Compare commits
272 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
c66a53ade1 | ||
|
|
7aec4c4b84 | ||
|
|
cfb3511360 | ||
|
|
2adcfacf27 | ||
|
|
09dc684ff6 | ||
|
|
1bc924a6ac | ||
|
|
00db4741bc | ||
|
|
1086447369 | ||
|
|
642c8103c7 | ||
|
|
b053ae614c | ||
|
|
b7583afc9b | ||
|
|
731b08f843 | ||
|
|
64f235aaff | ||
|
|
f0d5a2a45d | ||
|
|
01521fe390 | ||
|
|
a33b882592 | ||
|
|
150b81453c | ||
|
|
a6df479b78 | ||
|
|
dd6445b2ba | ||
|
|
41051a915b | ||
|
|
32ce390939 | ||
|
|
8deec6a6c0 | ||
|
|
0fab70ff3d | ||
|
|
53bbb99a64 | ||
|
|
0e712de805 | ||
|
|
6f74254e96 | ||
|
|
4220bd708b | ||
|
|
3802d88972 | ||
|
|
8cddbf1e1b | ||
|
|
332326e5f6 | ||
|
|
27f64a81d0 | ||
|
|
7e3fa5ade8 | ||
|
|
cc362a2a26 | ||
|
|
dde6167b05 | ||
|
|
fe69f42f92 | ||
|
|
6b050cef43 | ||
|
|
c721c3c769 | ||
|
|
9f8702ca12 | ||
|
|
153b3a35b8 | ||
|
|
88e543a16f | ||
|
|
5906af6d95 | ||
|
|
39953f1870 | ||
|
|
047618a0df | ||
|
|
2da51a51d0 | ||
|
|
8c0e0a296d | ||
|
|
ce0ac607c2 | ||
|
|
f0437cf6af | ||
|
|
32bfc57eed | ||
|
|
909ca96915 | ||
|
|
341ab5b2bf | ||
|
|
d899a19419 | ||
|
|
61b0bc40de | ||
|
|
6fde3f98dd | ||
|
|
838eb9c8db | ||
|
|
687bbfce10 | ||
|
|
4b35113932 | ||
|
|
d672d4d0d7 | ||
|
|
1d3845bb91 | ||
|
|
e5effca854 | ||
|
|
bae82898da | ||
|
|
2e8e7151e3 | ||
|
|
8db74bc34d | ||
|
|
e18392d7d3 | ||
|
|
e4e32c06df | ||
|
|
09802c5632 | ||
|
|
584db78fd0 | ||
|
|
56a41604cb | ||
|
|
8228084a1d | ||
|
|
f16def5f3a | ||
|
|
c0303a57a1 | ||
|
|
07c8a7fb0e | ||
|
|
71691e1fe9 | ||
|
|
e2569e4541 | ||
|
|
51385491de | ||
|
|
bb049714cf | ||
|
|
5dcaa20a6c | ||
|
|
26652bf2ed | ||
|
|
352d2fa28a | ||
|
|
ff5ac0d599 | ||
|
|
f34888d2e7 | ||
|
|
f609e647b5 | ||
|
|
ffc280a01c | ||
|
|
fee0ae95b3 | ||
|
|
cd7e254d2e | ||
|
|
ce2995123d | ||
|
|
46e676b592 | ||
|
|
a435d645e4 | ||
|
|
76eecd1e6f | ||
|
|
3c296db204 | ||
|
|
7d6408fe29 | ||
|
|
337c84fd1c | ||
|
|
ad220c1ca6 | ||
|
|
37df711cdc | ||
|
|
92dd9cb734 | ||
|
|
64445b5105 | ||
|
|
bfdb094ee3 | ||
|
|
b38942a326 | ||
|
|
7d03a1f7f9 | ||
|
|
f9c0df7e06 | ||
|
|
b1783d8c75 | ||
|
|
908da6d006 | ||
|
|
9ec99143d4 | ||
|
|
575a710ef8 | ||
|
|
7c16307643 | ||
|
|
e816529260 | ||
|
|
8282e59a39 | ||
|
|
a96bdb8d13 | ||
|
|
f7f1c3e871 | ||
|
|
632250083f | ||
|
|
0ebfe43133 | ||
|
|
bb367fe79e | ||
|
|
3a4d405c8e | ||
|
|
8f8adcddbb | ||
|
|
394c831b05 | ||
|
|
bb8b3a3bc3 | ||
|
|
6c5c932b98 | ||
|
|
9a151a5d4c | ||
|
|
f24595687b | ||
|
|
aa130d2d25 | ||
|
|
bccc49508e | ||
|
|
ad6db7ca97 | ||
|
|
b95d35d6fa | ||
|
|
3bf0cf5fbc | ||
|
|
dbdc0c818d | ||
|
|
e156c34e23 | ||
|
|
ee782e3794 | ||
|
|
90aa77a23a | ||
|
|
d4251c8b44 | ||
|
|
6f684e67e2 | ||
|
|
18cf202b5b | ||
|
|
54b2b71472 | ||
|
|
44ba47bafc | ||
|
|
7eb72634d8 | ||
|
|
5787d3470a | ||
|
|
1fce045ac2 | ||
|
|
794aa74782 | ||
|
|
b2e49a99a7 | ||
|
|
d208d53375 | ||
|
|
7158378eca | ||
|
|
0961d8cbe4 | ||
|
|
6ef5d11742 | ||
|
|
45e1d8370c | ||
|
|
420f995977 | ||
|
|
dbe1f91bd9 | ||
|
|
770c5fcb1f | ||
|
|
665d1ffe43 | ||
|
|
14ed221152 | ||
|
|
c41b9c1e32 | ||
|
|
17d4d68cbe | ||
|
|
b5a23fe430 | ||
|
|
2747be4a21 | ||
|
|
02da503a2f | ||
|
|
31c5d5c314 | ||
|
|
22e5b9aa44 | ||
|
|
400e8c9678 | ||
|
|
b06e744c0c | ||
|
|
ddbfe7765b | ||
|
|
c0f47fb712 | ||
|
|
7b0e8bf5f7 | ||
|
|
fa8ea58fe6 | ||
|
|
8c824e5d29 | ||
|
|
764fba74ec | ||
|
|
36c436772c | ||
|
|
897a621adc | ||
|
|
1f5802cdb4 | ||
|
|
0a57e2bab6 | ||
|
|
3ddfe94f2b | ||
|
|
c6fd5ac565 | ||
|
|
2a7cdcf12d | ||
|
|
759e546534 | ||
|
|
222337a5f0 | ||
|
|
9fb6122a9d | ||
|
|
9f0c01d62e | ||
|
|
6ed79d8fcb | ||
|
|
abb53c3219 | ||
|
|
6578d807ca | ||
|
|
e9acd32fd7 | ||
|
|
0c64165b49 | ||
|
|
6278659e55 | ||
|
|
ca2c97a98f | ||
|
|
164cc464dc | ||
|
|
faa99507ad | ||
|
|
d7a48d2829 | ||
|
|
c40936f1c4 | ||
|
|
38b26d4161 | ||
|
|
e17dffba4e | ||
|
|
ae1a91bf28 | ||
|
|
208c24b606 | ||
|
|
751450ebad | ||
|
|
e429ca3c7d | ||
|
|
9e26558666 | ||
|
|
759b30ec5c | ||
|
|
b7c195b76e | ||
|
|
7038fcf8ed | ||
|
|
54041313dc | ||
|
|
47a29f6628 | ||
|
|
839610d230 | ||
|
|
a0b324c1a8 | ||
|
|
1996807702 | ||
|
|
e91b7a85bf | ||
|
|
dddaf5c74f | ||
|
|
2a3935b221 | ||
|
|
a5becea6c9 | ||
|
|
1381b66619 | ||
|
|
eb946d948f | ||
|
|
46087ba886 | ||
|
|
f8764d1b81 | ||
|
|
b9095452da | ||
|
|
be8d23e782 | ||
|
|
532c5bfbe3 | ||
|
|
cfccd00367 | ||
|
|
56801d3910 | ||
|
|
2d1efe272e | ||
|
|
ff7ed13419 | ||
|
|
7fade0fee3 | ||
|
|
2dc2da4b41 | ||
|
|
79679adbac | ||
|
|
637ae06a14 | ||
|
|
917614975e | ||
|
|
e3d9955e5b | ||
|
|
69fa8d3f05 | ||
|
|
b5f82f77a1 | ||
|
|
5f627d24e0 | ||
|
|
6817cd2093 | ||
|
|
bda0c5becd | ||
|
|
abcf1a49e7 | ||
|
|
23de02486c | ||
|
|
8046fa1ef6 | ||
|
|
0a6af7c41b | ||
|
|
08cdabb59d | ||
|
|
9c495c4a54 | ||
|
|
51e0467be0 | ||
|
|
59720d8c09 | ||
|
|
150943694b | ||
|
|
f40683e5ec | ||
|
|
912e5ed0fb | ||
|
|
f17994ecf8 | ||
|
|
a414c8eae9 | ||
|
|
8f0eed64c7 | ||
|
|
5f8131f984 | ||
|
|
a574d3a275 | ||
|
|
1813102b0b | ||
|
|
0ef0fed958 | ||
|
|
64be029c78 | ||
|
|
0f77b78133 | ||
|
|
b87f41dc8e | ||
|
|
ecdacdbcb8 | ||
|
|
8308f66ae7 | ||
|
|
44c89590ee | ||
|
|
e7b0980524 | ||
|
|
1cc328bbd7 | ||
|
|
66fbb5efbb | ||
|
|
88fded90ee | ||
|
|
b055f6ca7f | ||
|
|
254e37d9cf | ||
|
|
1c87c26f32 | ||
|
|
10f13f882f | ||
|
|
df17ee59f0 | ||
|
|
07fa18080b | ||
|
|
2bdf2ff283 | ||
|
|
5445f1773c | ||
|
|
b629fb4615 | ||
|
|
d50f5d2f34 | ||
|
|
13f36ddf8b | ||
|
|
295ea2d174 | ||
|
|
ad4fc237b1 | ||
|
|
55d8f02eee | ||
|
|
d6cbd3bdb2 | ||
|
|
99942745c4 | ||
|
|
4daee989e6 | ||
|
|
99b04ef8b5 | ||
|
|
9707f1b38a |
97
ADC_function.py
Executable file
@@ -0,0 +1,97 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import requests
|
||||
from configparser import ConfigParser
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
import sys
|
||||
|
||||
config_file='config.ini'
|
||||
config = ConfigParser()
|
||||
|
||||
if os.path.exists(config_file):
|
||||
try:
|
||||
config.read(config_file, encoding='UTF-8')
|
||||
except:
|
||||
print('[-]Config.ini read failed! Please use the offical file!')
|
||||
else:
|
||||
print('[+]config.ini: not found, creating...')
|
||||
with open("config.ini", "wt", encoding='UTF-8') as code:
|
||||
print("[proxy]",file=code)
|
||||
print("proxy=127.0.0.1:1080",file=code)
|
||||
print("timeout=10", file=code)
|
||||
print("retry=3", file=code)
|
||||
print("", file=code)
|
||||
print("[Name_Rule]", file=code)
|
||||
print("location_rule='JAV_output/'+actor+'/'+number",file=code)
|
||||
print("naming_rule=number+'-'+title",file=code)
|
||||
print("", file=code)
|
||||
print("[update]",file=code)
|
||||
print("update_check=1",file=code)
|
||||
print("", file=code)
|
||||
print("[media]", file=code)
|
||||
print("media_warehouse=emby", file=code)
|
||||
print("#emby or plex", file=code)
|
||||
print("#plex only test!", file=code)
|
||||
print("", file=code)
|
||||
print("[directory_capture]", file=code)
|
||||
print("switch=0", file=code)
|
||||
print("directory=", file=code)
|
||||
print("", file=code)
|
||||
print("everyone switch:1=on, 0=off", file=code)
|
||||
time.sleep(2)
|
||||
print('[+]config.ini: created!')
|
||||
try:
|
||||
config.read(config_file, encoding='UTF-8')
|
||||
except:
|
||||
print('[-]Config.ini read failed! Please use the offical file!')
|
||||
|
||||
def ReadMediaWarehouse():
|
||||
return config['media']['media_warehouse']
|
||||
|
||||
def UpdateCheckSwitch():
|
||||
check=str(config['update']['update_check'])
|
||||
if check == '1':
|
||||
return '1'
|
||||
elif check == '0':
|
||||
return '0'
|
||||
elif check == '':
|
||||
return '0'
|
||||
def get_html(url,cookies = None):#网页请求核心
|
||||
try:
|
||||
proxy = config['proxy']['proxy']
|
||||
timeout = int(config['proxy']['timeout'])
|
||||
retry_count = int(config['proxy']['retry'])
|
||||
except:
|
||||
print('[-]Proxy config error! Please check the config.')
|
||||
i = 0
|
||||
while i < retry_count:
|
||||
try:
|
||||
if not str(config['proxy']['proxy']) == '':
|
||||
proxies = {"http": "http://" + proxy,"https": "https://" + proxy}
|
||||
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36'}
|
||||
getweb = requests.get(str(url), headers=headers, timeout=timeout,proxies=proxies, cookies=cookies)
|
||||
getweb.encoding = 'utf-8'
|
||||
return getweb.text
|
||||
else:
|
||||
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
|
||||
getweb = requests.get(str(url), headers=headers, timeout=timeout, cookies=cookies)
|
||||
getweb.encoding = 'utf-8'
|
||||
return getweb.text
|
||||
except requests.exceptions.RequestException:
|
||||
i += 1
|
||||
print('[-]Connect retry '+str(i)+'/'+str(retry_count))
|
||||
except requests.exceptions.ConnectionError:
|
||||
i += 1
|
||||
print('[-]Connect retry '+str(i)+'/'+str(retry_count))
|
||||
except requests.exceptions.ProxyError:
|
||||
i += 1
|
||||
print('[-]Connect retry '+str(i)+'/'+str(retry_count))
|
||||
except requests.exceptions.ConnectTimeout:
|
||||
i += 1
|
||||
print('[-]Connect retry '+str(i)+'/'+str(retry_count))
|
||||
print('[-]Connect Failed! Please check your Proxy or Network!')
|
||||
|
||||
|
||||
179
AV_Data_Capture.py
Normal file → Executable file
@@ -1,13 +1,176 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import glob
|
||||
import os
|
||||
import time
|
||||
import re
|
||||
import sys
|
||||
from ADC_function import *
|
||||
import json
|
||||
import subprocess
|
||||
import shutil
|
||||
from configparser import ConfigParser
|
||||
|
||||
#a=glob.glob(os.getcwd()+r"\*.py")
|
||||
a=glob.glob(os.getcwd()+r"\*\**\*.mp4")
|
||||
b=glob.glob(os.getcwd()+r"\*.mp4")
|
||||
for i in b:
|
||||
a.append(i)
|
||||
|
||||
version='0.11.7'
|
||||
os.chdir(os.getcwd())
|
||||
for i in a:
|
||||
os.system('python core.py'+' "'+i+'"')
|
||||
|
||||
input_dir='.' # 电影的读取与输出路径, 默认为当前路径
|
||||
|
||||
config = ConfigParser()
|
||||
config.read(config_file, encoding='UTF-8')
|
||||
|
||||
def UpdateCheck():
|
||||
if UpdateCheckSwitch() == '1':
|
||||
html = json.loads(get_html('https://raw.githubusercontent.com/wenead99/AV_Data_Capture/master/update_check.json'))
|
||||
if not version == html['version']:
|
||||
print('[*] * New update ' + html['version'] + ' *')
|
||||
print('[*] * Download *')
|
||||
print('[*] ' + html['download'])
|
||||
print('[*]=====================================')
|
||||
else:
|
||||
print('[+]Update Check disabled!')
|
||||
|
||||
def set_directory(): # 设置读取与存放路径
|
||||
global input_dir
|
||||
# 配置项switch为1且定义了新的路径时, 更改默认存取路径
|
||||
if config['directory_capture']['switch'] == '1':
|
||||
custom_input = config['directory_capture']['input_directory']
|
||||
if custom_input != '': # 自定义了输入路径
|
||||
input_dir = format_path(custom_input)
|
||||
# 若自定义了输入路径, 输出路径默认在输入路径下
|
||||
CreatFolder(input_dir)
|
||||
#print('[+]Working directory is "' + os.getcwd() + '".')
|
||||
#print('[+]Using "' + input_dir + '" as input directory.')
|
||||
|
||||
def format_path(path): # 使路径兼容Linux与MacOS
|
||||
if path.find('\\'): # 是仅兼容Windows的路径格式
|
||||
path_list=path.split('\\')
|
||||
path='/'.join(path_list) # 转换为可移植的路径格式
|
||||
return path
|
||||
|
||||
|
||||
def movie_lists():
|
||||
a2 = glob.glob( input_dir + "/*.mp4")
|
||||
b2 = glob.glob( input_dir + "/*.avi")
|
||||
c2 = glob.glob( input_dir + "/*.rmvb")
|
||||
d2 = glob.glob( input_dir + "/*.wmv")
|
||||
e2 = glob.glob( input_dir + "/*.mov")
|
||||
f2 = glob.glob( input_dir + "/*.mkv")
|
||||
g2 = glob.glob( input_dir + "/*.flv")
|
||||
h2 = glob.glob( input_dir + "/*.ts")
|
||||
total = a2 + b2 + c2 + d2 + e2 + f2 + g2 + h2
|
||||
return total
|
||||
def CreatFolder(folder_path):
|
||||
if not os.path.exists(folder_path): # 新建文件夹
|
||||
try:
|
||||
print('[+]Creating ' + folder_path)
|
||||
os.makedirs(folder_path)
|
||||
except:
|
||||
print("[-]failed!can not be make folder '"+folder_path+"'\n[-](Please run as Administrator)")
|
||||
os._exit(0)
|
||||
def lists_from_test(custom_nuber): #电影列表
|
||||
a=[]
|
||||
a.append(custom_nuber)
|
||||
return a
|
||||
def CEF(path):
|
||||
files = os.listdir(path) # 获取路径下的子文件(夹)列表
|
||||
for file in files:
|
||||
try: #试图删除空目录,非空目录删除会报错
|
||||
os.removedirs(path + '/' + file) # 删除这个空文件夹
|
||||
print('[+]Deleting empty folder',path + '/' + file)
|
||||
except:
|
||||
a=''
|
||||
def rreplace(self, old, new, *max):
|
||||
#从右开始替换文件名中内容,源字符串,将被替换的子字符串, 新字符串,用于替换old子字符串,可选字符串, 替换不超过 max 次
|
||||
count = len(self)
|
||||
if max and str(max[0]).isdigit():
|
||||
count = max[0]
|
||||
return new.join(self.rsplit(old, count))
|
||||
def getNumber(filepath):
|
||||
try: # 试图提取番号
|
||||
# ====番号获取主程序====
|
||||
try: # 普通提取番号 主要处理包含减号-的番号
|
||||
filepath1 = filepath.replace("_", "-")
|
||||
filepath1.strip('22-sht.me').strip('-HD').strip('-hd')
|
||||
filename = str(re.sub("\[\d{4}-\d{1,2}-\d{1,2}\] - ", "", filepath1)) # 去除文件名中时间
|
||||
file_number = re.search('\w+-\d+', filename).group()
|
||||
return file_number
|
||||
except: # 提取不含减号-的番号
|
||||
try: # 提取东京热番号格式 n1087
|
||||
filename1 = str(re.sub("h26\d", "", filepath)).strip('Tokyo-hot').strip('tokyo-hot')
|
||||
filename0 = str(re.sub(".*?\.com-\d+", "", filename1)).strip('_')
|
||||
if '-C.' in filepath or '-c.' in filepath:
|
||||
cn_sub = '1'
|
||||
file_number = str(re.search('n\d{4}', filename0).group(0))
|
||||
return file_number
|
||||
except: # 提取无减号番号
|
||||
filename1 = str(re.sub("h26\d", "", filepath)) # 去除h264/265
|
||||
filename0 = str(re.sub(".*?\.com-\d+", "", filename1))
|
||||
file_number2 = str(re.match('\w+', filename0).group())
|
||||
if '-C.' in filepath or '-c.' in filepath:
|
||||
cn_sub = '1'
|
||||
file_number = str(file_number2.replace(re.match("^[A-Za-z]+", file_number2).group(),
|
||||
re.match("^[A-Za-z]+", file_number2).group() + '-'))
|
||||
return file_number
|
||||
# if not re.search('\w-', file_number).group() == 'None':
|
||||
# file_number = re.search('\w+-\w+', filename).group()
|
||||
# 上面是插入减号-到番号中
|
||||
# ====番号获取主程序=结束===
|
||||
except Exception as e: # 番号提取异常
|
||||
print('[-]' + str(os.path.basename(filepath)) + ' Cannot catch the number :')
|
||||
print('[-]' + str(os.path.basename(filepath)) + ' :', e)
|
||||
print('[-]Move ' + os.path.basename(filepath) + ' to failed folder')
|
||||
#print('[-]' + filepath + ' -> ' + output_dir + '/failed/')
|
||||
#shutil.move(filepath, output_dir + '/failed/')
|
||||
except IOError as e2:
|
||||
print('[-]' + str(os.path.basename(filepath)) + ' Cannot catch the number :')
|
||||
print('[-]' + str(os.path.basename(filepath)) + ' :', e2)
|
||||
#print('[-]' + filepath + ' -> ' + output_dir + '/failed/')
|
||||
#shutil.move(filepath, output_dir + '/failed/')
|
||||
|
||||
def RunCore(movie):
|
||||
# 异步调用core.py, core.py作为子线程执行, 本程序继续执行.
|
||||
if os.path.exists('core.py'):
|
||||
cmd_arg=[sys.executable,'core.py',movie,'--number',getNumber(movie)] #从py文件启动(用于源码py)
|
||||
elif os.path.exists('core.exe'):
|
||||
cmd_arg=['core.exe',movie,'--number',getNumber(movie)] #从exe启动(用于EXE版程序)
|
||||
elif os.path.exists('core.py') and os.path.exists('core.exe'):
|
||||
cmd_arg=[sys.executable,'core.py',movie,'--number',getNumber(movie)] #从py文件启动(用于源码py)
|
||||
process=subprocess.Popen(cmd_arg)
|
||||
return process
|
||||
|
||||
if __name__ =='__main__':
|
||||
print('[*]===========AV Data Capture===========')
|
||||
print('[*] Version '+version)
|
||||
print('[*]=====================================')
|
||||
UpdateCheck()
|
||||
os.chdir(os.getcwd())
|
||||
set_directory()
|
||||
|
||||
|
||||
count = 0
|
||||
movies = movie_lists()
|
||||
count_all = str(len(movies))
|
||||
print('[+]Find ' + str(len(movies)) + ' movies.')
|
||||
process_list=[]
|
||||
for movie in movies: #遍历电影列表 交给core处理
|
||||
num=getNumber(movie) # 获取番号
|
||||
if num is None:
|
||||
movies.remove(movie) # 未获取到番号, 则将影片从列表移除
|
||||
count_all=count_all-1
|
||||
continue
|
||||
print("[!]Making Data for [" + movie + "], the number is [" + num + "]")
|
||||
process=RunCore(movie)
|
||||
process_list.append(process)
|
||||
print("[*]=====================================")
|
||||
for i in range(len(movies)):
|
||||
process_list[i].communicate()
|
||||
percentage = str((i+1)/int(count_all)*100)[:4]+'%'
|
||||
print('[!] - '+percentage+' ['+str(count)+'/'+count_all+'] -')
|
||||
print("[!]The [" + getNumber(movies[i]) + "] process is done.")
|
||||
print("[*]=====================================")
|
||||
|
||||
CEF(input_dir)
|
||||
print("[+]All finished!!!")
|
||||
input("[+][+]Press enter key exit, you can check the error messge before you exit.\n[+][+]按回车键结束,你可以在结束之前查看和错误信息。")
|
||||
|
||||
198
README.md
@@ -1,22 +1,74 @@
|
||||
# 日本AV元数据抓取工具
|
||||
# AV Data Capture
|
||||
|
||||
## 关于本软件
|
||||
|
||||
目前,我下的AV越来越多,也意味着AV要集中地管理,形成媒体库。现在有两款主流的AV元数据获取器,"EverAver"和"Javhelper"。前者的优点是元数据获取比较全,缺点是不能批量处理;后者优点是可以批量处理,但是元数据不够全。
|
||||
<a title="Hits" target="_blank" href="https://github.com/yoshiko2/AV_Data_Capture"><img src="https://hits.b3log.org/yoshiko2/AV_Data_Capture.svg"></a>
|
||||

|
||||
<br>
|
||||

|
||||
<br>
|
||||
|
||||
为此,我写出了本软件,为了方便的管理本地AV,和更好的手冲体验。
|
||||
## 软件流程图 (下下一个为使用教程)
|
||||

|
||||
|
||||
## 如何使用 (如果使用release的程序可跳过第一步)
|
||||
1. 请安装requests,pyquery,lxml,Beautifulsoup4,pillow模块,可在CMD逐条输入以下命令安装
|
||||
**日本电影元数据 抓取工具 | 刮削器**,配合本地影片管理软件EMBY,KODI管理本地影片,该软件起到分类与元数据抓取作用,利用元数据信息来分类,供本地影片分类整理使用。
|
||||
|
||||
# 目录
|
||||
* [免责声明](#免责声明)
|
||||
* [注意](#注意)
|
||||
* [你问我答 FAQ](#你问我答-faq)
|
||||
* [效果图](#效果图)
|
||||
* [如何使用](#如何使用)
|
||||
* [下载](#下载)
|
||||
* [简明教程](#简要教程)
|
||||
* [模块安装](#1请安装模块在cmd终端逐条输入以下命令安装)
|
||||
* [配置](#2配置configini)
|
||||
* [运行软件](#4运行-av_data_capturepyexe)
|
||||
* [异常处理(重要)](#5异常处理重要)
|
||||
* [导入至媒体库](#7把jav_output文件夹导入到embykodi中根据封面选片子享受手冲乐趣)
|
||||
* [写在后面](#8写在后面)
|
||||
|
||||
# 免责声明
|
||||
1.本软件仅供**技术交流,学术交流**使用,本项目旨在学习 Python3<br>
|
||||
2.本软件禁止用于任何非法用途<br>
|
||||
3.使用者使用该软件产生的一切法律后果由使用者承担<br>
|
||||
4.不可使用于商业和个人其他意图<br>
|
||||
|
||||
# 注意
|
||||
**推荐用法: 使用该软件后,对于不能正常获取元数据的电影可以用 Everaver 来补救**<br>
|
||||
暂不支持多P电影<br>
|
||||
|
||||
# 你问我答 FAQ
|
||||
### F:这软件能下片吗?
|
||||
**Q**:该软件不提供任何影片下载地址,仅供本地影片分类整理使用。
|
||||
### F:什么是元数据?
|
||||
**Q**:元数据包括了影片的:封面,导演,演员,简介,类型......
|
||||
### F:软件收费吗?
|
||||
**Q**:软件永久免费。除了 **作者** 钦点以外,给那些 **利用本软件牟利** 的人送上 **骨灰盒-全家族 | 崭新出厂**
|
||||
### F:软件运行异常怎么办?
|
||||
**Q**:认真看 [异常处理(重要)](#5异常处理重要)
|
||||
|
||||
# 效果图
|
||||
**图片来自网络**,由于相关法律法规,具体效果请自行联想
|
||||
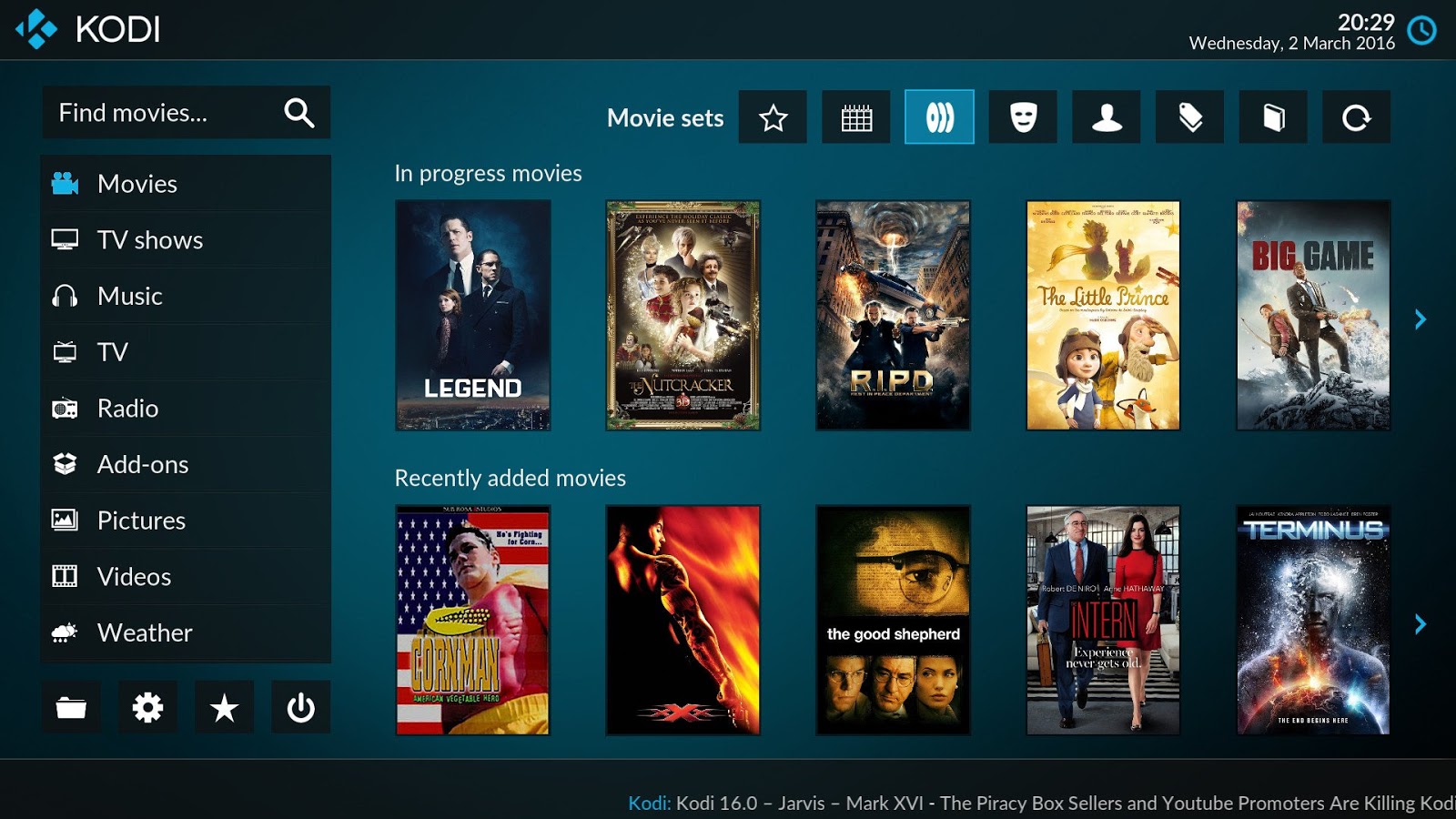
|
||||
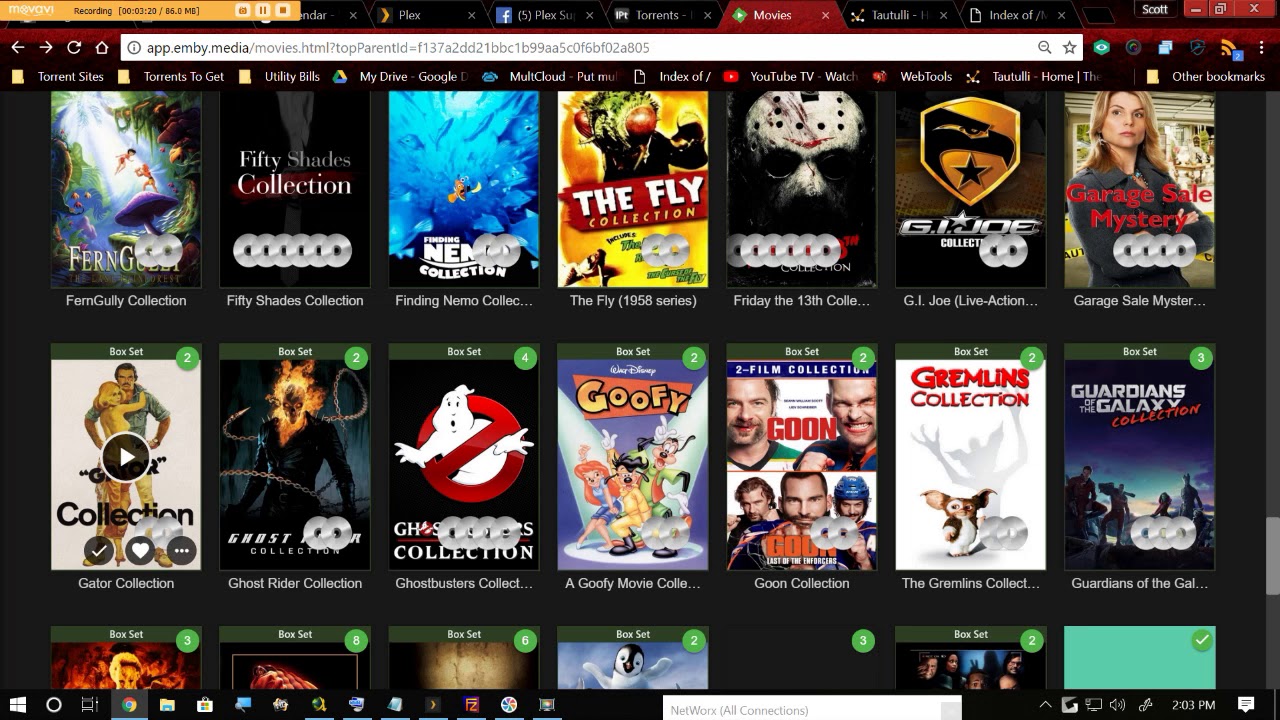<br>
|
||||
|
||||
# 如何使用
|
||||
### 下载
|
||||
* release的程序可脱离**python环境**运行,可跳过 [模块安装](#1请安装模块在cmd终端逐条输入以下命令安装)<br>Release 下载地址(**仅限Windows**):<br>[](https://github.com/yoshiko2/AV_Data_Capture/releases/download/0.11.6/Beta11.6.zip)<br>
|
||||
* Linux,MacOS请下载源码包运行
|
||||
|
||||
* Windows Python环境:[点击前往](https://www.python.org/downloads/windows/) 选中executable installer下载
|
||||
* MacOS Python环境:[点击前往](https://www.python.org/downloads/mac-osx/)
|
||||
* Linux Python环境:Linux用户懂的吧,不解释下载地址
|
||||
### 简要教程:<br>
|
||||
**1.把软件拉到和电影的同一目录<br>2.设置ini文件的代理(路由器拥有自动代理功能的可以把proxy=后面内容去掉)<br>3.运行软件等待完成<br>4.把JAV_output导入至KODI,EMBY中。<br>详细请看以下教程**<br>
|
||||
|
||||
## 1.请安装模块,在CMD/终端逐条输入以下命令安装
|
||||
```python
|
||||
pip install requests
|
||||
```
|
||||
###
|
||||
```python
|
||||
pip install pyquery
|
||||
```
|
||||
```
|
||||
###
|
||||
```python
|
||||
pip install lxml
|
||||
@@ -29,20 +81,130 @@ pip install Beautifulsoup4
|
||||
```python
|
||||
pip install pillow
|
||||
```
|
||||
###
|
||||
|
||||
2. 你的AV在被软件管理前最好命名为番号:
|
||||
## 2.配置config.ini
|
||||
config.ini
|
||||
>[proxy]<br>
|
||||
>proxy=127.0.0.1:1080<br>
|
||||
>timeout=10<br>
|
||||
>retry=3<br>
|
||||
>
|
||||
>[Name_Rule]<br>
|
||||
>location_rule='JAV_output/'+actor+'/['+number+']-'+title<br>
|
||||
>naming_rule=number+'-'+title<br>
|
||||
>
|
||||
>[update]<br>
|
||||
>update_check=1<br>
|
||||
>
|
||||
>[media]<br>
|
||||
>media_warehouse=emby<br>
|
||||
>#emby or plex<br>
|
||||
>#plex only test!<br>
|
||||
>
|
||||
>[directory_capture]<br>
|
||||
>switch=0<br>
|
||||
>directory=<br>
|
||||
>
|
||||
>#everyone switch:1=on, 0=off<br>
|
||||
|
||||
### 1.网络设置
|
||||
#### * 针对“某些地区”的代理设置
|
||||
打开```config.ini```,在```[proxy]```下的```proxy```行设置本地代理地址和端口,支持Shadowxxxx/X,V2XXX本地代理端口:<br>
|
||||
例子:```proxy=127.0.0.1:1080```<br>素人系列抓取建议使用日本代理<br>
|
||||
**路由器拥有自动代理功能的可以把proxy=后面内容去掉**<br>
|
||||
**本地代理软件开全局模式的同志同上**<br>
|
||||
**如果遇到tineout错误,可以把文件的proxy=后面的地址和端口删除,并开启vpn全局模式,或者重启电脑,vpn,网卡**<br>
|
||||
#### 连接超时重试设置
|
||||
>[proxy]<br>
|
||||
>timeout=10<br>
|
||||
|
||||
10为超时重试时间 单位:秒
|
||||
#### 连接重试次数设置
|
||||
>[proxy]<br>
|
||||
>retry=3<br>
|
||||
3即为重试次数
|
||||
|
||||
#### 检查更新开关
|
||||
>[update]<br>
|
||||
>update_check=1<br>
|
||||
0为关闭,1为开启,不建议关闭
|
||||
PLEX请安装插件:```XBMCnfoMoviesImporter```
|
||||
|
||||
##### 媒体库选择
|
||||
>[media]<br>
|
||||
>media_warehouse=emby<br>
|
||||
>#emby or plex<br>
|
||||
>#plex only test!<br>
|
||||
建议选择emby, plex不完善
|
||||
|
||||
#### 抓取目录选择
|
||||
>[directory_capture]<br>
|
||||
>switch=0<br>
|
||||
>input_directory=<br>
|
||||
>output_directory=<br>
|
||||
switch为1时,目录自定义才会被触发,此时可以指定抓取任意目录下的影片, 并指定存放的目录;如果为0则不触发,抓取和程序同一目录下的影片,directory不生效. 如果仅指定input_directory, output_directory默认与input_directory相同.
|
||||
|
||||
### (可选)设置自定义目录和影片重命名规则
|
||||
**已有默认配置**<br>
|
||||
##### 命名参数<br>
|
||||
>title = 片名<br>
|
||||
>actor = 演员<br>
|
||||
>studio = 公司<br>
|
||||
>director = 导演<br>
|
||||
>release = 发售日<br>
|
||||
>year = 发行年份<br>
|
||||
>number = 番号<br>
|
||||
>cover = 封面链接<br>
|
||||
>tag = 类型<br>
|
||||
>outline = 简介<br>
|
||||
>runtime = 时长<br>
|
||||
##### **例子**:<br>
|
||||
目录结构规则:```location_rule='JAV_output/'+actor+'/'+number```<br> **不推荐修改时在这里添加title**,有时title过长,因为Windows API问题,抓取数据时新建文件夹容易出错。<br>
|
||||
影片命名规则:```naming_rule='['+number+']-'+title```<br> **在EMBY,KODI等本地媒体库显示的标题,不影响目录结构下影片文件的命名**,依旧是 番号+后缀。
|
||||
### 3.更新开关
|
||||
>[update]<br>update_check=1<br>
|
||||
1为开,0为关
|
||||
## 3.把软件拷贝和电影的统一目录下
|
||||
## 4.运行 ```AV_Data_capture.py/.exe```
|
||||
当文件名包含:<br>
|
||||
中文,字幕,-c., -C., 处理元数据时会加上**中文字幕**标签
|
||||
## 5.异常处理(重要)
|
||||
### 请确保软件是完整地!确保ini文件内容是和下载提供ini文件内容的一致的!
|
||||
### 关于软件打开就闪退
|
||||
可以打开cmd命令提示符,把 ```AV_Data_capture.py/.exe```拖进cmd窗口回车运行,查看错误,出现的错误信息**依据以下条目解决**
|
||||
### 关于 ```Updata_check``` 和 ```JSON``` 相关的错误
|
||||
跳转 [网络设置](#1网络设置)
|
||||
### 关于```FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'JAV_output''```
|
||||
在软件所在文件夹下新建 JAV_output 文件夹,可能是你没有把软件拉到和电影的同一目录
|
||||
### 关于连接拒绝的错误
|
||||
请设置好[代理](#1针对某些地区的代理设置)<br>
|
||||
### 关于Nonetype,xpath报错
|
||||
同上<br>
|
||||
### 关于番号提取失败或者异常
|
||||
**目前可以提取元素的影片:JAVBUS上有元数据的电影,素人系列:300Maan,259luxu,siro等,FC2系列**<br>
|
||||
>下一张图片来自Pockies的blog 原作者已授权<br>
|
||||
|
||||
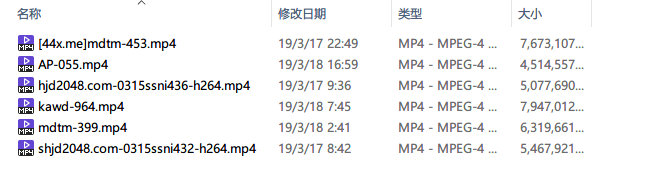
|
||||
|
||||
目前作者已经完善了番号提取机制,功能较为强大,可提取上述文件名的的番号,如果出现提取失败或者异常的情况,请用以下规则命名<br>
|
||||
**妈蛋不要喂软件那么多野鸡片子,不让软件好好活了,操**
|
||||
```
|
||||
COSQ-004.mp4
|
||||
```
|
||||
文件名中间要有减号"-",没有多余的内容只有番号为最佳,可以让软件更好获取元数据
|
||||
|
||||

|
||||
针对 **野鸡番号** ,你需要把文件名命名为与抓取网站提供的番号一致(文件拓展名除外),然后把文件拖拽至core.exe/.py<br>
|
||||
**野鸡番号**:比如 ```XXX-XXX-1```, ```1301XX-MINA_YUKA``` 这种**野鸡**番号,在javbus等资料库存在的作品。<br>**重要**:除了 **影片文件名** ```XXXX-XXX-C```,后面这种-C的是指电影有中文字幕!<br>
|
||||
条件:文件名中间要有下划线或者减号"_","-",没有多余的内容只有番号为最佳,可以让软件更好获取元数据
|
||||
对于多影片重命名,可以用[ReNamer](http://www.den4b.com/products/renamer)来批量重命名<br>
|
||||
### 关于PIL/image.py
|
||||
暂时无解,可能是网络问题或者pillow模块打包问题,你可以用源码运行(要安装好第一步的模块)
|
||||
|
||||
3. 把软件拷贝到AV的所在目录下,运行程序(中国大陆用户必须挂VPN,Shsadowsocks开全局代理)
|
||||
4. 运行AV_Data_capture.py
|
||||
5. 软件会自动把元数据获取成功的电影移动到JAV_output文件夹中,根据女优分类,失败的电影移动到failed文件夹中。
|
||||
|
||||

|
||||

|
||||

|
||||
## 6.软件会自动把元数据获取成功的电影移动到JAV_output文件夹中,根据演员分类,失败的电影移动到failed文件夹中。
|
||||
## 7.把JAV_output文件夹导入到EMBY,KODI中,等待元数据刷新,完成
|
||||
## 8.写在后面
|
||||
怎么样,看着自己的日本电影被这样完美地管理,是不是感觉成就感爆棚呢?<br>
|
||||
**tg官方电报群:[ 点击进群](https://t.me/AV_Data_Capture_Official)**<br>
|
||||
|
||||
|
||||
|
||||
21
config.ini
Normal file
@@ -0,0 +1,21 @@
|
||||
[proxy]
|
||||
proxy=127.0.0.1:1080
|
||||
timeout=10
|
||||
retry=3
|
||||
|
||||
[Name_Rule]
|
||||
location_rule='JAV_output/'+actor+'/'+number
|
||||
naming_rule=number+'-'+title
|
||||
|
||||
[update]
|
||||
update_check=1
|
||||
|
||||
[media]
|
||||
media_warehouse=emby
|
||||
#emby or plex
|
||||
#plex only test!
|
||||
|
||||
[directory_capture]
|
||||
input_directory=
|
||||
|
||||
#everyone switch:1=on, 0=off
|
||||
560
core.py
Normal file → Executable file
@@ -1,186 +1,416 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
import requests #need install
|
||||
from pyquery import PyQuery as pq#need install
|
||||
from lxml import etree#need install
|
||||
import os
|
||||
import os.path
|
||||
import shutil
|
||||
from bs4 import BeautifulSoup#need install
|
||||
from PIL import Image#need install
|
||||
from PIL import Image
|
||||
import time
|
||||
import javbus
|
||||
import json
|
||||
import fc2fans_club
|
||||
import siro
|
||||
from ADC_function import *
|
||||
from configparser import ConfigParser
|
||||
import argparse
|
||||
import javdb
|
||||
|
||||
def get_html(url):
|
||||
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
|
||||
getweb = requests.get(str(url),proxies={"http": "http://127.0.0.1:2334","https": "https://127.0.0.1:2334"},timeout=5,headers=headers).text
|
||||
try:
|
||||
return getweb
|
||||
except Exception as e:
|
||||
print(e)
|
||||
except IOError as e1:
|
||||
print(e1)
|
||||
#================================================
|
||||
def getTitle(htmlcode):
|
||||
doc = pq(htmlcode)
|
||||
title=str(doc('div.container h3').text()).replace(' ','-')
|
||||
return title
|
||||
def getStudio(htmlcode):
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[5]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getYear(htmlcode):
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
result2 = str(re.search('\d{4}', result).group(0))
|
||||
return result2
|
||||
def getCover(htmlcode):
|
||||
doc = pq(htmlcode)
|
||||
image = doc('a.bigImage')
|
||||
return image.attr('href')
|
||||
print(image.attr('href'))
|
||||
def getRelease(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getRuntime(htmlcode):
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find(text=re.compile('分鐘'))
|
||||
return a
|
||||
def getActor(htmlcode):
|
||||
b=[]
|
||||
soup=BeautifulSoup(htmlcode,'lxml')
|
||||
a=soup.find_all(attrs={'class':'star-name'})
|
||||
for i in a:
|
||||
b.append(i.text)
|
||||
return ",".join(b)
|
||||
def getNum(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[4]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getOutline(htmlcode):
|
||||
doc = pq(htmlcode)
|
||||
result = str(doc('tr td div.mg-b20.lh4 p.mg-b20').text())
|
||||
return result
|
||||
#================================================
|
||||
def DownloadFileWithFilename(url,filename,path): #path = examle:photo , video.in the Project Folder!
|
||||
import requests
|
||||
import re
|
||||
try:
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
r = requests.get(url)
|
||||
with open(str(path) + "/"+str(filename), "wb") as code:
|
||||
code.write(r.content)
|
||||
# print('[+]Downloaded!',str(path) + "/"+str(filename))
|
||||
except IOError as e:
|
||||
print("[-]Download Failed1!")
|
||||
print("[-]Movie not found in Javbus.com!")
|
||||
print("[*]=====================================")
|
||||
return "failed"
|
||||
except Exception as e1:
|
||||
print(e1)
|
||||
print("[-]Download Failed2!")
|
||||
time.sleep(3)
|
||||
#初始化全局变量
|
||||
title=''
|
||||
studio=''
|
||||
year=''
|
||||
outline=''
|
||||
runtime=''
|
||||
director=''
|
||||
actor_list=[]
|
||||
actor=''
|
||||
release=''
|
||||
number=''
|
||||
cover=''
|
||||
imagecut=''
|
||||
tag=[]
|
||||
cn_sub=''
|
||||
path=''
|
||||
houzhui=''
|
||||
website=''
|
||||
json_data={}
|
||||
actor_photo={}
|
||||
naming_rule =''#eval(config['Name_Rule']['naming_rule'])
|
||||
location_rule=''#eval(config['Name_Rule']['location_rule'])
|
||||
|
||||
Config = ConfigParser()
|
||||
Config.read(config_file, encoding='UTF-8')
|
||||
try:
|
||||
option = ReadMediaWarehouse()
|
||||
except:
|
||||
print('[-]Config media_warehouse read failed!')
|
||||
|
||||
#=====================本地文件处理===========================
|
||||
def moveFailedFolder():
|
||||
global filepath
|
||||
print('[-]Move to "failed"')
|
||||
#print('[-]' + filepath + ' -> ' + output_dir + '/failed/')
|
||||
#os.rename(filepath, output_dir + '/failed/')
|
||||
os._exit(0)
|
||||
|
||||
def PrintFiles(path):
|
||||
try:
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
with open(path + "/" + getNum(html) + ".nfo", "wt", encoding='UTF-8') as code:
|
||||
print("<movie>", file=code)
|
||||
print(" <title>" + getTitle(html) + "</title>", file=code)
|
||||
print(" <set>", file=code)
|
||||
print(" </set>", file=code)
|
||||
print(" <studio>" + getStudio(html) + "+</studio>", file=code)
|
||||
print(" <year>" + getYear(html) + "</year>", file=code)
|
||||
print(" <outline>"+getOutline(html_outline)+"</outline>", file=code)
|
||||
print(" <plot>"+getOutline(html_outline)+"</plot>", file=code)
|
||||
print(" <runtime>"+str(getRuntime(html)).replace(" ","")+"</runtime>", file=code)
|
||||
print(" <director>" + getDirector(html) + "</director>", file=code)
|
||||
print(" <poster>" + getNum(html) + ".png</poster>", file=code)
|
||||
print(" <thumb>" + getNum(html) + ".png</thumb>", file=code)
|
||||
print(" <fanart>"+getNum(html) + '.jpg'+"</fanart>", file=code)
|
||||
print(" <actor>", file=code)
|
||||
print(" <name>" + getActor(html) + "</name>", file=code)
|
||||
print(" </actor>", file=code)
|
||||
print(" <maker>" + getStudio(html) + "</maker>", file=code)
|
||||
print(" <label>", file=code)
|
||||
print(" </label>", file=code)
|
||||
print(" <num>" + getNum(html) + "</num>", file=code)
|
||||
print(" <release>" + getRelease(html) + "</release>", file=code)
|
||||
print(" <cover>"+getCover(html)+"</cover>", file=code)
|
||||
print(" <website>" + "https://www.javbus.com/"+getNum(html) + "</website>", file=code)
|
||||
print("</movie>", file=code)
|
||||
print("[+]Writeed! "+path + "/" + getNum(html) + ".nfo")
|
||||
except IOError as e:
|
||||
print("[-]Write Failed!")
|
||||
print(e)
|
||||
except Exception as e1:
|
||||
print(e1)
|
||||
print("[-]Write Failed!")
|
||||
#================================================
|
||||
if __name__ == '__main__':
|
||||
#命令行处理
|
||||
import argparse
|
||||
def argparse_get_file():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("file", help="Write the file path on here")
|
||||
parser.add_argument("--number", help="Enter Number on here", default='')
|
||||
args = parser.parse_args()
|
||||
filename=str(os.path.basename(args.file)) #\[\d{4}(\-|\/|.)\d{1,2}\1\d{1,2}\]
|
||||
#去除文件名中日期
|
||||
#print(filename)
|
||||
deldate=str(re.sub("\[\d{4}-\d{1,2}-\d{1,2}\] - ","",filename))
|
||||
#print(deldate)
|
||||
number=str(re.search('\w+-\w+',deldate).group())
|
||||
#print(number)
|
||||
#获取网页信息
|
||||
html = get_html("https://www.javbus.com/"+str(number))
|
||||
html_outline=get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid="+number.replace("-",''))
|
||||
#处理超长文件夹名称
|
||||
if len(getActor(html)) > 240:
|
||||
path = 'JAV_output' + '/' + '超多人' + '/' + getNum(html)
|
||||
return (args.file, args.number)
|
||||
def CreatFailedFolder():
|
||||
if not os.path.exists('/failed/'): # 新建failed文件夹
|
||||
try:
|
||||
os.makedirs('/failed/')
|
||||
except:
|
||||
print("[-]failed!can not be make folder 'failed'\n[-](Please run as Administrator)")
|
||||
os._exit(0)
|
||||
def getDataFromJSON(file_number): #从JSON返回元数据
|
||||
global title
|
||||
global studio
|
||||
global year
|
||||
global outline
|
||||
global runtime
|
||||
global director
|
||||
global actor_list
|
||||
global actor
|
||||
global release
|
||||
global number
|
||||
global cover
|
||||
global imagecut
|
||||
global tag
|
||||
global image_main
|
||||
global cn_sub
|
||||
global website
|
||||
global actor_photo
|
||||
|
||||
global naming_rule
|
||||
global location_rule
|
||||
|
||||
|
||||
# ================================================网站规则添加开始================================================
|
||||
|
||||
try: # 添加 需要 正则表达式的规则
|
||||
# =======================javdb.py=======================
|
||||
if re.search('^\d{5,}', file_number).group() in file_number:
|
||||
json_data = json.loads(javbus.main_uncensored(file_number))
|
||||
except: # 添加 无需 正则表达式的规则
|
||||
# ====================fc2fans_club.py====================
|
||||
if 'fc2' in file_number:
|
||||
json_data = json.loads(fc2fans_club.main(
|
||||
file_number.strip('fc2_').strip('fc2-').strip('ppv-').strip('PPV-').strip('FC2_').strip('FC2-').strip('ppv-').strip('PPV-')))
|
||||
elif 'FC2' in file_number:
|
||||
json_data = json.loads(fc2fans_club.main(
|
||||
file_number.strip('FC2_').strip('FC2-').strip('ppv-').strip('PPV-').strip('fc2_').strip('fc2-').strip('ppv-').strip('PPV-')))
|
||||
elif 'siro' in number or 'SIRO' in number or 'Siro' in number:
|
||||
json_data = json.loads(siro.main(file_number))
|
||||
# =======================javbus.py=======================
|
||||
else:
|
||||
path = 'JAV_output' + '/' + getActor(html) + '/' + getNum(html)
|
||||
json_data = json.loads(javbus.main(file_number))
|
||||
|
||||
# ================================================网站规则添加结束================================================
|
||||
|
||||
title = str(json_data['title']).replace(' ','')
|
||||
studio = json_data['studio']
|
||||
year = json_data['year']
|
||||
outline = json_data['outline']
|
||||
runtime = json_data['runtime']
|
||||
director = json_data['director']
|
||||
actor_list = str(json_data['actor']).strip("[ ]").replace("'", '').split(',') # 字符串转列表
|
||||
release = json_data['release']
|
||||
number = json_data['number']
|
||||
cover = json_data['cover']
|
||||
imagecut = json_data['imagecut']
|
||||
tag = str(json_data['tag']).strip("[ ]").replace("'", '').replace(" ", '').split(',') # 字符串转列表
|
||||
actor = str(actor_list).strip("[ ]").replace("'", '').replace(" ", '')
|
||||
actor_photo = json_data['actor_photo']
|
||||
website = json_data['website']
|
||||
|
||||
if title == '' or number == '':
|
||||
print('[-]Movie Data not found!')
|
||||
moveFailedFolder()
|
||||
|
||||
# ====================处理异常字符====================== #\/:*?"<>|
|
||||
if '\\' in title:
|
||||
title=title.replace('\\', ' ')
|
||||
elif '/' in title:
|
||||
title=title.replace('/', '')
|
||||
elif ':' in title:
|
||||
title=title.replace('/', '')
|
||||
elif '*' in title:
|
||||
title=title.replace('*', '')
|
||||
elif '?' in title:
|
||||
title=title.replace('?', '')
|
||||
elif '"' in title:
|
||||
title=title.replace('"', '')
|
||||
elif '<' in title:
|
||||
title=title.replace('<', '')
|
||||
elif '>' in title:
|
||||
title=title.replace('>', '')
|
||||
elif '|' in title:
|
||||
title=title.replace('|', '')
|
||||
# ====================处理异常字符 END================== #\/:*?"<>|
|
||||
|
||||
naming_rule = eval(config['Name_Rule']['naming_rule'])
|
||||
location_rule = eval(config['Name_Rule']['location_rule'])
|
||||
def creatFolder(): #创建文件夹
|
||||
global actor
|
||||
global path
|
||||
if len(actor) > 240: #新建成功输出文件夹
|
||||
path = location_rule.replace("'actor'","'超多人'",3).replace("actor","'超多人'",3) #path为影片+元数据所在目录
|
||||
#print(path)
|
||||
else:
|
||||
path = location_rule
|
||||
#print(path)
|
||||
if not os.path.exists(path):
|
||||
try:
|
||||
os.makedirs(path)
|
||||
except:
|
||||
path = location_rule.replace('/['+number+']-'+title,"/number")
|
||||
#print(path)
|
||||
os.makedirs(path)
|
||||
#=====================资源下载部分===========================
|
||||
def DownloadFileWithFilename(url,filename,path): #path = examle:photo , video.in the Project Folder!
|
||||
try:
|
||||
proxy = Config['proxy']['proxy']
|
||||
timeout = int(Config['proxy']['timeout'])
|
||||
retry_count = int(Config['proxy']['retry'])
|
||||
except:
|
||||
print('[-]Proxy config error! Please check the config.')
|
||||
i = 0
|
||||
|
||||
while i < retry_count:
|
||||
try:
|
||||
if not proxy == '':
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
#文件路径处理
|
||||
#print(str(args))
|
||||
filepath = str(args).replace("Namespace(file='",'').replace("')",'').replace('\\\\', '\\')
|
||||
#print(filepath)
|
||||
houzhui = str(re.search('[.](AVI|RMVB|WMV|MOV|MP4|MKV|FLV|avi|rmvb|wmv|mov|mp4|mkv|flv)$',filepath).group())
|
||||
print("[!]Making Data for ["+number+houzhui+"]")
|
||||
#下载元数据
|
||||
|
||||
|
||||
if not os.path.exists('failed/'):
|
||||
os.makedirs('failed/')
|
||||
if not os.path.exists('failed/'):
|
||||
print("[-]failed!Dirs can not be make (Please run as Administrator)")
|
||||
os._exit(0)
|
||||
if DownloadFileWithFilename(getCover(html), getNum(html) + '.jpg', path) == 'failed':
|
||||
shutil.move(filepath, 'failed/')
|
||||
time.sleep(3)
|
||||
headers = {
|
||||
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
|
||||
r = requests.get(url, headers=headers, timeout=timeout,proxies={"http": "http://" + str(proxy), "https": "https://" + str(proxy)})
|
||||
if r == '':
|
||||
print('[-]Movie Data not found!')
|
||||
os._exit(0)
|
||||
with open(str(path) + "/" + filename, "wb") as code:
|
||||
code.write(r.content)
|
||||
return
|
||||
else:
|
||||
if DownloadFileWithFilename(getCover(html), getNum(html) + '.jpg', path) == 'failed':
|
||||
shutil.move(filepath, 'failed/')
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
headers = {
|
||||
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
|
||||
r = requests.get(url, timeout=timeout, headers=headers)
|
||||
if r == '':
|
||||
print('[-]Movie Data not found!')
|
||||
os._exit(0)
|
||||
DownloadFileWithFilename(getCover(html), getNum(html) + '.jpg', path)
|
||||
print('[+]Downloaded!', path +'/'+getNum(html)+'.jpg')
|
||||
#切割图片做封面
|
||||
with open(str(path) + "/" + filename, "wb") as code:
|
||||
code.write(r.content)
|
||||
return
|
||||
except requests.exceptions.RequestException:
|
||||
i += 1
|
||||
print('[-]Image Download : Connect retry '+str(i)+'/'+str(retry_count))
|
||||
except requests.exceptions.ConnectionError:
|
||||
i += 1
|
||||
print('[-]Image Download : Connect retry '+str(i)+'/'+str(retry_count))
|
||||
except requests.exceptions.ProxyError:
|
||||
i += 1
|
||||
print('[-]Image Download : Connect retry '+str(i)+'/'+str(retry_count))
|
||||
except requests.exceptions.ConnectTimeout:
|
||||
i += 1
|
||||
print('[-]Image Download : Connect retry '+str(i)+'/'+str(retry_count))
|
||||
print('[-]Connect Failed! Please check your Proxy or Network!')
|
||||
moveFailedFolder()
|
||||
def imageDownload(filepath): #封面是否下载成功,否则移动到failed
|
||||
if option == 'emby':
|
||||
if DownloadFileWithFilename(cover, number + '.jpg', path) == 'failed':
|
||||
moveFailedFolder()
|
||||
DownloadFileWithFilename(cover, number + '.jpg', path)
|
||||
print('[+]Image Downloaded!', path + '/' + number + '.jpg')
|
||||
elif option == 'plex':
|
||||
if DownloadFileWithFilename(cover, 'fanart.jpg', path) == 'failed':
|
||||
moveFailedFolder()
|
||||
DownloadFileWithFilename(cover, 'fanart.jpg', path)
|
||||
print('[+]Image Downloaded!', path + '/fanart.jpg')
|
||||
def PrintFiles(filepath):
|
||||
#global path
|
||||
global title
|
||||
global cn_sub
|
||||
global actor_photo
|
||||
try:
|
||||
img = Image.open(path + '/' + getNum(html) + '.jpg')
|
||||
img2 = img.crop((421, 0, 800, 538))
|
||||
img2.save(path + '/' + getNum(html) + '.png')
|
||||
if not os.path.exists(path):
|
||||
os.makedirs(path)
|
||||
if option == 'plex':
|
||||
with open(path + "/" + number + ".nfo", "wt", encoding='UTF-8') as code:
|
||||
print("<movie>", file=code)
|
||||
print(" <title>" + naming_rule + "</title>", file=code)
|
||||
print(" <set>", file=code)
|
||||
print(" </set>", file=code)
|
||||
print(" <studio>" + studio + "+</studio>", file=code)
|
||||
print(" <year>" + year + "</year>", file=code)
|
||||
print(" <outline>" + outline + "</outline>", file=code)
|
||||
print(" <plot>" + outline + "</plot>", file=code)
|
||||
print(" <runtime>" + str(runtime).replace(" ", "") + "</runtime>", file=code)
|
||||
print(" <director>" + director + "</director>", file=code)
|
||||
print(" <poster>poster.png</poster>", file=code)
|
||||
print(" <thumb>thumb.png</thumb>", file=code)
|
||||
print(" <fanart>fanart.jpg</fanart>", file=code)
|
||||
try:
|
||||
for key, value in actor_photo.items():
|
||||
print(" <actor>", file=code)
|
||||
print(" <name>" + key + "</name>", file=code)
|
||||
if not actor_photo == '': # or actor_photo == []:
|
||||
print(" <thumb>" + value + "</thumb>", file=code)
|
||||
print(" </actor>", file=code)
|
||||
except:
|
||||
aaaa = ''
|
||||
print(" <maker>" + studio + "</maker>", file=code)
|
||||
print(" <label>", file=code)
|
||||
print(" </label>", file=code)
|
||||
if cn_sub == '1':
|
||||
print(" <tag>中文字幕</tag>", file=code)
|
||||
try:
|
||||
for i in tag:
|
||||
print(" <tag>" + i + "</tag>", file=code)
|
||||
except:
|
||||
aaaaa = ''
|
||||
try:
|
||||
for i in tag:
|
||||
print(" <genre>" + i + "</genre>", file=code)
|
||||
except:
|
||||
aaaaaaaa = ''
|
||||
if cn_sub == '1':
|
||||
print(" <genre>中文字幕</genre>", file=code)
|
||||
print(" <num>" + number + "</num>", file=code)
|
||||
print(" <release>" + release + "</release>", file=code)
|
||||
print(" <cover>" + cover + "</cover>", file=code)
|
||||
print(" <website>" + website + "</website>", file=code)
|
||||
print("</movie>", file=code)
|
||||
print("[+]Writeed! " + path + "/" + number + ".nfo")
|
||||
elif option == 'emby':
|
||||
with open(path + "/" + number + ".nfo", "wt", encoding='UTF-8') as code:
|
||||
print("<movie>", file=code)
|
||||
print(" <title>" + naming_rule + "</title>", file=code)
|
||||
print(" <set>", file=code)
|
||||
print(" </set>", file=code)
|
||||
print(" <studio>" + studio + "+</studio>", file=code)
|
||||
print(" <year>" + year + "</year>", file=code)
|
||||
print(" <outline>" + outline + "</outline>", file=code)
|
||||
print(" <plot>" + outline + "</plot>", file=code)
|
||||
print(" <runtime>" + str(runtime).replace(" ", "") + "</runtime>", file=code)
|
||||
print(" <director>" + director + "</director>", file=code)
|
||||
print(" <poster>" + number + ".png</poster>", file=code)
|
||||
print(" <thumb>" + number + ".png</thumb>", file=code)
|
||||
print(" <fanart>" + number + '.jpg' + "</fanart>", file=code)
|
||||
try:
|
||||
for key, value in actor_photo.items():
|
||||
print(" <actor>", file=code)
|
||||
print(" <name>" + key + "</name>", file=code)
|
||||
if not actor_photo == '': # or actor_photo == []:
|
||||
print(" <thumb>" + value + "</thumb>", file=code)
|
||||
print(" </actor>", file=code)
|
||||
except:
|
||||
aaaa = ''
|
||||
print(" <maker>" + studio + "</maker>", file=code)
|
||||
print(" <label>", file=code)
|
||||
print(" </label>", file=code)
|
||||
if cn_sub == '1':
|
||||
print(" <tag>中文字幕</tag>", file=code)
|
||||
try:
|
||||
for i in tag:
|
||||
print(" <tag>" + i + "</tag>", file=code)
|
||||
except:
|
||||
aaaaa = ''
|
||||
try:
|
||||
for i in tag:
|
||||
print(" <genre>" + i + "</genre>", file=code)
|
||||
except:
|
||||
aaaaaaaa = ''
|
||||
if cn_sub == '1':
|
||||
print(" <genre>中文字幕</genre>", file=code)
|
||||
print(" <num>" + number + "</num>", file=code)
|
||||
print(" <release>" + release + "</release>", file=code)
|
||||
print(" <cover>" + cover + "</cover>", file=code)
|
||||
print(" <website>" + "https://www.javbus.com/" + number + "</website>", file=code)
|
||||
print("</movie>", file=code)
|
||||
print("[+]Writeed! " + path + "/" + number + ".nfo")
|
||||
except IOError as e:
|
||||
print("[-]Write Failed!")
|
||||
print(e)
|
||||
moveFailedFolder()
|
||||
except Exception as e1:
|
||||
print(e1)
|
||||
print("[-]Write Failed!")
|
||||
moveFailedFolder()
|
||||
def cutImage():
|
||||
if option == 'plex':
|
||||
if imagecut == 1:
|
||||
try:
|
||||
img = Image.open(path + '/fanart.jpg')
|
||||
imgSize = img.size
|
||||
w = img.width
|
||||
h = img.height
|
||||
img2 = img.crop((w / 1.9, 0, w, h))
|
||||
img2.save(path + '/poster.png')
|
||||
except:
|
||||
print('[-]Cover cut failed!')
|
||||
# 电源文件位置处理
|
||||
else:
|
||||
img = Image.open(path + '/fanart.jpg')
|
||||
w = img.width
|
||||
h = img.height
|
||||
img.save(path + '/poster.png')
|
||||
elif option == 'emby':
|
||||
if imagecut == 1:
|
||||
try:
|
||||
img = Image.open(path + '/' + number + '.jpg')
|
||||
imgSize = img.size
|
||||
w = img.width
|
||||
h = img.height
|
||||
img2 = img.crop((w / 1.9, 0, w, h))
|
||||
img2.save(path + '/' + number + '.png')
|
||||
except:
|
||||
print('[-]Cover cut failed!')
|
||||
else:
|
||||
img = Image.open(path + '/' + number + '.jpg')
|
||||
w = img.width
|
||||
h = img.height
|
||||
img.save(path + '/' + number + '.png')
|
||||
def pasteFileToFolder(filepath, path): #文件路径,番号,后缀,要移动至的位置
|
||||
global houzhui
|
||||
houzhui = str(re.search('[.](AVI|RMVB|WMV|MOV|MP4|MKV|FLV|TS|avi|rmvb|wmv|mov|mp4|mkv|flv|ts)$', filepath).group())
|
||||
os.rename(filepath, number + houzhui)
|
||||
try:
|
||||
shutil.move(number + houzhui, path)
|
||||
#处理元数据
|
||||
PrintFiles(path)
|
||||
print('[!]Finished!')
|
||||
time.sleep(3)
|
||||
except:
|
||||
print('[-]File Exists! Please check your movie!')
|
||||
print('[-]move to the root folder of the program.')
|
||||
os._exit(0)
|
||||
def moveJpgToBackdrop_copy():
|
||||
if option == 'plex':
|
||||
shutil.copy(path + '/fanart.jpg', path + '/Backdrop.jpg')
|
||||
shutil.copy(path + '/poster.png', path + '/thumb.png')
|
||||
if option == 'emby':
|
||||
shutil.copy(path + '/' + number + '.jpg', path + '/Backdrop.jpg')
|
||||
|
||||
if __name__ == '__main__':
|
||||
filepath=argparse_get_file()[0] #影片的路径
|
||||
|
||||
if '-c.' in filepath or '-C.' in filepath or '中文' in filepath or '字幕' in filepath:
|
||||
cn_sub='1'
|
||||
|
||||
if argparse_get_file()[1] == '': #获取手动拉去影片获取的番号
|
||||
try:
|
||||
number = str(re.findall(r'(.+?)\.',str(re.search('([^<>/\\\\|:""\\*\\?]+)\\.\\w+$',filepath).group()))).strip("['']").replace('_','-')
|
||||
print("[!]Making Data for [" + number + "]")
|
||||
except:
|
||||
print("[-]failed!Please move the filename again!")
|
||||
moveFailedFolder()
|
||||
else:
|
||||
number = argparse_get_file()[1]
|
||||
CreatFailedFolder()
|
||||
getDataFromJSON(number) # 定义番号
|
||||
creatFolder() # 创建文件夹
|
||||
imageDownload(filepath) # creatFoder会返回番号路径
|
||||
PrintFiles(filepath) # 打印文件
|
||||
cutImage() # 裁剪图
|
||||
pasteFileToFolder(filepath, path) # 移动文件
|
||||
moveJpgToBackdrop_copy()
|
||||
|
||||
85
fc2fans_club.py
Executable file
@@ -0,0 +1,85 @@
|
||||
#!/usr/bin/env python3
|
||||
import re
|
||||
from lxml import etree#need install
|
||||
import json
|
||||
import ADC_function
|
||||
|
||||
def getTitle(htmlcode): #获取厂商
|
||||
#print(htmlcode)
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h3/text()')).strip(" ['']")
|
||||
result2 = str(re.sub('\D{2}2-\d+','',result)).replace(' ','',1)
|
||||
#print(result2)
|
||||
return result2
|
||||
def getActor(htmlcode):
|
||||
try:
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h5[5]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
except:
|
||||
return ''
|
||||
def getStudio(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h5[3]/a[1]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getNum(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
#print(result)
|
||||
return result
|
||||
def getRelease(htmlcode2): #
|
||||
#a=ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id='+str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-")+'&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html=etree.fromstring(htmlcode2,etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[2]/dl/dd[4]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getCover(htmlcode,number,htmlcode2): #获取厂商 #
|
||||
#a = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id=' + str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-") + '&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html = etree.fromstring(htmlcode2, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[1]/a/img/@src')).strip(" ['']")
|
||||
if result == '':
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result2 = str(html.xpath('//*[@id="slider"]/ul[1]/li[1]/img/@src')).strip(" ['']")
|
||||
return 'http://fc2fans.club' + result2
|
||||
return 'http:' + result
|
||||
def getOutline(htmlcode2,number): #获取番号 #
|
||||
#a = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id=' + str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-") + '&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
html = etree.fromstring(htmlcode2, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[4]/p/text()')).replace("\\n",'',10000).strip(" ['']").replace("'",'',10000)
|
||||
return result
|
||||
def getTag(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div/div[1]/h5[4]/a/text()'))
|
||||
return result.strip(" ['']").replace("'",'').replace(' ','')
|
||||
def getYear(release):
|
||||
try:
|
||||
result = re.search('\d{4}',release).group()
|
||||
return result
|
||||
except:
|
||||
return ''
|
||||
|
||||
def main(number2):
|
||||
number=number2.replace('PPV','').replace('ppv','')
|
||||
htmlcode2 = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id='+str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-")+'&utm_source=aff_php&utm_medium=source_code&utm_campaign=from_aff_php')
|
||||
htmlcode = ADC_function.get_html('http://fc2fans.club/html/FC2-' + number + '.html')
|
||||
dic = {
|
||||
'title': getTitle(htmlcode),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': '',#str(re.search('\d{4}',getRelease(number)).group()),
|
||||
'outline': getOutline(htmlcode,number),
|
||||
'runtime': getYear(getRelease(htmlcode)),
|
||||
'director': getStudio(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(number),
|
||||
'number': 'FC2-'+number,
|
||||
'cover': getCover(htmlcode,number,htmlcode2),
|
||||
'imagecut': 0,
|
||||
'tag': getTag(htmlcode),
|
||||
'actor_photo':'',
|
||||
'website': 'http://fc2fans.club/html/FC2-' + number + '.html',
|
||||
}
|
||||
#print(getTitle(htmlcode))
|
||||
#print(getNum(htmlcode))
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
|
||||
#print(main('1051725'))
|
||||
BIN
flow_chart.jpg
{kind=link}
|
Before Width: | Height: | Size: 91 KiB |
177
javbus.py
Executable file
@@ -0,0 +1,177 @@
|
||||
#!/usr/bin/env python3
|
||||
import re
|
||||
import requests #need install
|
||||
from pyquery import PyQuery as pq#need install
|
||||
from lxml import etree#need install
|
||||
import os
|
||||
import os.path
|
||||
import shutil
|
||||
from bs4 import BeautifulSoup#need install
|
||||
from PIL import Image#need install
|
||||
import time
|
||||
import json
|
||||
from ADC_function import *
|
||||
import javdb
|
||||
import siro
|
||||
|
||||
def getActorPhoto(htmlcode): #//*[@id="star_qdt"]/li/a/img
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find_all(attrs={'class': 'star-name'})
|
||||
d={}
|
||||
for i in a:
|
||||
l=i.a['href']
|
||||
t=i.get_text()
|
||||
html = etree.fromstring(get_html(l), etree.HTMLParser())
|
||||
p=str(html.xpath('//*[@id="waterfall"]/div[1]/div/div[1]/img/@src')).strip(" ['']")
|
||||
p2={t:p}
|
||||
d.update(p2)
|
||||
return d
|
||||
def getTitle(htmlcode): #获取标题
|
||||
doc = pq(htmlcode)
|
||||
title=str(doc('div.container h3').text()).replace(' ','-')
|
||||
try:
|
||||
title2 = re.sub('n\d+-','',title)
|
||||
return title2
|
||||
except:
|
||||
return title
|
||||
def getStudio(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[5]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getYear(htmlcode): #获取年份
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getCover(htmlcode): #获取封面链接
|
||||
doc = pq(htmlcode)
|
||||
image = doc('a.bigImage')
|
||||
return image.attr('href')
|
||||
def getRelease(htmlcode): #获取出版日期
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getRuntime(htmlcode): #获取分钟
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find(text=re.compile('分鐘'))
|
||||
return a
|
||||
def getActor(htmlcode): #获取女优
|
||||
b=[]
|
||||
soup=BeautifulSoup(htmlcode,'lxml')
|
||||
a=soup.find_all(attrs={'class':'star-name'})
|
||||
for i in a:
|
||||
b.append(i.get_text())
|
||||
return b
|
||||
def getNum(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(htmlcode): #获取导演
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[4]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getOutline(htmlcode): #获取演员
|
||||
doc = pq(htmlcode)
|
||||
result = str(doc('tr td div.mg-b20.lh4 p.mg-b20').text())
|
||||
return result
|
||||
def getSerise(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[7]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getTag(htmlcode): # 获取演员
|
||||
tag = []
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find_all(attrs={'class': 'genre'})
|
||||
for i in a:
|
||||
if 'onmouseout' in str(i):
|
||||
continue
|
||||
tag.append(i.get_text())
|
||||
return tag
|
||||
|
||||
|
||||
def main(number):
|
||||
try:
|
||||
if re.search('\d+\D+', number).group() in number or 'siro' in number or 'SIRO' in number or 'Siro' in number:
|
||||
js = siro.main(number)
|
||||
return js
|
||||
except:
|
||||
aaaa=''
|
||||
|
||||
try:
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-', '', getTitle(htmlcode))),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': str(re.search('\d{4}', getYear(htmlcode)).group()),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
'actor_photo': getActorPhoto(htmlcode),
|
||||
'website': 'https://www.javbus.com/' + number,
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
if 'HEYZO' in number or 'heyzo' in number or 'Heyzo' in number:
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
#dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-', '', getTitle(htmlcode))),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'outline': '',
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
'actor_photo': getActorPhoto(htmlcode),
|
||||
'website': 'https://www.javbus.com/' + number,
|
||||
}
|
||||
js2 = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4,
|
||||
separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js2
|
||||
return js
|
||||
except:
|
||||
a=javdb.main(number)
|
||||
return a
|
||||
|
||||
def main_uncensored(number):
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
if getTitle(htmlcode) == '':
|
||||
htmlcode = get_html('https://www.javbus.com/' + number.replace('-','_'))
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))).replace(getNum(htmlcode)+'-',''),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
'imagecut': 0,
|
||||
'actor_photo': '',
|
||||
'website': 'https://www.javbus.com/' + number,
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
|
||||
if getYear(htmlcode) == '' or getYear(htmlcode) == 'null':
|
||||
js2 = javdb.main(number)
|
||||
return js2
|
||||
|
||||
return js
|
||||
141
javdb.py
Executable file
@@ -0,0 +1,141 @@
|
||||
#!/usr/bin/env python3
|
||||
import re
|
||||
from lxml import etree
|
||||
import json
|
||||
import requests
|
||||
from bs4 import BeautifulSoup
|
||||
from ADC_function import *
|
||||
|
||||
def getTitle(a):
|
||||
try:
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/section/div/h2/strong/text()')).strip(" ['']")
|
||||
return re.sub('.*\] ','',result.replace('/', ',').replace('\\xa0','').replace(' : ',''))
|
||||
except:
|
||||
return re.sub('.*\] ','',result.replace('/', ',').replace('\\xa0',''))
|
||||
def getActor(a): #//*[@id="center_column"]/div[2]/div[1]/div/table/tbody/tr[1]/td/text()
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"演員")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"演員")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').replace(",\\xa0","").replace("'","").replace(' ','').replace(',,','').lstrip(',').replace(',',', ')
|
||||
def getStudio(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"製作")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"製作")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1+result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getRuntime(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"時長")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"時長")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').rstrip('mi')
|
||||
def getLabel(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"系列")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"系列")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getNum(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result1 = str(html.xpath('//strong[contains(text(),"番號")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"番號")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+')
|
||||
def getYear(getRelease):
|
||||
try:
|
||||
result = str(re.search('\d{4}',getRelease).group())
|
||||
return result
|
||||
except:
|
||||
return getRelease
|
||||
def getRelease(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"時間")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"時間")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+')
|
||||
def getTag(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"类别")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"类别")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').replace(",\\xa0","").replace("'","").replace(' ','').replace(',,','').lstrip(',')
|
||||
def getCover(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/section/div/div[2]/div[1]/a/img/@src')).strip(" ['']")
|
||||
if result == '':
|
||||
result = str(html.xpath('/html/body/section/div/div[3]/div[1]/a/img/@src')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"導演")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"導演")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getOutline(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="introduction"]/dd/p[1]/text()')).strip(" ['']")
|
||||
return result
|
||||
def main(number):
|
||||
try:
|
||||
a = get_html('https://javdb.com/search?q=' + number + '&f=all')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="videos"]/div/div/a/@href')).strip(" ['']")
|
||||
if result1 == '':
|
||||
a = get_html('https://javdb.com/search?q=' + number.replace('-', '_') + '&f=all')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="videos"]/div/div/a/@href')).strip(" ['']")
|
||||
b = get_html('https://javdb1.com' + result1)
|
||||
soup = BeautifulSoup(b, 'lxml')
|
||||
|
||||
a = str(soup.find(attrs={'class': 'panel'}))
|
||||
dic = {
|
||||
'actor': getActor(a),
|
||||
'title': getTitle(b).replace("\\n", '').replace(' ', '').replace(getActor(a), '').replace(getNum(a),
|
||||
'').replace(
|
||||
'无码', '').replace('有码', '').lstrip(' '),
|
||||
'studio': getStudio(a),
|
||||
'outline': getOutline(a),
|
||||
'runtime': getRuntime(a),
|
||||
'director': getDirector(a),
|
||||
'release': getRelease(a),
|
||||
'number': getNum(a),
|
||||
'cover': getCover(b),
|
||||
'imagecut': 0,
|
||||
'tag': getTag(a),
|
||||
'label': getLabel(a),
|
||||
'year': getYear(getRelease(a)), # str(re.search('\d{4}',getRelease(a)).group()),
|
||||
'actor_photo': '',
|
||||
'website': 'https://javdb1.com' + result1,
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js
|
||||
except:
|
||||
a = get_html('https://javdb.com/search?q=' + number + '&f=all')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="videos"]/div/div/a/@href')).strip(" ['']")
|
||||
if result1 == '':
|
||||
a = get_html('https://javdb.com/search?q=' + number.replace('-', '_') + '&f=all')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="videos"]/div/div/a/@href')).strip(" ['']")
|
||||
|
||||
b = get_html('https://javdb.com' + result1)
|
||||
soup = BeautifulSoup(b, 'lxml')
|
||||
|
||||
a = str(soup.find(attrs={'class': 'panel'}))
|
||||
dic = {
|
||||
'actor': getActor(a),
|
||||
'title': getTitle(b).replace("\\n", '').replace(' ', '').replace(getActor(a), '').replace(getNum(a),
|
||||
'').replace(
|
||||
'无码', '').replace('有码', '').lstrip(' '),
|
||||
'studio': getStudio(a),
|
||||
'outline': getOutline(a),
|
||||
'runtime': getRuntime(a),
|
||||
'director': getDirector(a),
|
||||
'release': getRelease(a),
|
||||
'number': getNum(a),
|
||||
'cover': getCover(b),
|
||||
'imagecut': 0,
|
||||
'tag': getTag(a),
|
||||
'label': getLabel(a),
|
||||
'year': getYear(getRelease(a)), # str(re.search('\d{4}',getRelease(a)).group()),
|
||||
'actor_photo': '',
|
||||
'website':'https://javdb.com' + result1,
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js
|
||||
|
||||
#print(main('061519-861'))
|
||||
1
readme/This is readms.md's images folder
Normal file
@@ -0,0 +1 @@
|
||||
1
|
||||
BIN
readme/flow_chart2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 101 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.1 KiB After Width: | Height: | Size: 1.1 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.4 KiB After Width: | Height: | Size: 3.4 KiB |
{kind=link}
|
Before Width: | Height: | Size: 1.3 KiB After Width: | Height: | Size: 1.3 KiB |
{kind=link}
|
Before Width: | Height: | Size: 16 KiB After Width: | Height: | Size: 16 KiB |
BIN
readme/readme5.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 457 KiB |
BIN
readme/single.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 68 KiB |
105
siro.py
Executable file
@@ -0,0 +1,105 @@
|
||||
#!/usr/bin/env python3
|
||||
import re
|
||||
from lxml import etree
|
||||
import json
|
||||
import requests
|
||||
from bs4 import BeautifulSoup
|
||||
from ADC_function import *
|
||||
|
||||
def getTitle(a):
|
||||
try:
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="center_column"]/div[2]/h1/text()')).strip(" ['']")
|
||||
return result.replace('/', ',')
|
||||
except:
|
||||
return ''
|
||||
def getActor(a): #//*[@id="center_column"]/div[2]/div[1]/div/table/tbody/tr[1]/td/text()
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result1=str(html.xpath('//th[contains(text(),"出演:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
result2=str(html.xpath('//th[contains(text(),"出演:")]/../td/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
return str(result1+result2).strip('+').replace("', '",'').replace('"','').replace('/',',')
|
||||
def getStudio(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result1=str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
result2=str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
return str(result1+result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getRuntime(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"収録時間:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"収録時間:")]/../td/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
return str(result1 + result2).strip('+').rstrip('mi')
|
||||
def getLabel(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getNum(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"品番:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"品番:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+')
|
||||
def getYear(getRelease):
|
||||
try:
|
||||
result = str(re.search('\d{4}',getRelease).group())
|
||||
return result
|
||||
except:
|
||||
return getRelease
|
||||
def getRelease(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"配信開始日:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"配信開始日:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+')
|
||||
def getTag(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"ジャンル:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"ジャンル:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+').replace("', '\\n",",").replace("', '","").replace('"','')
|
||||
def getCover(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="center_column"]/div[2]/div[1]/div/div/h2/img/@src')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"シリーズ")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"シリーズ")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getOutline(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="introduction"]/dd/p[1]/text()')).strip(" ['']")
|
||||
return result
|
||||
def main(number2):
|
||||
number=number2.upper()
|
||||
htmlcode=get_html('https://www.mgstage.com/product/product_detail/'+str(number)+'/',cookies={'adc':'1'})
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = str(soup.find(attrs={'class': 'detail_data'})).replace('\n ','').replace(' ','').replace('\n ','').replace('\n ','')
|
||||
dic = {
|
||||
'title': getTitle(htmlcode).replace("\\n",'').replace(' ',''),
|
||||
'studio': getStudio(a),
|
||||
'outline': getOutline(htmlcode),
|
||||
'runtime': getRuntime(a),
|
||||
'director': getDirector(a),
|
||||
'actor': getActor(a),
|
||||
'release': getRelease(a),
|
||||
'number': getNum(a),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 0,
|
||||
'tag': getTag(a),
|
||||
'label':getLabel(a),
|
||||
'year': getYear(getRelease(a)), # str(re.search('\d{4}',getRelease(a)).group()),
|
||||
'actor_photo': '',
|
||||
'website':'https://www.mgstage.com/product/product_detail/'+str(number)+'/',
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
|
||||
#print(main('300maan-373'))
|
||||
5
update_check.json
Normal file
@@ -0,0 +1,5 @@
|
||||
{
|
||||
"version": "0.11.7",
|
||||
"version_show":"Beta 11.7",
|
||||
"download": "https://github.com/wenead99/AV_Data_Capture/releases"
|
||||
}
|
||||