Compare commits
5 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
14ed221152 | ||
|
|
c41b9c1e32 | ||
|
|
17d4d68cbe | ||
|
|
b5a23fe430 | ||
|
|
2747be4a21 |
@@ -3,6 +3,20 @@ import os
|
||||
import time
|
||||
import re
|
||||
import sys
|
||||
from ADC_function import *
|
||||
import json
|
||||
|
||||
version='0.10.3'
|
||||
|
||||
def UpdateCheck():
|
||||
html2 = get_html('https://raw.githubusercontent.com/wenead99/AV_Data_Capture/master/update_check.json')
|
||||
html = json.loads(str(html2))
|
||||
|
||||
if not version == html['version']:
|
||||
print('[*] * New update '+html['version']+' *')
|
||||
print('[*] * Download *')
|
||||
print('[*] '+html['download'])
|
||||
print('[*]=====================================')
|
||||
|
||||
def movie_lists():
|
||||
#MP4
|
||||
@@ -48,6 +62,10 @@ def rreplace(self, old, new, *max):
|
||||
return new.join(self.rsplit(old, count))
|
||||
|
||||
if __name__ =='__main__':
|
||||
print('[*]===========AV Data Capture===========')
|
||||
print('[*] Version '+version)
|
||||
print('[*]=====================================')
|
||||
UpdateCheck()
|
||||
os.chdir(os.getcwd())
|
||||
for i in movie_lists(): #遍历电影列表 交给core处理
|
||||
if '_' in i:
|
||||
|
||||
14
README.md
14
README.md
@@ -1,4 +1,4 @@
|
||||
## 前言
|
||||
# 前言
|
||||
  目前,我下的AV越来越多,也意味着AV要集中地管理,形成媒体库。现在有两款主流的AV元数据获取器,"EverAver"和"Javhelper"。前者的优点是元数据获取比较全,缺点是不能批量处理;后者优点是可以批量处理,但是元数据不够全。<br>
|
||||
  为此,综合上述软件特点,我写出了本软件,为了方便的管理本地AV,和更好的手冲体验。
|
||||
|
||||
@@ -7,6 +7,16 @@
|
||||
**推荐用法: 按照 [如何使用](#如何使用) 使用该软件后,对于不能正常获取元数据的电影可以用[ Everaver ](http://everaver.blogspot.com/)来补救**<br>
|
||||
|
||||
|
||||
# 捐助二维码
|
||||
如果你觉得本软件好用,可以考虑捐助作者,你的支持就是我的动力,非常感谢您的捐助
|
||||

|
||||
|
||||
# 免责声明
|
||||
1.本软件仅供技术交流,学术交流使用<br>
|
||||
2.本软件不提供任何有关淫秽色情的影视下载方式<br>
|
||||
3.使用者使用该软件产生的一切法律后果由使用者承担<br>
|
||||
4.该软件禁止任何商用行为<br>
|
||||
|
||||
# 如何使用
|
||||
release的程序可脱离python环境运行,可跳过第一步<br>
|
||||
下载地址(仅限Windows):https://github.com/wenead99/AV_Data_Capture/releases
|
||||
@@ -61,7 +71,7 @@ pip install pillow
|
||||
>影片命名(上面目录之下的文件):'['+number+']-'+title
|
||||
|
||||
## 3. 关于番号提取失败或者异常
|
||||
**目前可以提取元素的影片:JAVBUS上有元数据的电影,素人系列(需要日本代理):300Maan,326scp,326urf,259luxu,siro,FC2系列**<br>
|
||||
**目前可以提取元素的影片:JAVBUS上有元数据的电影,素人系列(需要日本代理):300Maan,259luxu,siro等,FC2系列**<br>
|
||||
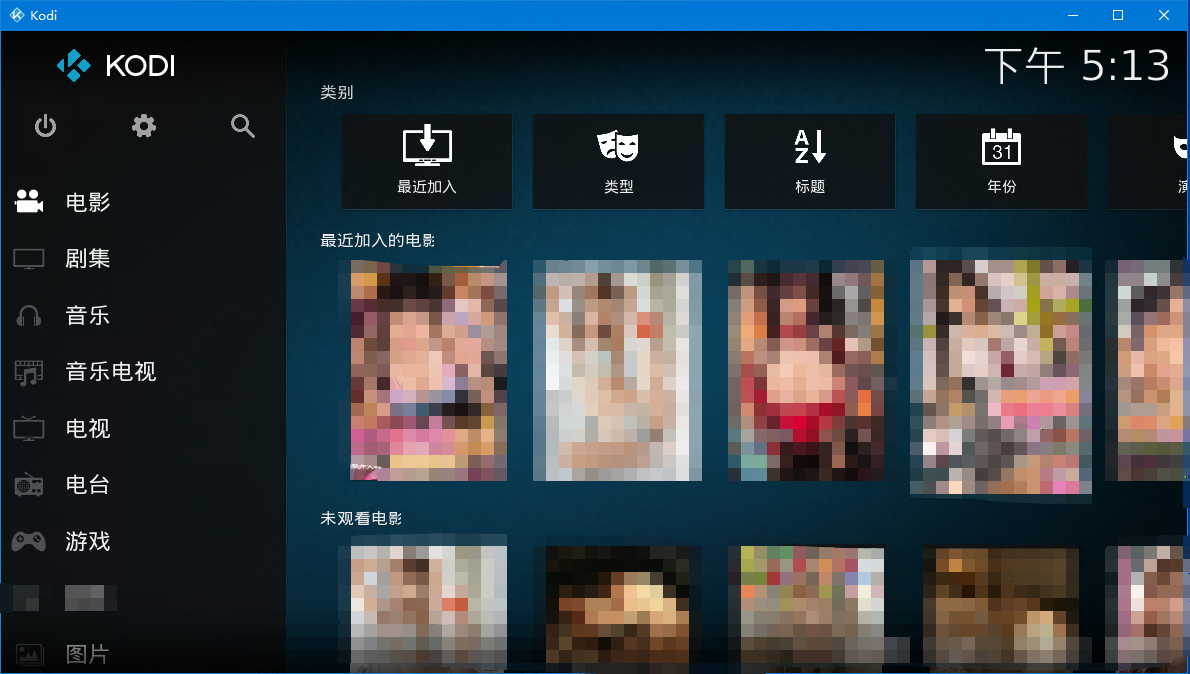
>下一张图片来自Pockies的blog:https://pockies.github.io/2019/03/25/everaver-emby-kodi/ 原作者已授权<br>
|
||||
|
||||
|
||||
|
||||
28
core.py
28
core.py
@@ -107,32 +107,10 @@ def getNumberFromFilename(filepath):
|
||||
except: #添加 无需 正则表达式的规则
|
||||
# ====================fc2fans_club.py===================
|
||||
if 'fc2' in filename:
|
||||
json_data = json.loads(fc2fans_club.main(file_number.strip('fc2_').strip('fc2-')))
|
||||
json_data = json.loads(fc2fans_club.main(file_number.strip('fc2_').strip('fc2-').strip('ppv-').strip('PPV-')))
|
||||
elif 'FC2' in filename:
|
||||
json_data = json.loads(fc2fans_club.main(file_number.strip('FC2_').strip('FC2-')))
|
||||
|
||||
#========================siro.py========================
|
||||
elif 'siro' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif 'SIRO' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '259luxu' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '259LUXU' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '300MAAN' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '300maan' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '326SCP' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '326scp' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '326URF' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
elif '326urf' in filename:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
|
||||
json_data = json.loads(fc2fans_club.main(file_number.strip('FC2_').strip('FC2-').strip('ppv-').strip('PPV-')))
|
||||
#print(file_number.strip('FC2_').strip('FC2-').strip('ppv-').strip('PPV-'))
|
||||
#=======================javbus.py=======================
|
||||
else:
|
||||
json_data = json.loads(javbus.main(file_number))
|
||||
|
||||
@@ -8,6 +8,7 @@ def getTitle(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h3/text()')).strip(" ['']")
|
||||
result2 = str(re.sub('\D{2}2-\d+','',result)).replace(' ','',1)
|
||||
#print(result2)
|
||||
return result2
|
||||
def getStudio(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
@@ -16,6 +17,7 @@ def getStudio(htmlcode): #获取厂商
|
||||
def getNum(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
#print(result)
|
||||
return result
|
||||
def getRelease(number):
|
||||
a=ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id='+str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-")+'&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
@@ -55,6 +57,8 @@ def main(number2):
|
||||
'imagecut': 0,
|
||||
'tag':" ",
|
||||
}
|
||||
#print(getTitle(htmlcode))
|
||||
#print(getNum(htmlcode))
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
|
||||
|
||||
59
javbus.py
59
javbus.py
@@ -10,6 +10,7 @@ from PIL import Image#need install
|
||||
import time
|
||||
import json
|
||||
from ADC_function import *
|
||||
import siro
|
||||
|
||||
def getTitle(htmlcode): #获取标题
|
||||
doc = pq(htmlcode)
|
||||
@@ -70,32 +71,13 @@ def getTag(htmlcode): # 获取演员
|
||||
|
||||
|
||||
def main(number):
|
||||
htmlcode=get_html('https://www.javbus.com/'+number)
|
||||
dww_htmlcode=get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': str(re.search('\d{4}',getYear(htmlcode)).group()),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
|
||||
if 'HEYZO' in number or 'heyzo' in number or 'Heyzo' in number:
|
||||
try:
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))),
|
||||
'title': str(re.sub('\w+-\d+-', '', getTitle(htmlcode))),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'year': str(re.search('\d{4}', getYear(htmlcode)).group()),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
@@ -105,12 +87,35 @@ def main(number):
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
}
|
||||
js2 = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js2
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
|
||||
return js
|
||||
if 'HEYZO' in number or 'heyzo' in number or 'Heyzo' in number:
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-', '', getTitle(htmlcode))),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
}
|
||||
js2 = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4,
|
||||
separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js2
|
||||
return js
|
||||
except:
|
||||
a=siro.main(number)
|
||||
return a
|
||||
|
||||
def main_uncensored(number):
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
@@ -155,6 +160,8 @@ def main_uncensored(number):
|
||||
|
||||
return js
|
||||
|
||||
#print(main('SIRO-3821'))
|
||||
|
||||
|
||||
# def return1():
|
||||
# json_data=json.loads(main('ipx-292'))
|
||||
|
||||
Reference in New Issue
Block a user