Compare commits
20 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
cfccd00367 | ||
|
|
56801d3910 | ||
|
|
2d1efe272e | ||
|
|
ff7ed13419 | ||
|
|
7fade0fee3 | ||
|
|
2dc2da4b41 | ||
|
|
79679adbac | ||
|
|
637ae06a14 | ||
|
|
917614975e | ||
|
|
e3d9955e5b | ||
|
|
69fa8d3f05 | ||
|
|
b5f82f77a1 | ||
|
|
5f627d24e0 | ||
|
|
6817cd2093 | ||
|
|
bda0c5becd | ||
|
|
abcf1a49e7 | ||
|
|
23de02486c | ||
|
|
8046fa1ef6 | ||
|
|
0a6af7c41b | ||
|
|
08cdabb59d |
10
ADC_function.py
Normal file
10
ADC_function.py
Normal file
@@ -0,0 +1,10 @@
|
||||
import requests
|
||||
|
||||
def get_html(url):#网页请求核心
|
||||
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
|
||||
getweb = requests.get(str(url),timeout=5,headers=headers)
|
||||
getweb.encoding='utf-8'
|
||||
try:
|
||||
return getweb.text
|
||||
except:
|
||||
print("[-]Connect Failed! Please check your Proxy.")
|
||||
@@ -1,39 +1,60 @@
|
||||
import glob
|
||||
import os
|
||||
import time
|
||||
import re
|
||||
|
||||
def movie_lists():
|
||||
#MP4
|
||||
a1 = glob.glob(os.getcwd() + r"\*\**\*.mp4")
|
||||
a2 = glob.glob(os.getcwd() + r"\*.mp4")
|
||||
# AVI
|
||||
b1 = glob.glob(os.getcwd() + r"\*\**\*.avi")
|
||||
b2 = glob.glob(os.getcwd() + r"\*.avi")
|
||||
# RMVB
|
||||
c1 = glob.glob(os.getcwd() + r"\*\**\*.rmvb")
|
||||
c2 = glob.glob(os.getcwd() + r"\*.rmvb")
|
||||
# WMV
|
||||
d1 = glob.glob(os.getcwd() + r"\*\**\*.wmv")
|
||||
d2 = glob.glob(os.getcwd() + r"\*.wmv")
|
||||
# MOV
|
||||
e1 = glob.glob(os.getcwd() + r"\*\**\*.mov")
|
||||
e2 = glob.glob(os.getcwd() + r"\*.mov")
|
||||
# MKV
|
||||
f1 = glob.glob(os.getcwd() + r"\*\**\*.mkv")
|
||||
f2 = glob.glob(os.getcwd() + r"\*.mkv")
|
||||
# FLV
|
||||
g1 = glob.glob(os.getcwd() + r"\*\**\*.flv")
|
||||
g2 = glob.glob(os.getcwd() + r"\*.flv")
|
||||
|
||||
total = a1+a2+b1+b2+c1+c2+d1+d2+e1+e2+f1+f2+g1+g2
|
||||
total = a2+b2+c2+d2+e2+f2+g2
|
||||
return total
|
||||
|
||||
def lists_from_test(custom_nuber):
|
||||
def lists_from_test(custom_nuber): #电影列表
|
||||
|
||||
a=[]
|
||||
a.append(custom_nuber)
|
||||
return a
|
||||
|
||||
os.chdir(os.getcwd())
|
||||
for i in movie_lists():
|
||||
os.system('python core.py'+' "'+i+'"')
|
||||
print("[+]All finished!!!")
|
||||
def CEF(path):
|
||||
files = os.listdir(path) # 获取路径下的子文件(夹)列表
|
||||
for file in files:
|
||||
try: #试图删除空目录,非空目录删除会报错
|
||||
os.removedirs(path + '/' + file) # 删除这个空文件夹
|
||||
print('[+]Deleting empty folder',path + '/' + file)
|
||||
except:
|
||||
a=''
|
||||
|
||||
def rreplace(self, old, new, *max):
|
||||
#从右开始替换文件名中内容,源字符串,将被替换的子字符串, 新字符串,用于替换old子字符串,可选字符串, 替换不超过 max 次
|
||||
count = len(self)
|
||||
if max and str(max[0]).isdigit():
|
||||
count = max[0]
|
||||
return new.join(self.rsplit(old, count))
|
||||
|
||||
if __name__ =='__main__':
|
||||
os.chdir(os.getcwd())
|
||||
for i in movie_lists(): #遍历电影列表 交给core处理
|
||||
if '_' in i:
|
||||
os.rename(re.search(r'[^\\/:*?"<>|\r\n]+$', i).group(), rreplace(re.search(r'[^\\/:*?"<>|\r\n]+$', i).group(), '_', '-', 1))
|
||||
i = rreplace(re.search(r'[^\\/:*?"<>|\r\n]+$', i).group(), '_', '-', 1)
|
||||
os.system('python core.py' + ' "' + i + '"') #选择从py文件启动 (用于源码py)
|
||||
#os.system('core.exe' + ' "' + i + '"') #选择从exe文件启动(用于EXE版程序)
|
||||
print("[*]=====================================")
|
||||
|
||||
print("[!]Cleaning empty folders")
|
||||
CEF('JAV_output')
|
||||
print("[+]All finished!!!")
|
||||
time.sleep(3)
|
||||
37
README.md
37
README.md
@@ -2,23 +2,28 @@
|
||||
|
||||
## 关于本软件 (~路star谢谢)
|
||||
|
||||
**#0.5重大更新:新增对FC2,259LUXU,SIRO,300MAAN系列影片抓取支持,优化对无码视频抓取**
|
||||
|
||||
目前,我下的AV越来越多,也意味着AV要集中地管理,形成媒体库。现在有两款主流的AV元数据获取器,"EverAver"和"Javhelper"。前者的优点是元数据获取比较全,缺点是不能批量处理;后者优点是可以批量处理,但是元数据不够全。
|
||||
|
||||
为此,综合上述软件特点,我写出了本软件,为了方便的管理本地AV,和更好的手冲体验。没女朋友怎么办ʅ(‾◡◝)ʃ
|
||||
|
||||
**预计本周末适配DS Video,暂时只支持Kodi,EMBY**
|
||||
|
||||
**tg官方电报群:https://t.me/AV_Data_Capture_Official**
|
||||
|
||||
### **请认真阅读下面使用说明再使用**
|
||||
### **请认真阅读下面使用说明再使用** * [如何使用](#如何使用)
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
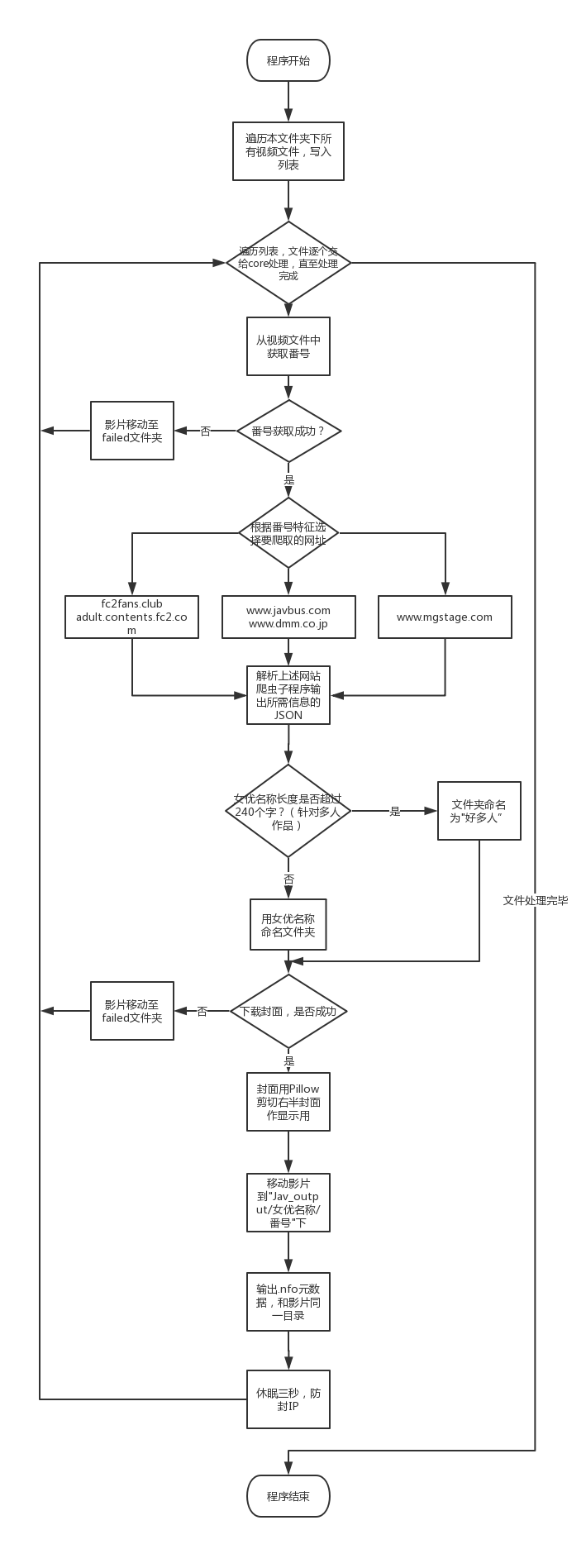
## 软件流程图 (下下一个为使用教程)
|
||||

|
||||
## 软件流程图
|
||||
|
||||
|
||||
## 如何使用 (使用前请认真阅读下文)
|
||||
**release的程序可脱离python环境运行,可跳过第一步(仅限windows平台)**
|
||||
**下载地址(Windows):https://github.com/wenead99/AV_Data_Capture/releases**
|
||||
## 如何使用
|
||||
### **请认真阅读下面使用说明**
|
||||
**release的程序可脱离python环境运行,可跳过第一步(仅限windows平台)**
|
||||
**下载地址(Windows):https://github.com/wenead99/AV_Data_Capture/releases**
|
||||
1. 请安装requests,pyquery,lxml,Beautifulsoup4,pillow模块,可在CMD逐条输入以下命令安装
|
||||
```python
|
||||
pip install requests
|
||||
@@ -44,23 +49,29 @@ pip install pillow
|
||||
```
|
||||
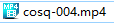
COSQ-004.mp4
|
||||
```
|
||||
文件名中间要有减号"-",没有多余的内容只有番号为最佳,可以让软件更好获取元数据
|
||||
或者
|
||||
```
|
||||
COSQ_004.mp4
|
||||
```
|
||||
文件名中间要有下划线或者减号"_","-",没有多余的内容只有番号为最佳,可以让软件更好获取元数据
|
||||
对于多影片重命名,可以用ReNamer来批量重命名
|
||||
软件官网:http://www.den4b.com/products/renamer
|
||||
|
||||

|
||||
|
||||
|
||||
3. 把软件拷贝到AV的所在目录下,运行程序(中国大陆用户必须挂VPN,Shsadowsocks开全局代理)
|
||||
4. 运行AV_Data_capture.py
|
||||
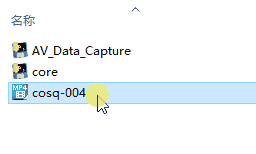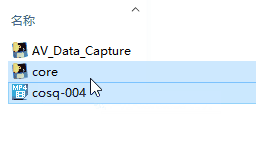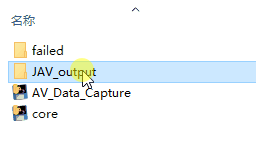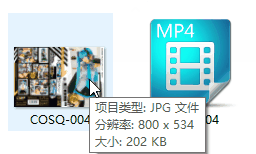
5. **你也可以把单个影片拖动到core程序**
|
||||
|
||||

|
||||
|
||||
|
||||
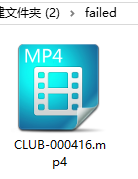
6. 软件会自动把元数据获取成功的电影移动到JAV_output文件夹中,根据女优分类,失败的电影移动到failed文件夹中。
|
||||
|
||||

|
||||

|
||||

|
||||
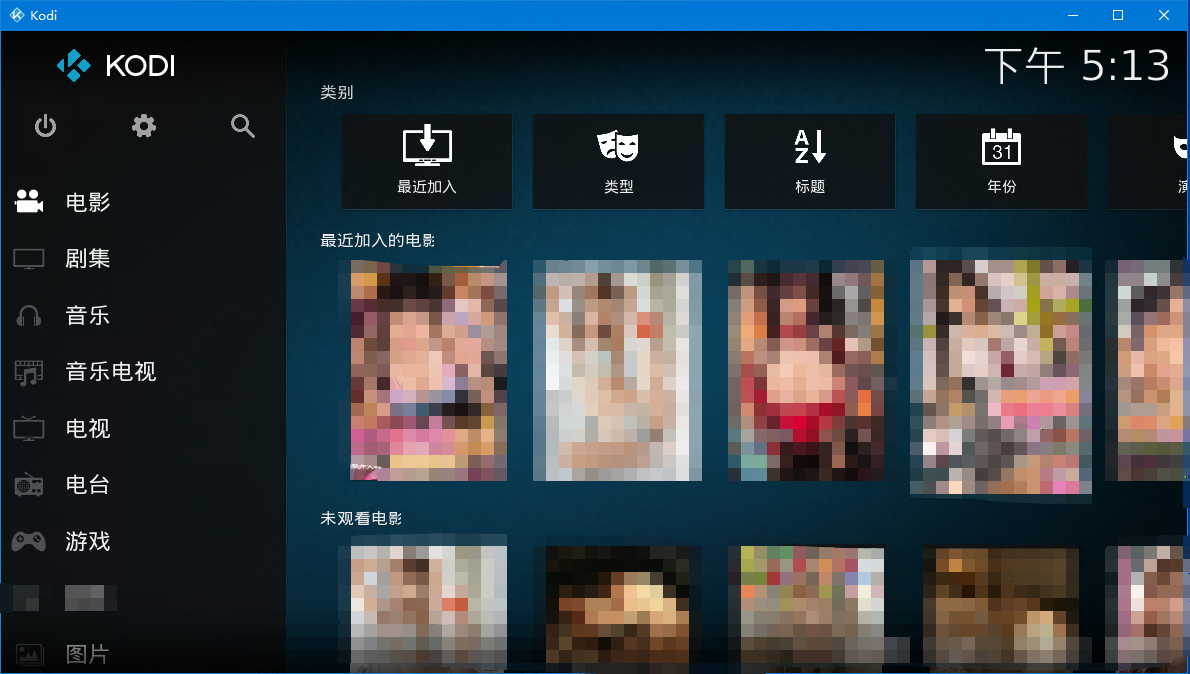
7. 把JAV_output文件夹导入到EMBY,KODI中,根据封面选片子,享受手冲乐趣
|
||||
|
||||
|
||||
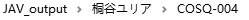
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
294
core.py
294
core.py
@@ -1,202 +1,202 @@
|
||||
import re
|
||||
import requests #need install
|
||||
from pyquery import PyQuery as pq#need install
|
||||
from lxml import etree#need install
|
||||
import os
|
||||
import os.path
|
||||
import shutil
|
||||
from bs4 import BeautifulSoup#need install
|
||||
from PIL import Image#need install
|
||||
from PIL import Image
|
||||
import time
|
||||
import javbus
|
||||
import json
|
||||
import fc2fans_club
|
||||
import siro
|
||||
|
||||
def get_html(url):
|
||||
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
|
||||
getweb = requests.get(str(url),proxies={"http": "http://127.0.0.1:2334","https": "https://127.0.0.1:2334"},timeout=5,headers=headers).text
|
||||
try:
|
||||
return getweb
|
||||
except Exception as e:
|
||||
print(e)
|
||||
except IOError as e1:
|
||||
print(e1)
|
||||
#================================================
|
||||
def getTitle(htmlcode):
|
||||
doc = pq(htmlcode)
|
||||
title=str(doc('div.container h3').text()).replace(' ','-')
|
||||
return title
|
||||
def getStudio(htmlcode):
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[5]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getYear(htmlcode):
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
result2 = str(re.search('\d{4}', result).group(0))
|
||||
return result2
|
||||
def getCover(htmlcode):
|
||||
doc = pq(htmlcode)
|
||||
image = doc('a.bigImage')
|
||||
return image.attr('href')
|
||||
print(image.attr('href'))
|
||||
def getRelease(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getRuntime(htmlcode):
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find(text=re.compile('分鐘'))
|
||||
return a
|
||||
def getActor(htmlcode):
|
||||
b=[]
|
||||
soup=BeautifulSoup(htmlcode,'lxml')
|
||||
a=soup.find_all(attrs={'class':'star-name'})
|
||||
for i in a:
|
||||
b.append(i.text)
|
||||
return ",".join(b)
|
||||
def getNum(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[4]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getOutline(htmlcode):
|
||||
doc = pq(htmlcode)
|
||||
result = str(doc('tr td div.mg-b20.lh4 p.mg-b20').text())
|
||||
return result
|
||||
#================================================
|
||||
#初始化全局变量
|
||||
title=''
|
||||
studio=''
|
||||
year=''
|
||||
outline=''
|
||||
runtime=''
|
||||
director=''
|
||||
actor=''
|
||||
release=''
|
||||
number=''
|
||||
cover=''
|
||||
imagecut=''
|
||||
|
||||
#=====================资源下载部分===========================
|
||||
def DownloadFileWithFilename(url,filename,path): #path = examle:photo , video.in the Project Folder!
|
||||
import requests
|
||||
import re
|
||||
try:
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
r = requests.get(url)
|
||||
with open(str(path) + "/"+str(filename), "wb") as code:
|
||||
code.write(r.content)
|
||||
# print('[+]Downloaded!',str(path) + "/"+str(filename))
|
||||
except IOError as e:
|
||||
print("[-]Download Failed1!")
|
||||
print("[-]Movie not found in Javbus.com!")
|
||||
print("[*]=====================================")
|
||||
print("[-]Movie not found in All website!")
|
||||
#print("[*]=====================================")
|
||||
return "failed"
|
||||
except Exception as e1:
|
||||
print(e1)
|
||||
print("[-]Download Failed2!")
|
||||
time.sleep(3)
|
||||
os._exit(0)
|
||||
|
||||
def PrintFiles(path):
|
||||
try:
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
with open(path + "/" + getNum(html) + ".nfo", "wt", encoding='UTF-8') as code:
|
||||
with open(path + "/" + number + ".nfo", "wt", encoding='UTF-8') as code:
|
||||
print("<movie>", file=code)
|
||||
print(" <title>" + getTitle(html) + "</title>", file=code)
|
||||
print(" <title>" + title + "</title>", file=code)
|
||||
print(" <set>", file=code)
|
||||
print(" </set>", file=code)
|
||||
print(" <studio>" + getStudio(html) + "+</studio>", file=code)
|
||||
print(" <year>" + getYear(html) + "</year>", file=code)
|
||||
print(" <outline>"+getOutline(html_outline)+"</outline>", file=code)
|
||||
print(" <plot>"+getOutline(html_outline)+"</plot>", file=code)
|
||||
print(" <runtime>"+str(getRuntime(html)).replace(" ","")+"</runtime>", file=code)
|
||||
print(" <director>" + getDirector(html) + "</director>", file=code)
|
||||
print(" <poster>" + getNum(html) + ".png</poster>", file=code)
|
||||
print(" <thumb>" + getNum(html) + ".png</thumb>", file=code)
|
||||
print(" <fanart>"+getNum(html) + '.jpg'+"</fanart>", file=code)
|
||||
print(" <studio>" + studio + "+</studio>", file=code)
|
||||
print(" <year>" + year + "</year>", file=code)
|
||||
print(" <outline>"+outline+"</outline>", file=code)
|
||||
print(" <plot>"+outline+"</plot>", file=code)
|
||||
print(" <runtime>"+str(runtime).replace(" ","")+"</runtime>", file=code)
|
||||
print(" <director>" + director + "</director>", file=code)
|
||||
print(" <poster>" + number + ".png</poster>", file=code)
|
||||
print(" <thumb>" + number + ".png</thumb>", file=code)
|
||||
print(" <fanart>"+number + '.jpg'+"</fanart>", file=code)
|
||||
print(" <actor>", file=code)
|
||||
print(" <name>" + getActor(html) + "</name>", file=code)
|
||||
print(" <name>" + actor + "</name>", file=code)
|
||||
print(" </actor>", file=code)
|
||||
print(" <maker>" + getStudio(html) + "</maker>", file=code)
|
||||
print(" <maker>" + studio + "</maker>", file=code)
|
||||
print(" <label>", file=code)
|
||||
print(" </label>", file=code)
|
||||
print(" <num>" + getNum(html) + "</num>", file=code)
|
||||
print(" <release>" + getRelease(html) + "</release>", file=code)
|
||||
print(" <cover>"+getCover(html)+"</cover>", file=code)
|
||||
print(" <website>" + "https://www.javbus.com/"+getNum(html) + "</website>", file=code)
|
||||
print(" <num>" + number + "</num>", file=code)
|
||||
print(" <release>" + release + "</release>", file=code)
|
||||
print(" <cover>"+cover+"</cover>", file=code)
|
||||
print(" <website>" + "https://www.javbus.com/"+number + "</website>", file=code)
|
||||
print("</movie>", file=code)
|
||||
print("[+]Writeed! "+path + "/" + getNum(html) + ".nfo")
|
||||
print("[+]Writeed! "+path + "/" + number + ".nfo")
|
||||
except IOError as e:
|
||||
print("[-]Write Failed!")
|
||||
print(e)
|
||||
except Exception as e1:
|
||||
print(e1)
|
||||
print("[-]Write Failed!")
|
||||
#================================================
|
||||
if __name__ == '__main__':
|
||||
#命令行处理
|
||||
|
||||
#=====================本地文件处理===========================
|
||||
def argparse_get_file():
|
||||
import argparse
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("file", help="Write the file path on here")
|
||||
args = parser.parse_args()
|
||||
#===============================
|
||||
#获取文件名称
|
||||
filename=str(os.path.basename(args.file)) #\[\d{4}(\-|\/|.)\d{1,2}\1\d{1,2}\]
|
||||
#去除文件名中日期
|
||||
deldate=str(re.sub("\[\d{4}-\d{1,2}-\d{1,2}\] - ","",filename))
|
||||
return args.file
|
||||
def getNumberFromFilename(filepath):
|
||||
global title
|
||||
global studio
|
||||
global year
|
||||
global outline
|
||||
global runtime
|
||||
global director
|
||||
global actor
|
||||
global release
|
||||
global number
|
||||
global cover
|
||||
global imagecut
|
||||
|
||||
#检测是否可以获取番号,如果不行终止本程序
|
||||
def number_getter():
|
||||
print("[!]Making Data for ["+filename+"]")
|
||||
filename = str(os.path.basename(filepath)) #电影文件名
|
||||
str(re.sub("\[\d{4}-\d{1,2}-\d{1,2}\] - ", "", filename))
|
||||
print("[!]Making Data for ["+filename+"]")
|
||||
a = str(re.search('\w+-\w+', filename).group())
|
||||
#print(a)
|
||||
|
||||
# =======================网站规则添加==============================
|
||||
try:
|
||||
try:
|
||||
a = str(re.search('\w+-\w+', deldate).group())
|
||||
return a
|
||||
if re.search('^\d{5,}', a).group() in filename:
|
||||
json_data = json.loads(javbus.main_uncensored(a.replace("-", "_")))
|
||||
except:
|
||||
print('[-]File '+filename+'`s number can not be caught')
|
||||
print('[-]Move ' + filename + 'to failed folder')
|
||||
filepath = str(args).replace("Namespace(file='", '').replace("')", '').replace('\\\\', '\\')
|
||||
if not os.path.exists('failed/'): # 新建failed文件夹
|
||||
os.makedirs('failed/')
|
||||
if not os.path.exists('failed/'):
|
||||
print("[-]failed!Dirs can not be make (Please run as Administrator)")
|
||||
time.sleep(3)
|
||||
os._exit(0)
|
||||
shutil.move(filepath, str(os.getcwd())+'/failed/')
|
||||
os._exit(0)
|
||||
number=number_getter()
|
||||
#print(number)
|
||||
#获取网页HTML
|
||||
html = get_html("https://www.javbus.com/"+str(number))
|
||||
html_outline=get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid="+number.replace("-",''))
|
||||
#处理超长文件夹名称
|
||||
if len(getActor(html)) > 240:
|
||||
path = 'JAV_output' + '/' + '超多人' + '/' + getNum(html) #path为影片+元数据所在目录
|
||||
else:
|
||||
path = 'JAV_output' + '/' + getActor(html) + '/' + getNum(html)
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
#文件路径处理
|
||||
filepath = str(args).replace("Namespace(file='",'').replace("')",'').replace('\\\\', '\\')
|
||||
houzhui = str(re.search('[.](AVI|RMVB|WMV|MOV|MP4|MKV|FLV|avi|rmvb|wmv|mov|mp4|mkv|flv)$',filepath).group())
|
||||
#下载元数据
|
||||
if 'fc2' in filename:
|
||||
json_data = json.loads(fc2fans_club.main(a))
|
||||
elif 'FC2' in filename:
|
||||
json_data = json.loads(fc2fans_club.main(a))
|
||||
elif 'siro' in filename:
|
||||
json_data = json.loads(siro.main(a))
|
||||
elif 'SIRO' in filename:
|
||||
json_data = json.loads(siro.main(a))
|
||||
elif '259luxu' in filename:
|
||||
json_data = json.loads(siro.main(a))
|
||||
elif '259LUXU' in filename:
|
||||
json_data = json.loads(siro.main(a))
|
||||
else:
|
||||
json_data = json.loads(javbus.main(a))
|
||||
# ====================网站规则添加结束==============================
|
||||
|
||||
#如果DownloadFileWithFilename返回为failed,就退出本程序
|
||||
title = json_data['title']
|
||||
studio = json_data['studio']
|
||||
year = json_data['year']
|
||||
outline = json_data['outline']
|
||||
runtime = json_data['runtime']
|
||||
director = json_data['director']
|
||||
actor = json_data['actor']
|
||||
release = json_data['release']
|
||||
number = json_data['number']
|
||||
cover = json_data['cover']
|
||||
imagecut = json_data['imagecut']
|
||||
except:
|
||||
print('[-]File '+filename+'`s number can not be caught')
|
||||
print('[-]Move ' + filename + ' to failed folder')
|
||||
if not os.path.exists('failed/'): # 新建failed文件夹
|
||||
os.makedirs('failed/')
|
||||
if not os.path.exists('failed/'):
|
||||
print("[-]failed!Dirs can not be make (Please run as Administrator)")
|
||||
time.sleep(3)
|
||||
os._exit(0)
|
||||
shutil.move(filepath, str(os.getcwd())+'/'+'failed/')
|
||||
os._exit(0)
|
||||
|
||||
path = '' #设置path为全局变量,后面移动文件要用
|
||||
|
||||
def creatFolder():
|
||||
global path
|
||||
if not os.path.exists('failed/'): #新建failed文件夹
|
||||
os.makedirs('failed/')
|
||||
if not os.path.exists('failed/'):
|
||||
print("[-]failed!Dirs can not be make (Please run as Administrator)")
|
||||
os._exit(0)
|
||||
if DownloadFileWithFilename(getCover(html), getNum(html) + '.jpg', path) == 'failed':
|
||||
shutil.move(filepath, 'failed/')
|
||||
time.sleep(3)
|
||||
os._exit(0)
|
||||
if len(actor) > 240: #新建成功输出文件夹
|
||||
path = 'JAV_output' + '/' + '超多人' + '/' + number #path为影片+元数据所在目录
|
||||
else:
|
||||
if DownloadFileWithFilename(getCover(html), getNum(html) + '.jpg', path) == 'failed':
|
||||
shutil.move(filepath, 'failed/')
|
||||
os._exit(0)
|
||||
DownloadFileWithFilename(getCover(html), getNum(html) + '.jpg', path)
|
||||
print('[+]Downloaded!', path +'/'+getNum(html)+'.jpg')
|
||||
#切割图片做封面
|
||||
try:
|
||||
img = Image.open(path + '/' + getNum(html) + '.jpg')
|
||||
img2 = img.crop((421, 0, 800, 538))
|
||||
img2.save(path + '/' + getNum(html) + '.png')
|
||||
except:
|
||||
print('[-]Cover cut failed!')
|
||||
# 电源文件位置处理
|
||||
path = 'JAV_output' + '/' + str(actor) + '/' + str(number)
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
path = str(os.getcwd())+'/'+path
|
||||
def imageDownload(filepath): #封面是否下载成功,否则移动到failed
|
||||
if DownloadFileWithFilename(cover,str(number) + '.jpg', path) == 'failed':
|
||||
shutil.move(filepath, 'failed/')
|
||||
os._exit(0)
|
||||
DownloadFileWithFilename(cover, number + '.jpg', path)
|
||||
print('[+]Image Downloaded!', path +'/'+number+'.jpg')
|
||||
def cutImage():
|
||||
if imagecut == 1:
|
||||
try:
|
||||
img = Image.open(path + '/' + number + '.jpg')
|
||||
imgSize = img.size
|
||||
w = img.width
|
||||
h = img.height
|
||||
img2 = img.crop((w / 1.9, 0, w, h))
|
||||
img2.save(path + '/' + number + '.png')
|
||||
except:
|
||||
print('[-]Cover cut failed!')
|
||||
else:
|
||||
img = Image.open(path + '/' + number + '.jpg')
|
||||
w = img.width
|
||||
h = img.height
|
||||
img.save(path + '/' + number + '.png')
|
||||
|
||||
def pasteFileToFolder(filepath, path): #文件路径,番号,后缀,要移动至的位置
|
||||
houzhui = str(re.search('[.](AVI|RMVB|WMV|MOV|MP4|MKV|FLV|avi|rmvb|wmv|mov|mp4|mkv|flv)$', filepath).group())
|
||||
os.rename(filepath, number + houzhui)
|
||||
shutil.move(number + houzhui, path)
|
||||
#下载元数据
|
||||
PrintFiles(path)
|
||||
print('[!]Finished!')
|
||||
time.sleep(3)
|
||||
|
||||
if __name__ == '__main__':
|
||||
filepath=argparse_get_file() #影片的路径
|
||||
getNumberFromFilename(filepath) #定义番号
|
||||
creatFolder() #创建文件夹
|
||||
imageDownload(filepath) #creatFoder会返回番号路径
|
||||
PrintFiles(path)#打印文件
|
||||
cutImage() #裁剪图
|
||||
pasteFileToFolder(filepath,path) #移动文件
|
||||
|
||||
52
fc2fans_club.py
Normal file
52
fc2fans_club.py
Normal file
@@ -0,0 +1,52 @@
|
||||
import re
|
||||
from lxml import etree#need install
|
||||
import json
|
||||
import ADC_function
|
||||
|
||||
def getTitle(htmlcode): #获取厂商
|
||||
#print(htmlcode)
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h3/text()')).strip(" ['']")
|
||||
return result
|
||||
def getStudio(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h5[3]/a[1]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getNum(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getRelease(number):
|
||||
a=ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id='+str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-")+'&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html=etree.fromstring(a,etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[2]/dl/dd[4]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getCover(htmlcode,number): #获取厂商
|
||||
a = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id=' + str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-") + '&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[1]/a/img/@src')).strip(" ['']")
|
||||
return 'http:'+result
|
||||
def getOutline(htmlcode,number): #获取番号
|
||||
a = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id=' + str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-") + '&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[4]/p/text()')).replace("\\n",'',10000).strip(" ['']").replace("'",'',10000)
|
||||
return result
|
||||
|
||||
def main(number):
|
||||
str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-")
|
||||
htmlcode = ADC_function.get_html('http://fc2fans.club/html/FC2-' + number + '.html')
|
||||
dic = {
|
||||
'title': getTitle(htmlcode),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getRelease(number),
|
||||
'outline': getOutline(htmlcode,number),
|
||||
'runtime': '',
|
||||
'director': getStudio(htmlcode),
|
||||
'actor': '',
|
||||
'release': getRelease(number),
|
||||
'number': number,
|
||||
'cover': getCover(htmlcode,number),
|
||||
'imagecut': 0,
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
129
javbus.py
Normal file
129
javbus.py
Normal file
@@ -0,0 +1,129 @@
|
||||
import re
|
||||
import requests #need install
|
||||
from pyquery import PyQuery as pq#need install
|
||||
from lxml import etree#need install
|
||||
import os
|
||||
import os.path
|
||||
import shutil
|
||||
from bs4 import BeautifulSoup#need install
|
||||
from PIL import Image#need install
|
||||
import time
|
||||
import json
|
||||
|
||||
def get_html(url):#网页请求核心
|
||||
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
|
||||
getweb = requests.get(str(url),timeout=5,headers=headers).text
|
||||
try:
|
||||
return getweb
|
||||
except:
|
||||
print("[-]Connect Failed! Please check your Proxy.")
|
||||
|
||||
def getTitle(htmlcode): #获取标题
|
||||
doc = pq(htmlcode)
|
||||
title=str(doc('div.container h3').text()).replace(' ','-')
|
||||
return title
|
||||
def getStudio(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[5]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getYear(htmlcode): #获取年份
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
result2 = str(re.search('\d{4}', result).group(0))
|
||||
return result2
|
||||
def getCover(htmlcode): #获取封面链接
|
||||
doc = pq(htmlcode)
|
||||
image = doc('a.bigImage')
|
||||
return image.attr('href')
|
||||
print(image.attr('href'))
|
||||
def getRelease(htmlcode): #获取出版日期
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getRuntime(htmlcode): #获取分钟
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find(text=re.compile('分鐘'))
|
||||
return a
|
||||
def getActor(htmlcode): #获取女优
|
||||
b=[]
|
||||
soup=BeautifulSoup(htmlcode,'lxml')
|
||||
a=soup.find_all(attrs={'class':'star-name'})
|
||||
for i in a:
|
||||
b.append(i.text)
|
||||
return ",".join(b)
|
||||
def getNum(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(htmlcode): #获取导演
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[4]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getOutline(htmlcode): #获取演员
|
||||
doc = pq(htmlcode)
|
||||
result = str(doc('tr td div.mg-b20.lh4 p.mg-b20').text())
|
||||
return result
|
||||
|
||||
def main(number):
|
||||
htmlcode=get_html('https://www.javbus.com/'+number)
|
||||
dww_htmlcode=get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': getTitle(htmlcode),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
|
||||
def main_uncensored(number):
|
||||
htmlcode=get_html('https://www.javbus.com/'+number)
|
||||
dww_htmlcode=get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': getTitle(htmlcode),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 0,
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
|
||||
# def return1():
|
||||
# json_data=json.loads(main('ipx-292'))
|
||||
#
|
||||
# title = str(json_data['title'])
|
||||
# studio = str(json_data['studio'])
|
||||
# year = str(json_data['year'])
|
||||
# outline = str(json_data['outline'])
|
||||
# runtime = str(json_data['runtime'])
|
||||
# director = str(json_data['director'])
|
||||
# actor = str(json_data['actor'])
|
||||
# release = str(json_data['release'])
|
||||
# number = str(json_data['number'])
|
||||
# cover = str(json_data['cover'])
|
||||
#
|
||||
# # print(title)
|
||||
# # print(studio)
|
||||
# # print(year)
|
||||
# # print(outline)
|
||||
# # print(runtime)
|
||||
# # print(director)
|
||||
# # print(actor)
|
||||
# # print(release)
|
||||
# # print(number)
|
||||
# # print(cover)
|
||||
# return1()
|
||||
2
py to exe.bat
Normal file
2
py to exe.bat
Normal file
@@ -0,0 +1,2 @@
|
||||
pyinstaller --onefile AV_Data_Capture.py
|
||||
pyinstaller --onefile core.py --hidden-import ADC_function.py --hidden-import fc2fans_club.py --hidden-import javbus.py --hidden-import siro.py
|
||||
76
siro.py
Normal file
76
siro.py
Normal file
@@ -0,0 +1,76 @@
|
||||
import re
|
||||
from lxml import etree
|
||||
import json
|
||||
import requests
|
||||
from bs4 import BeautifulSoup
|
||||
|
||||
def get_html(url):#网页请求核心
|
||||
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
|
||||
cookies = {'adc':'1'}
|
||||
getweb = requests.get(str(url),timeout=5,cookies=cookies,headers=headers).text
|
||||
try:
|
||||
return getweb
|
||||
except:
|
||||
print("[-]Connect Failed! Please check your Proxy.")
|
||||
|
||||
def getTitle(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="center_column"]/div[2]/h1/text()')).strip(" ['']")
|
||||
return result
|
||||
def getActor(a): #//*[@id="center_column"]/div[2]/div[1]/div/table/tbody/tr[1]/td/text()
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result=str(html.xpath('//table[2]/tr[1]/td/a/text()')).strip(" ['\\n ']")
|
||||
return result
|
||||
def getStudio(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result=str(html.xpath('//table[2]/tr[2]/td/a/text()')).strip(" ['\\n ']")
|
||||
return result
|
||||
def getRuntime(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result=str(html.xpath('//table[2]/tr[3]/td/text()')).strip(" ['\\n ']")
|
||||
return result
|
||||
def getNum(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result=str(html.xpath('//table[2]/tr[4]/td/text()')).strip(" ['\\n ']")
|
||||
return result
|
||||
def getYear(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
#result=str(html.xpath('//table[2]/tr[5]/td/text()')).strip(" ['\\n ']")
|
||||
result=str(html.xpath('//table[2]/tr[5]/td/text()')).strip(" ['\\n ']")
|
||||
return result
|
||||
def getRelease(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result=str(html.xpath('//table[2]/tr[5]/td/text()')).strip(" ['\\n ']")
|
||||
return result
|
||||
def getCover(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="center_column"]/div[2]/div[1]/div/div/h2/img/@src')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('//table[2]/tr[7]/td/a/text()')).strip(" ['\\n ']")
|
||||
return result
|
||||
def getOutline(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="introduction"]/dd/p[1]/text()')).strip(" ['']")
|
||||
return result
|
||||
|
||||
def main(number):
|
||||
htmlcode=get_html('https://www.mgstage.com/product/product_detail/'+str(number))
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = str(soup.find(attrs={'class': 'detail_data'}))
|
||||
dic = {
|
||||
'title': getTitle(htmlcode).replace("\\n",'').replace(' ',''),
|
||||
'studio': getStudio(a),
|
||||
'year': getYear(a),
|
||||
'outline': getOutline(htmlcode),
|
||||
'runtime': getRuntime(a),
|
||||
'director': getDirector(a),
|
||||
'actor': getActor(a),
|
||||
'release': getRelease(a),
|
||||
'number': number,
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 0,
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
Reference in New Issue
Block a user