json.loads(fc2fans_club.main(file_number.strip('FC2_').strip('FC2-').strip('ppv-').strip('PPV-')))
|
||||
#print(file_number.strip('FC2_').strip('FC2-').strip('ppv-').strip('PPV-'))
|
||||
#=======================javbus.py=======================
|
||||
else:
|
||||
json_data = json.loads(javbus.main(file_number))
|
||||
@@ -144,19 +123,23 @@ def getNumberFromFilename(filepath):
|
||||
|
||||
|
||||
|
||||
title = json_data['title']
|
||||
studio = json_data['studio']
|
||||
year = json_data['year']
|
||||
outline = json_data['outline']
|
||||
runtime = json_data['runtime']
|
||||
director = json_data['director']
|
||||
actor_list= str(json_data['actor']).strip("[ ]").replace("'",'').replace(" ",'').split(',') #字符串转列表
|
||||
release = json_data['release']
|
||||
number = json_data['number']
|
||||
cover = json_data['cover']
|
||||
imagecut = json_data['imagecut']
|
||||
tag = str(json_data['tag']).strip("[ ]").replace("'",'').replace(" ",'').split(',') #字符串转列表
|
||||
actor = str(actor_list).strip("[ ]").replace("'",'').replace(" ",'')
|
||||
title = json_data['title']
|
||||
studio = json_data['studio']
|
||||
year = json_data['year']
|
||||
outline = json_data['outline']
|
||||
runtime = json_data['runtime']
|
||||
director = json_data['director']
|
||||
actor_list = str(json_data['actor']).strip("[ ]").replace("'",'').replace(" ",'').split(',') #字符串转列表
|
||||
release = json_data['release']
|
||||
number = json_data['number']
|
||||
cover = json_data['cover']
|
||||
imagecut = json_data['imagecut']
|
||||
tag = str(json_data['tag']).strip("[ ]").replace("'",'').replace(" ",'').split(',') #字符串转列表
|
||||
actor = str(actor_list).strip("[ ]").replace("'",'').replace(" ",'')
|
||||
|
||||
#====================处理异常字符====================== #\/:*?"<>|
|
||||
#if "\\" in title or "/" in title or ":" in title or "*" in title or "?" in title or '"' in title or '<' in title or ">" in title or "|" in title or len(title) > 200:
|
||||
# title = title.
|
||||
|
||||
naming_rule = eval(config['Name_Rule']['naming_rule'])
|
||||
location_rule =eval(config['Name_Rule']['location_rule'])
|
||||
@@ -226,13 +209,14 @@ def DownloadFileWithFilename(url,filename,path): #path = examle:photo , video.in
|
||||
print("[-]Download Failed2!")
|
||||
time.sleep(3)
|
||||
os._exit(0)
|
||||
def PrintFiles(path):
|
||||
def PrintFiles(path,naming_rule):
|
||||
global title
|
||||
try:
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
with open(path + "/" + naming_rule + ".nfo", "wt", encoding='UTF-8') as code:
|
||||
with open(path + "/" + number + ".nfo", "wt", encoding='UTF-8') as code:
|
||||
print("<movie>", file=code)
|
||||
print(" <title>" + title + "</title>", file=code)
|
||||
print(" <title>" + naming_rule + "</title>", file=code)
|
||||
print(" <set>", file=code)
|
||||
print(" </set>", file=code)
|
||||
print(" <studio>" + studio + "+</studio>", file=code)
|
||||
@@ -269,7 +253,7 @@ def PrintFiles(path):
|
||||
print(" <cover>"+cover+"</cover>", file=code)
|
||||
print(" <website>" + "https://www.javbus.com/"+number + "</website>", file=code)
|
||||
print("</movie>", file=code)
|
||||
print("[+]Writeed! "+path + "/" + naming_rule + ".nfo")
|
||||
print("[+]Writeed! "+path + "/" + number + ".nfo")
|
||||
except IOError as e:
|
||||
print("[-]Write Failed!")
|
||||
print(e)
|
||||
@@ -277,31 +261,31 @@ def PrintFiles(path):
|
||||
print(e1)
|
||||
print("[-]Write Failed!")
|
||||
def imageDownload(filepath): #封面是否下载成功,否则移动到failed
|
||||
if DownloadFileWithFilename(cover,naming_rule+ '.jpg', path) == 'failed':
|
||||
if DownloadFileWithFilename(cover,'Backdrop.jpg', path) == 'failed':
|
||||
shutil.move(filepath, 'failed/')
|
||||
os._exit(0)
|
||||
DownloadFileWithFilename(cover, naming_rule + '.jpg', path)
|
||||
print('[+]Image Downloaded!', path +'/'+naming_rule+'.jpg')
|
||||
DownloadFileWithFilename(cover, 'Backdrop.jpg', path)
|
||||
print('[+]Image Downloaded!', path +'/'+'Backdrop.jpg')
|
||||
def cutImage():
|
||||
if imagecut == 1:
|
||||
try:
|
||||
img = Image.open(path + '/' + naming_rule + '.jpg')
|
||||
img = Image.open(path + '/' + 'Backdrop' + '.jpg')
|
||||
imgSize = img.size
|
||||
w = img.width
|
||||
h = img.height
|
||||
img2 = img.crop((w / 1.9, 0, w, h))
|
||||
img2.save(path + '/' + naming_rule + '.png')
|
||||
img2.save(path + '/' + number + '.png')
|
||||
except:
|
||||
print('[-]Cover cut failed!')
|
||||
else:
|
||||
img = Image.open(path + '/' + naming_rule + '.jpg')
|
||||
img = Image.open(path + '/' + 'Backdrop' + '.jpg')
|
||||
w = img.width
|
||||
h = img.height
|
||||
img.save(path + '/' + naming_rule + '.png')
|
||||
img.save(path + '/' + number + '.png')
|
||||
def pasteFileToFolder(filepath, path): #文件路径,番号,后缀,要移动至的位置
|
||||
houzhui = str(re.search('[.](AVI|RMVB|WMV|MOV|MP4|MKV|FLV|TS|avi|rmvb|wmv|mov|mp4|mkv|flv|ts)$', filepath).group())
|
||||
os.rename(filepath, naming_rule + houzhui)
|
||||
shutil.move(naming_rule + houzhui, path)
|
||||
os.rename(filepath, number + houzhui)
|
||||
shutil.move(number + houzhui, path)
|
||||
|
||||
if __name__ == '__main__':
|
||||
filepath=argparse_get_file() #影片的路径
|
||||
@@ -309,6 +293,6 @@ if __name__ == '__main__':
|
||||
getNumberFromFilename(filepath) #定义番号
|
||||
creatFolder() #创建文件夹
|
||||
imageDownload(filepath) #creatFoder会返回番号路径
|
||||
PrintFiles(path)#打印文件
|
||||
PrintFiles(path,naming_rule)#打印文件
|
||||
cutImage() #裁剪图
|
||||
pasteFileToFolder(filepath,path) #移动文件
|
||||
|
||||
@@ -8,7 +8,16 @@ def getTitle(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h3/text()')).strip(" ['']")
|
||||
result2 = str(re.sub('\D{2}2-\d+','',result)).replace(' ','',1)
|
||||
#print(result2)
|
||||
return result2
|
||||
def getActor(htmlcode):
|
||||
try:
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h5[5]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getStudio(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h5[3]/a[1]/text()')).strip(" ['']")
|
||||
@@ -16,46 +25,60 @@ def getStudio(htmlcode): #获取厂商
|
||||
def getNum(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
#print(result)
|
||||
return result
|
||||
def getRelease(number):
|
||||
a=ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id='+str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-")+'&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html=etree.fromstring(a,etree.HTMLParser())
|
||||
def getRelease(htmlcode2): #
|
||||
#a=ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id='+str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-")+'&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html=etree.fromstring(htmlcode2,etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[2]/dl/dd[4]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getCover(htmlcode,number): #获取厂商
|
||||
a = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id=' + str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-") + '&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
def getCover(htmlcode,number,htmlcode2): #获取厂商 #
|
||||
#a = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id=' + str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-") + '&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html = etree.fromstring(htmlcode2, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[1]/a/img/@src')).strip(" ['']")
|
||||
return 'http:'+result
|
||||
def getOutline(htmlcode,number): #获取番号
|
||||
a = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id=' + str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-") + '&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
if result == '':
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result2 = str(html.xpath('//*[@id="slider"]/ul[1]/li[1]/img/@src')).strip(" ['']")
|
||||
return 'http://fc2fans.club' + result2
|
||||
return 'http:' + result
|
||||
|
||||
def getOutline(htmlcode2,number): #获取番号 #
|
||||
#a = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id=' + str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-") + '&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html = etree.fromstring(htmlcode2, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[4]/p/text()')).replace("\\n",'',10000).strip(" ['']").replace("'",'',10000)
|
||||
return result
|
||||
# def getTag(htmlcode,number): #获取番号
|
||||
# a = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id=' + str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-") + '&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
# html = etree.fromstring(a, etree.HTMLParser())
|
||||
# result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[4]/p/text()')).replace("\\n",'',10000).strip(" ['']").replace("'",'',10000)
|
||||
# return result
|
||||
def getTag(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h5[4]/a/text()'))
|
||||
return result.strip(" ['']").replace("'",'').replace(' ','')
|
||||
def getYear(release):
|
||||
try:
|
||||
result = re.search('\d{4}',release).group()
|
||||
return result
|
||||
except:
|
||||
return ''
|
||||
|
||||
def main(number2):
|
||||
number=number2.replace('PPV','').replace('ppv','')
|
||||
htmlcode2 = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id='+str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-")+'&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
htmlcode = ADC_function.get_html('http://fc2fans.club/html/FC2-' + number + '.html')
|
||||
dic = {
|
||||
'title': getTitle(htmlcode),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': str(re.search('\d{4}',getRelease(number)).group()),
|
||||
'year': '',#str(re.search('\d{4}',getRelease(number)).group()),
|
||||
'outline': getOutline(htmlcode,number),
|
||||
'runtime': '',
|
||||
'runtime': getYear(getRelease(htmlcode)),
|
||||
'director': getStudio(htmlcode),
|
||||
'actor': '',
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(number),
|
||||
'number': 'FC2-'+number,
|
||||
'cover': getCover(htmlcode,number),
|
||||
'cover': getCover(htmlcode,number,htmlcode2),
|
||||
'imagecut': 0,
|
||||
'tag':" ",
|
||||
'tag':getTag(htmlcode),
|
||||
}
|
||||
#print(getTitle(htmlcode))
|
||||
#print(getNum(htmlcode))
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
|
||||
#print(main('1104989'))
|
||||
#print(main('1051725'))
|
||||
67
javbus.py
67
javbus.py
@@ -10,11 +10,16 @@ from PIL import Image#need install
|
||||
import time
|
||||
import json
|
||||
from ADC_function import *
|
||||
import siro
|
||||
|
||||
def getTitle(htmlcode): #获取标题
|
||||
doc = pq(htmlcode)
|
||||
title=str(doc('div.container h3').text()).replace(' ','-')
|
||||
return title
|
||||
try:
|
||||
title2 = re.sub('n\d+-','',title)
|
||||
return title2
|
||||
except:
|
||||
return title
|
||||
def getStudio(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[5]/a/text()')).strip(" ['']")
|
||||
@@ -70,32 +75,13 @@ def getTag(htmlcode): # 获取演员
|
||||
|
||||
|
||||
def main(number):
|
||||
htmlcode=get_html('https://www.javbus.com/'+number)
|
||||
dww_htmlcode=get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': str(re.search('\d{4}',getYear(htmlcode)).group()),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
|
||||
if 'HEYZO' in number or 'heyzo' in number or 'Heyzo' in number:
|
||||
try:
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))),
|
||||
'title': str(re.sub('\w+-\d+-', '', getTitle(htmlcode))),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'year': str(re.search('\d{4}', getYear(htmlcode)).group()),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
@@ -105,18 +91,41 @@ def main(number):
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
}
|
||||
js2 = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js2
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
|
||||
return js
|
||||
if 'HEYZO' in number or 'heyzo' in number or 'Heyzo' in number:
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-', '', getTitle(htmlcode))),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
}
|
||||
js2 = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4,
|
||||
separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js2
|
||||
return js
|
||||
except:
|
||||
a=siro.main(number)
|
||||
return a
|
||||
|
||||
def main_uncensored(number):
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))),
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))).replace(getNum(htmlcode)+'-',''),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
@@ -136,7 +145,7 @@ def main_uncensored(number):
|
||||
number2 = number.replace('-', '_')
|
||||
htmlcode = get_html('https://www.javbus.com/' + number2)
|
||||
dic2 = {
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))),
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))).replace(getNum(htmlcode)+'-',''),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'outline': '',
|
||||
|
||||
@@ -2,5 +2,5 @@
|
||||
proxy=127.0.0.1:1080
|
||||
|
||||
[Name_Rule]
|
||||
location_rule='JAV_output/'+actor+'/'+'['+number+']-'+title
|
||||
naming_rule=number
|
||||
location_rule='JAV_output/'+actor+'/'+number
|
||||
naming_rule=number+'-'+title
|
||||
101
siro.py
101
siro.py
@@ -8,81 +8,92 @@ from ADC_function import *
|
||||
def getTitle(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="center_column"]/div[2]/h1/text()')).strip(" ['']")
|
||||
return result
|
||||
return result.replace('/',',')
|
||||
def getActor(a): #//*[@id="center_column"]/div[2]/div[1]/div/table/tbody/tr[1]/td/text()
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result2=str(html.xpath('//table/tr[1]/td[1]/text()')).strip(" ['\\n ']")
|
||||
result1 = str(html.xpath('//table/tr[1]/td[1]/a/text()')).strip(" ['\\n ']")
|
||||
return str(result1+result2).strip('+')
|
||||
result1=str(html.xpath('//th[contains(text(),"出演:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
result2=str(html.xpath('//th[contains(text(),"出演:")]/../td/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
return str(result1+result2).strip('+').replace("', '",'').replace('"','').replace('/',',')
|
||||
def getStudio(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result2=str(html.xpath('//table[2]/tr[2]/td/text()')).strip(" ['\\n ']")
|
||||
result1 = str(html.xpath('//table/tr[2]/td[1]/a/text()')).strip(" ['\\n ']")
|
||||
return str(result1+result2).strip('+')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result1=str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
result2=str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
return str(result1+result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getRuntime(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result2=str(html.xpath('//table/tr[3]/td[1]/text()')).strip(" ['\\n ']")
|
||||
result1 = str(html.xpath('//table/tr[3]/td[1]/a/text()')).strip(" ['\\n ']")
|
||||
return str(result1 + result2).strip('+').strip('mi')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"収録時間:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"収録時間:")]/../td/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
return str(result1 + result2).strip('+').rstrip('mi')
|
||||
def getLabel(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result2=str(html.xpath('//table/tr[6]/td[1]/text()')).strip(" ['\\n ']")
|
||||
result1 = str(html.xpath('//table/tr[6]/td[1]/a/text()')).strip(" ['\\n ']")
|
||||
return str(result1 + result2).strip('+')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getNum(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result2=str(html.xpath('//table/tr[2]/td[4]/a/text()')).strip(" ['\\n ']")
|
||||
result1 = str(html.xpath('//table/tr[2]/td[4]/text()')).strip(" ['\\n ']")
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"品番:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"品番:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+')
|
||||
def getYear(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result2=str(html.xpath('//table/tr[2]/td[5]/a/text()')).strip(" ['\\n ']")
|
||||
result1=str(html.xpath('//table/tr[2]/td[5]/text()')).strip(" ['\\n ']")
|
||||
return result2+result1
|
||||
def getYear(getRelease):
|
||||
try:
|
||||
result = str(re.search('\d{4}',getRelease).group())
|
||||
return result
|
||||
except:
|
||||
return getRelease
|
||||
def getRelease(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result2=str(html.xpath('//table/tr[5]/td[1]/text()')).strip(" ['\\n ']")
|
||||
result1 = str(html.xpath('//table/tr[5]/a/td[1]/text()')).strip(" ['\\n ']")
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"配信開始日:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"配信開始日:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+')
|
||||
def getTag(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result2=str(html.xpath('//table/tr[8]/td[1]/a/text()')).strip(" ['\\n ']")
|
||||
result1=str(html.xpath('//table/tr[8]/td[1]/text()')).strip(" ['\\n ']")
|
||||
return str(result1 + result2).strip('+')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"ジャンル:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"ジャンル:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+').replace("', '\\n",",").replace("', '","").replace('"','')
|
||||
def getCover(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="center_column"]/div[2]/div[1]/div/div/h2/img/@src')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result1 = str(html.xpath('//table/tr[2]/td[1]/text()')).strip(" ['\\n ']")
|
||||
result2 = str(html.xpath('//table/tr[2]/td[1]/a/text()')).strip(" ['\\n ']")
|
||||
return str(result1 + result2).strip('+')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"シリーズ")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"シリーズ")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getOutline(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="introduction"]/dd/p[1]/text()')).strip(" ['']")
|
||||
return result
|
||||
def main(number):
|
||||
htmlcode=get_html('https://www.mgstage.com/product/product_detail/'+str(number),cookies={'adc':'1'})
|
||||
def main(number2):
|
||||
number=number2.upper()
|
||||
htmlcode=get_html('https://www.mgstage.com/product/product_detail/'+str(number)+'/',cookies={'adc':'1'})
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = str(soup.find(attrs={'class': 'detail_data'})).replace('\n ','')
|
||||
#print(a)
|
||||
a = str(soup.find(attrs={'class': 'detail_data'})).replace('\n ','').replace(' ','').replace('\n ','').replace('\n ','')
|
||||
dic = {
|
||||
'title': getTitle(htmlcode).replace("\\n",'').replace(' ',''),
|
||||
'studio': getStudio(a),
|
||||
'year': str(re.search('\d{4}',getRelease(a)).group()),
|
||||
'outline': getOutline(htmlcode),
|
||||
'runtime': getRuntime(a),
|
||||
'director': getDirector(a),
|
||||
'actor': getActor(a),
|
||||
'release': getRelease(a),
|
||||
'number': number,
|
||||
'number': getNum(a),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 0,
|
||||
'tag': getTag(a).replace("'\\n',",'').replace(' ', '').replace("\\n','\\n",','),
|
||||
'label':getLabel(a)
|
||||
'tag': getTag(a),
|
||||
'label':getLabel(a),
|
||||
'year': getYear(getRelease(a)), # str(re.search('\d{4}',getRelease(a)).group()),
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
#print('https://www.mgstage.com/product/product_detail/'+str(number))
|
||||
return js
|
||||
#print(main('SIRO-3552'))
|
||||
|
||||
#print(main('200GANA-1624'))
|
||||
@@ -1,5 +1,5 @@
|
||||
{
|
||||
"version": "0.10.3",
|
||||
"version_show":"Beta 10.3",
|
||||
"version": "0.10.6",
|
||||
"version_show":"Beta 10.6",
|
||||
"download": "https://github.com/wenead99/AV_Data_Capture/releases"
|
||||
}
|
||||
|
||||
Reference in New Issue
Block a user