+

+
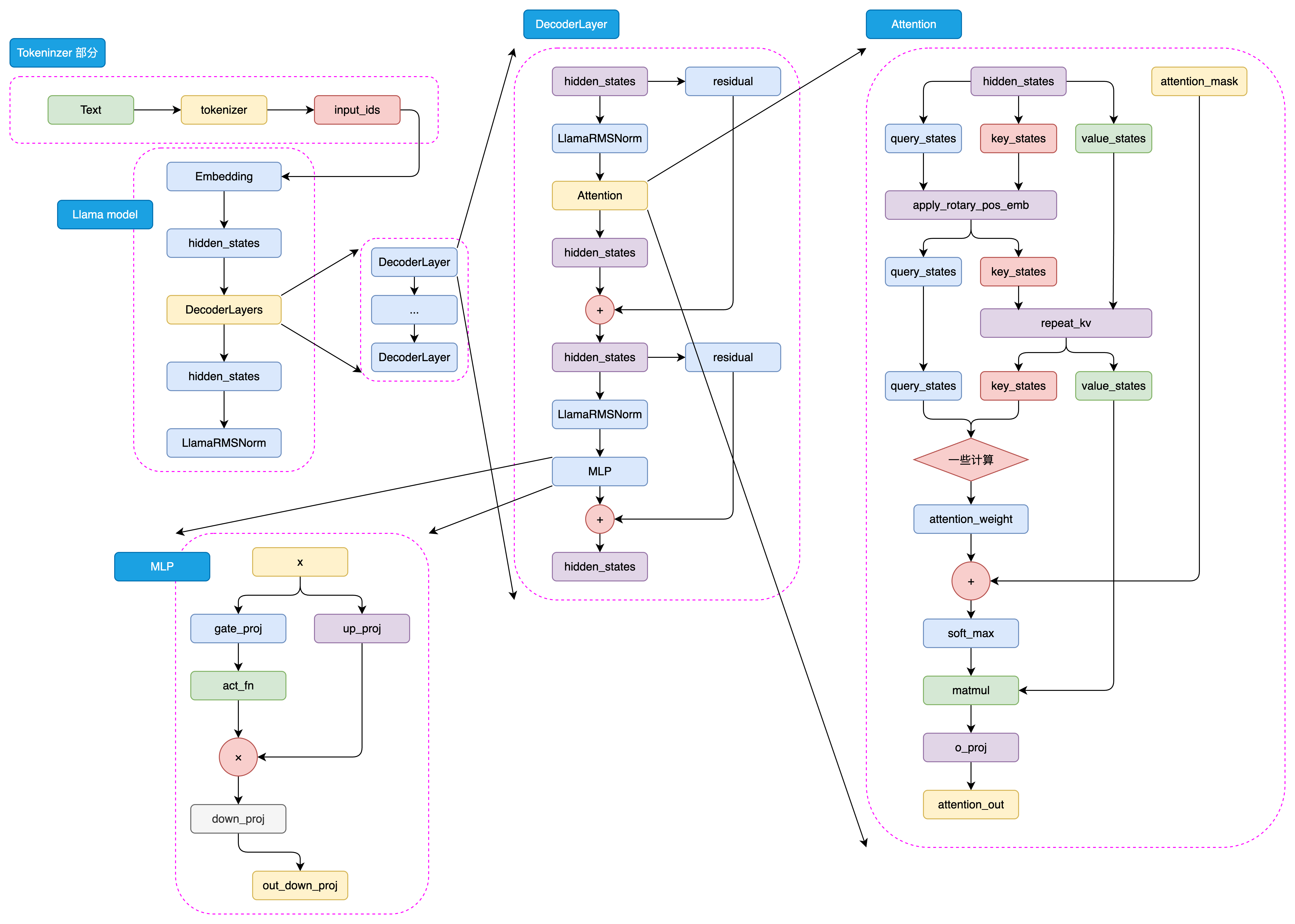
图 5.2 LLaMA2 Attention 结构
+
 -
-  -
-  -
-