 +
+ 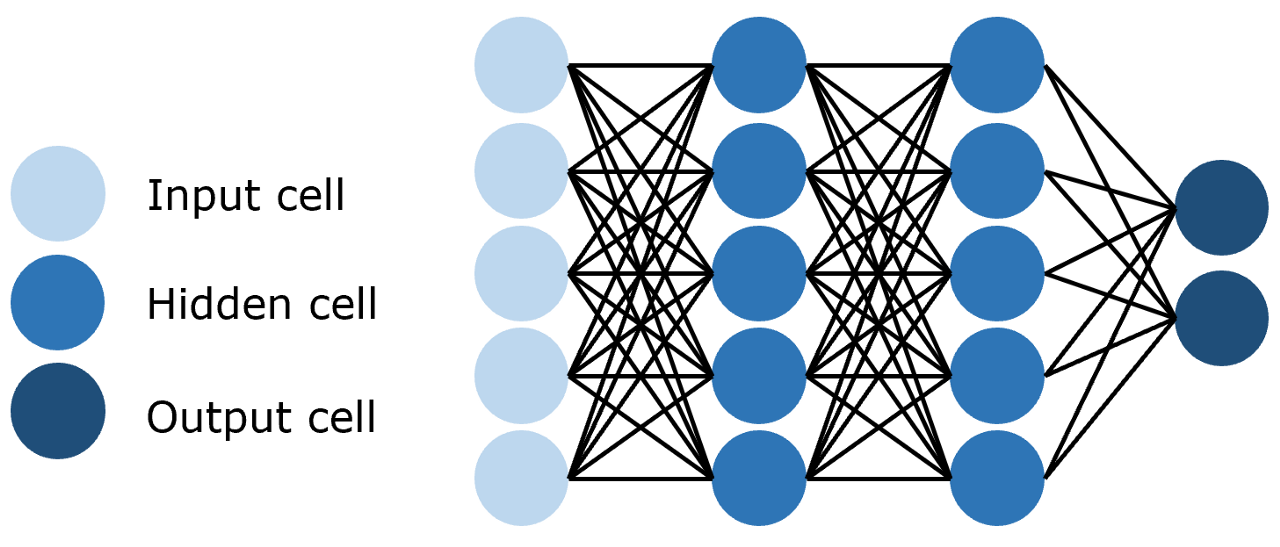
图2.1 前馈神经网络
+
图2.1 前馈神经网络
 +
+ 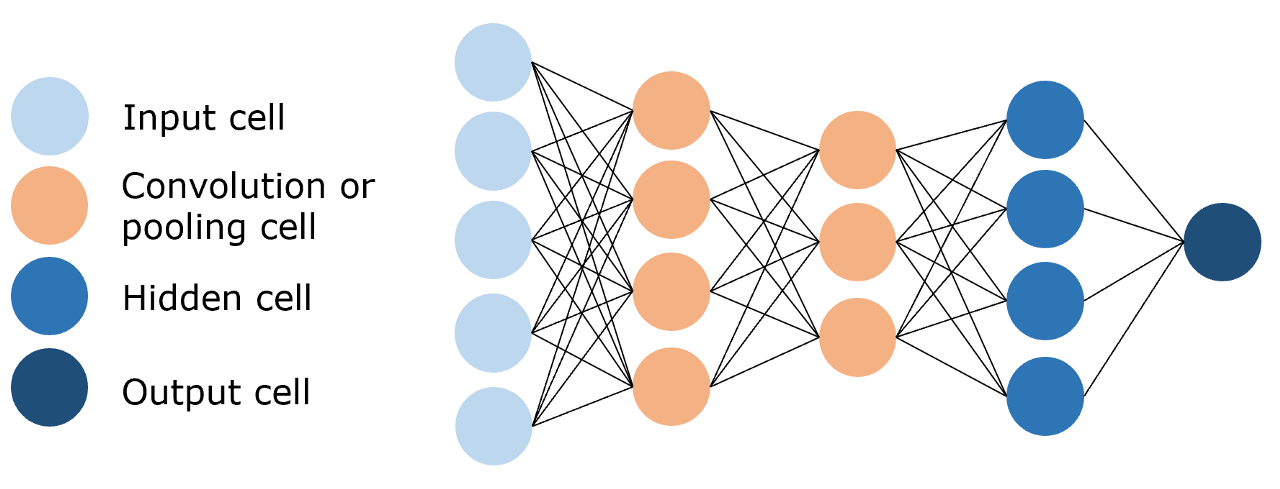
图2.2 卷积神经网络
 +
+ 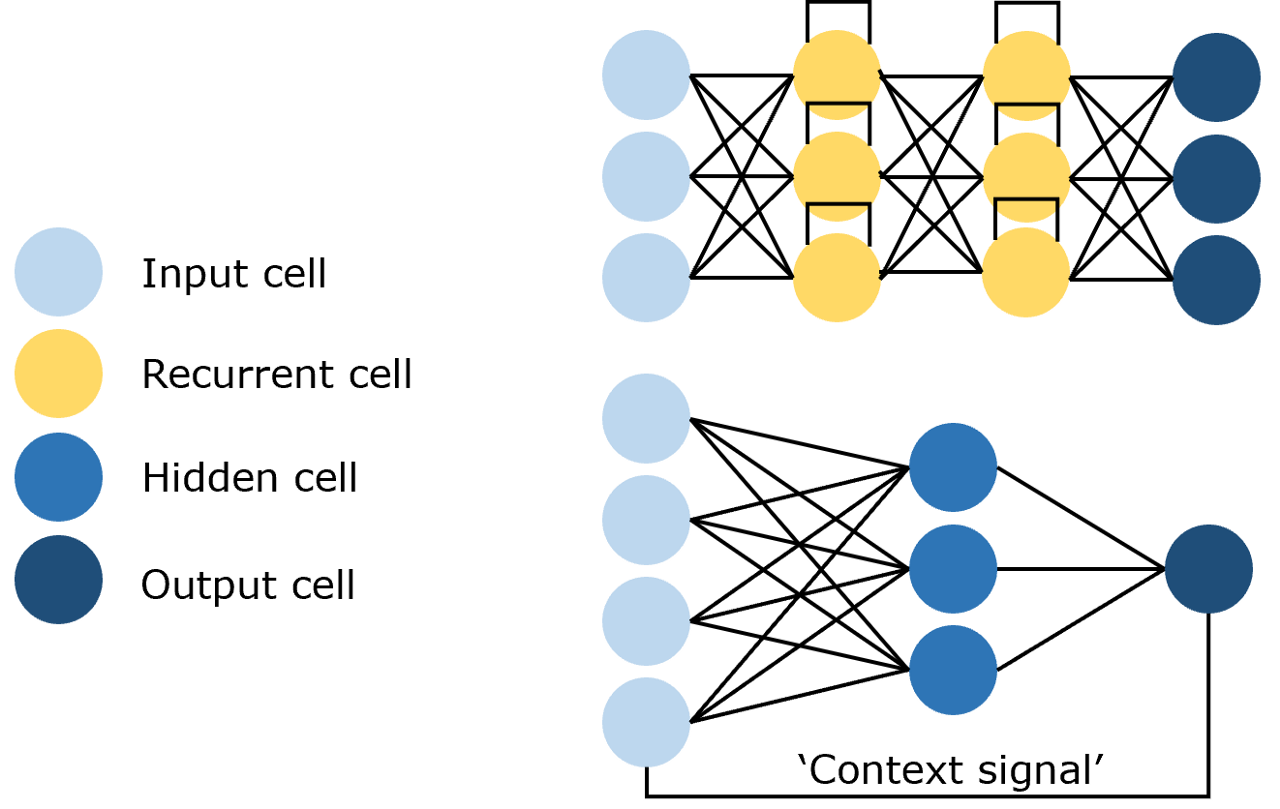
图2.3 循环神经网络
 +
+ 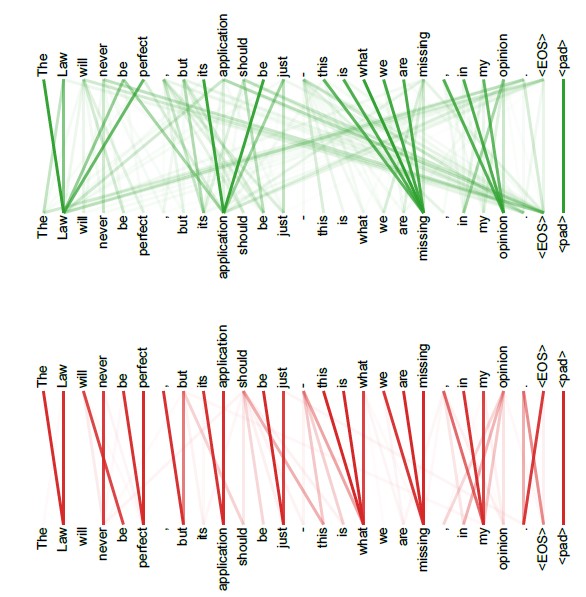
图2.4 多头注意力机制
 +
+ 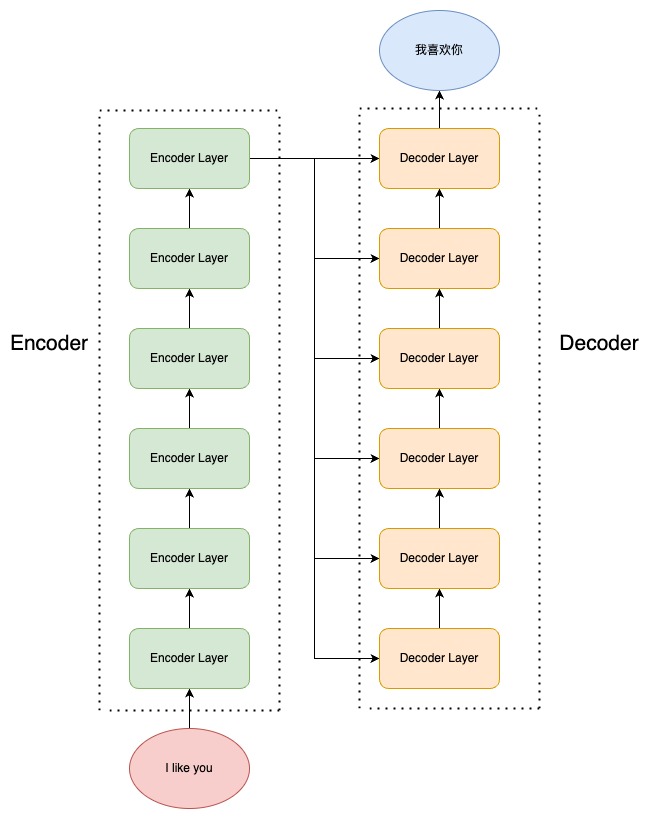
图2.5 编码器-解码器结构
 +
+ 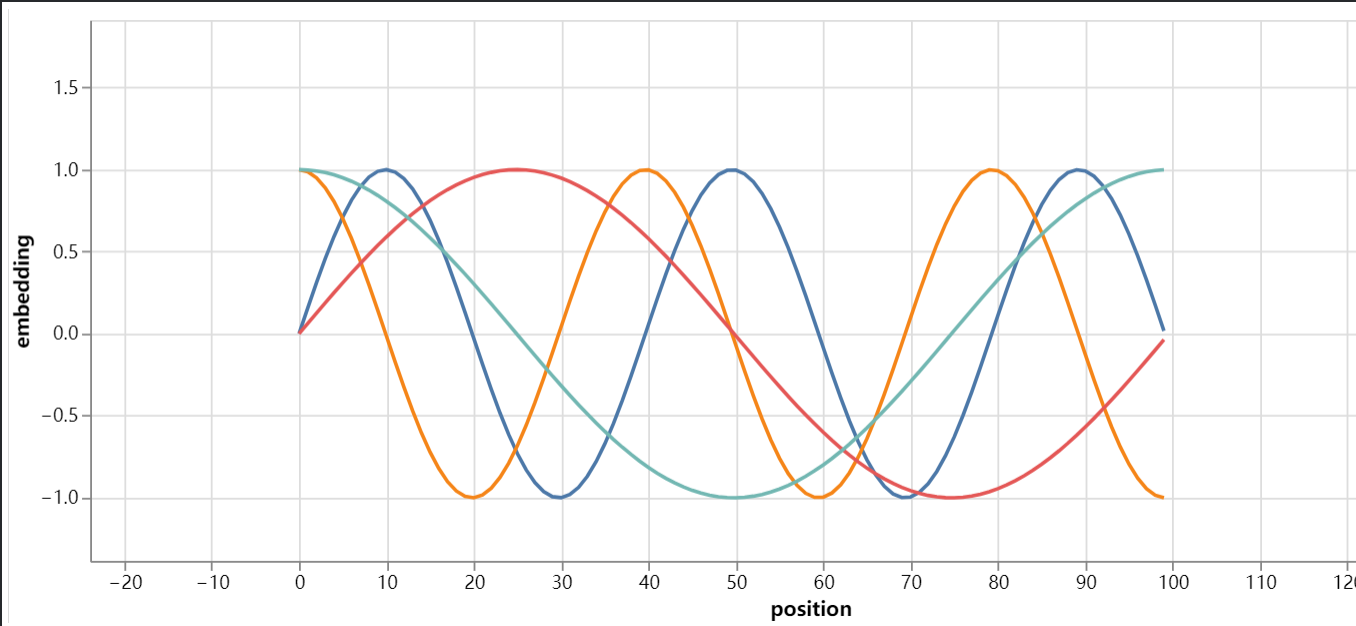
图2.6 编码结果
 +
+ 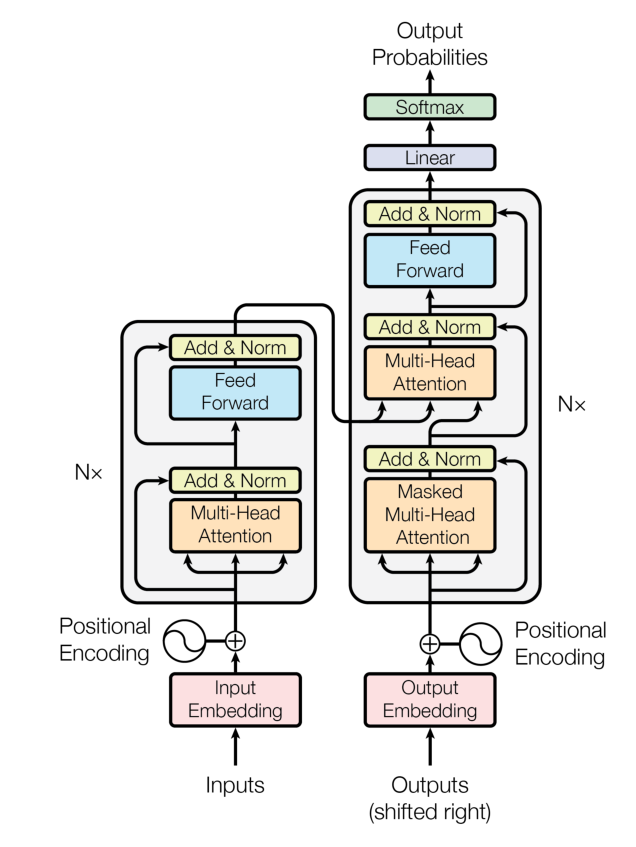
图2.7 Transformer 模型结构
 +
+ 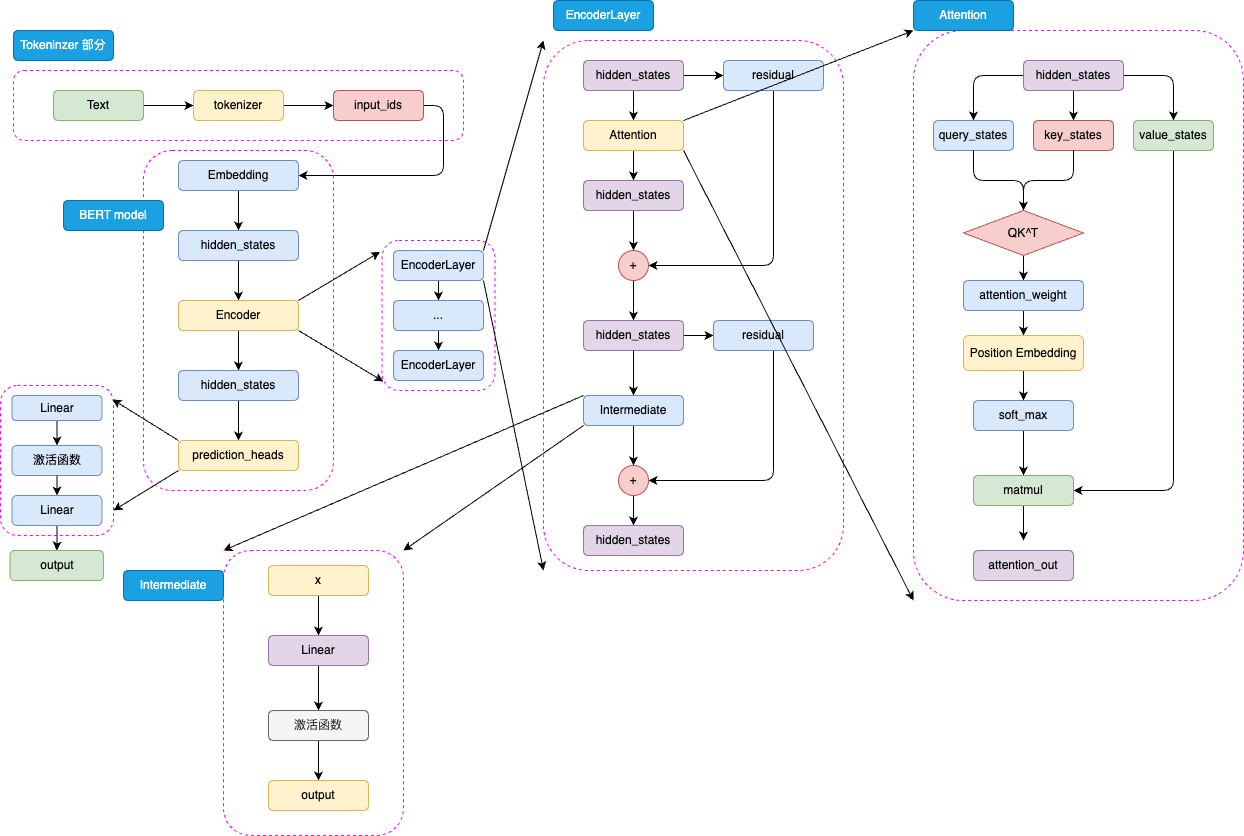
图3.1 BERT 模型结构
 +
+ 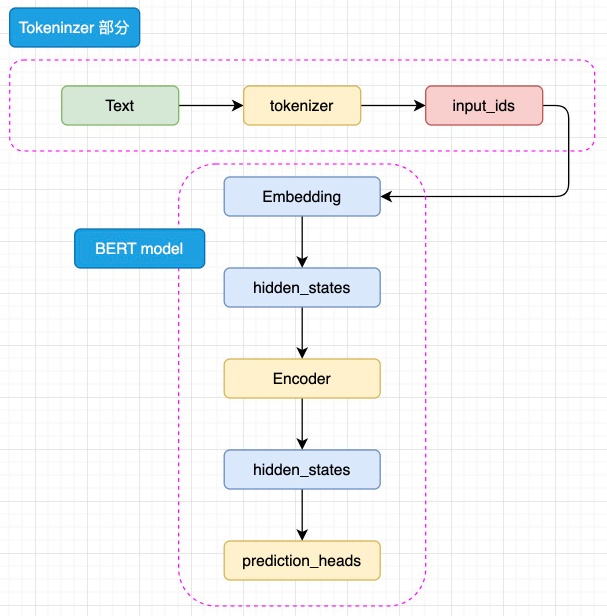
图3.2 BERT 模型简略结构
 +
+ 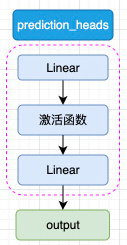
图3.3 prediction_heads 结构
 +
+ 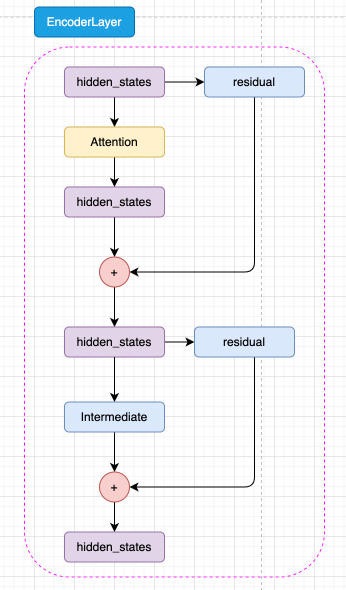
图3.4 Encoder Layer 结构
 +
+ 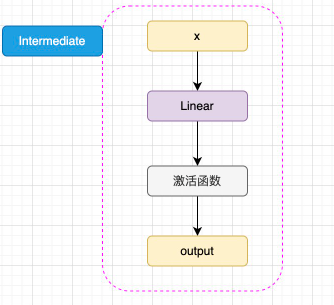
图3.5 Intermediate 结构
 +
+ 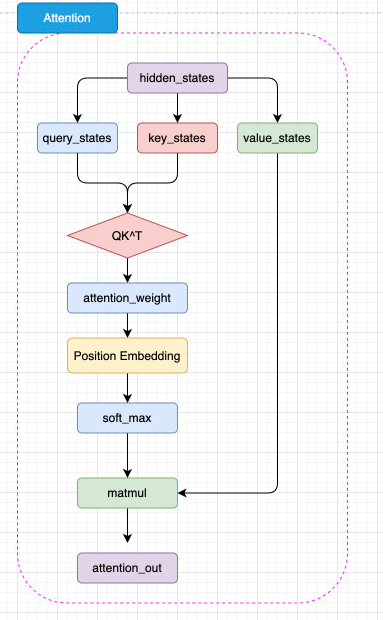
图3.6 BERT 注意力机制结构
 +
+ 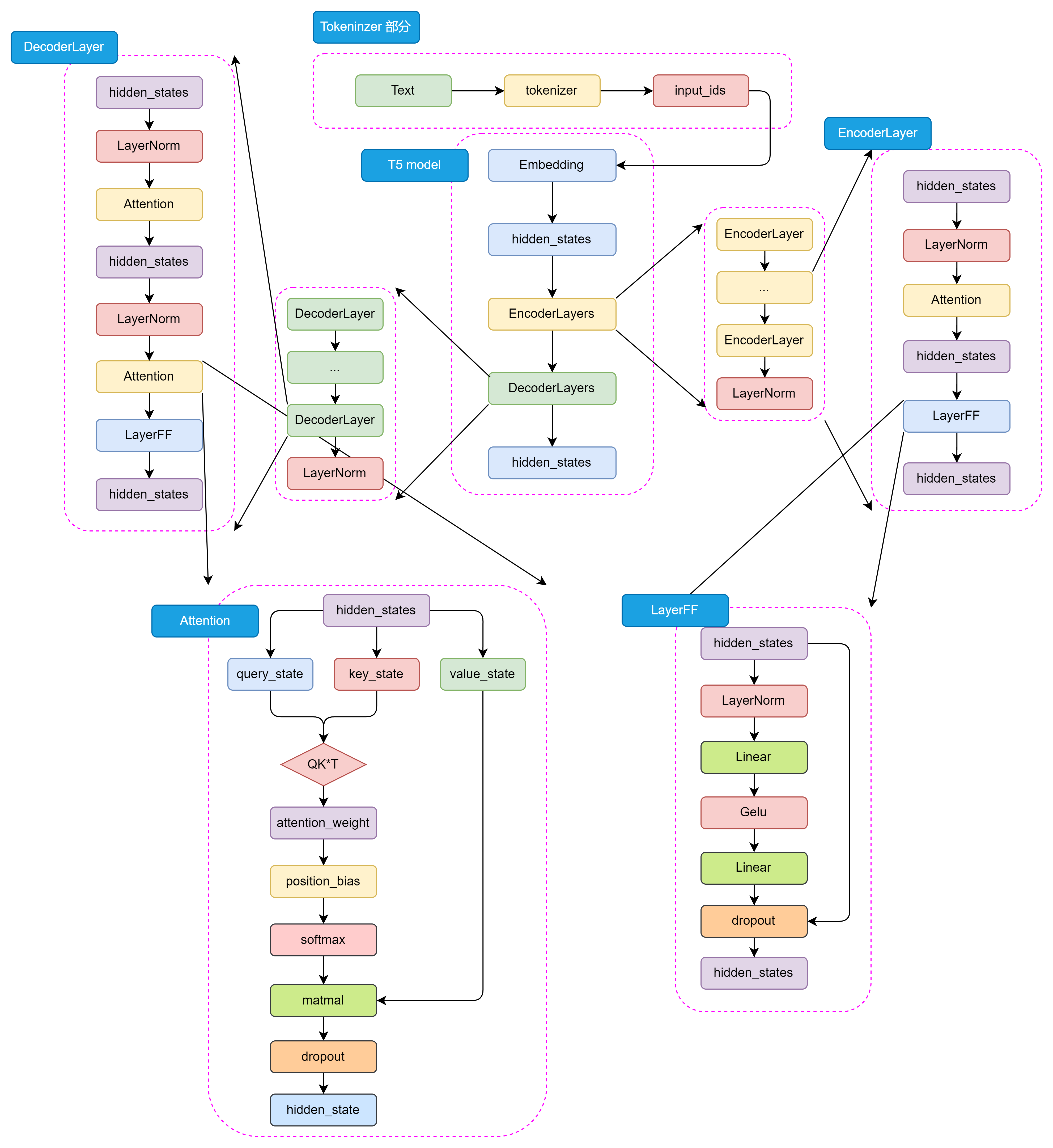
图3.7 T5 模型详细结构
 +
+ 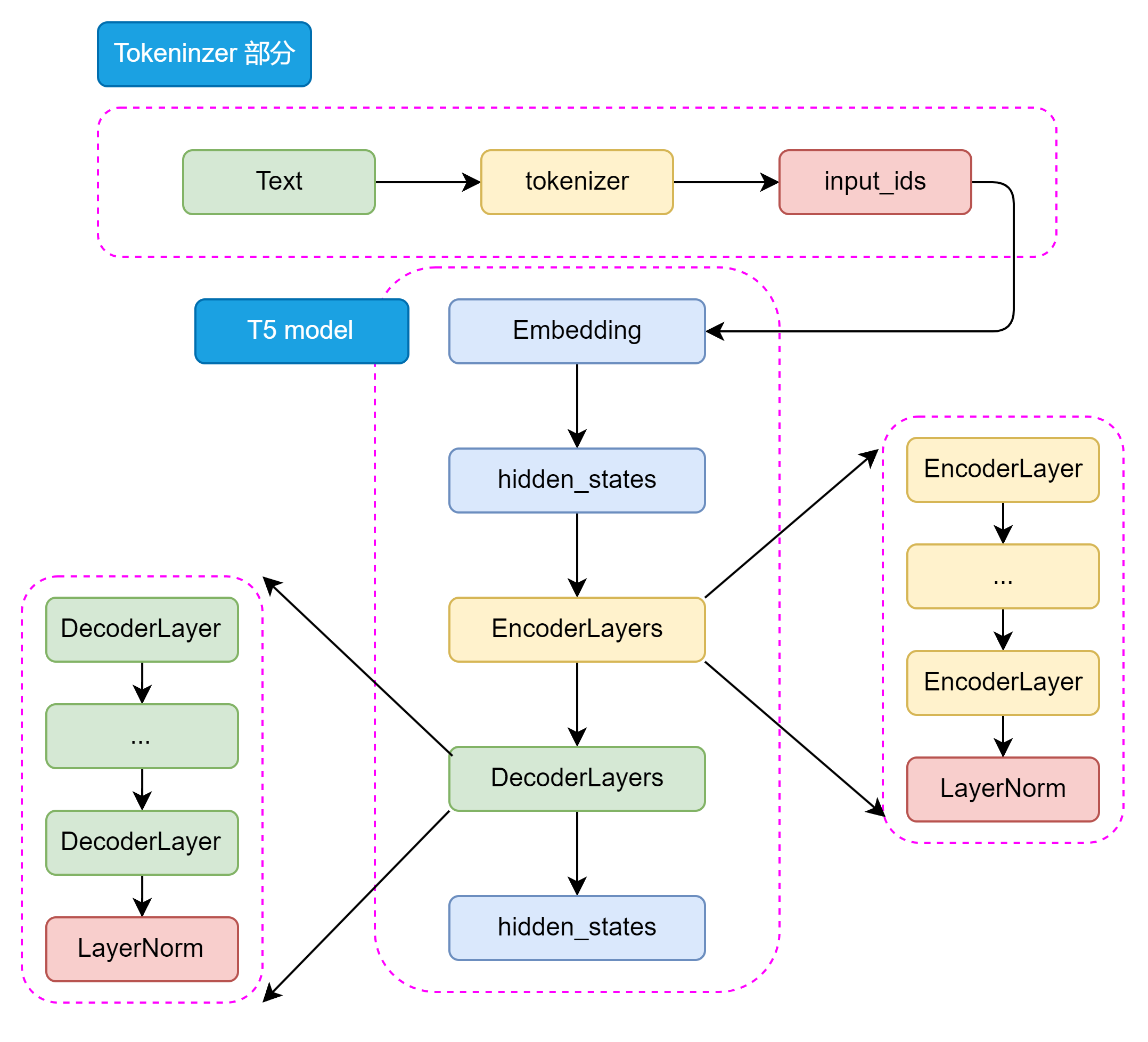
图3.8 T5 模型整体结构
 +
+ 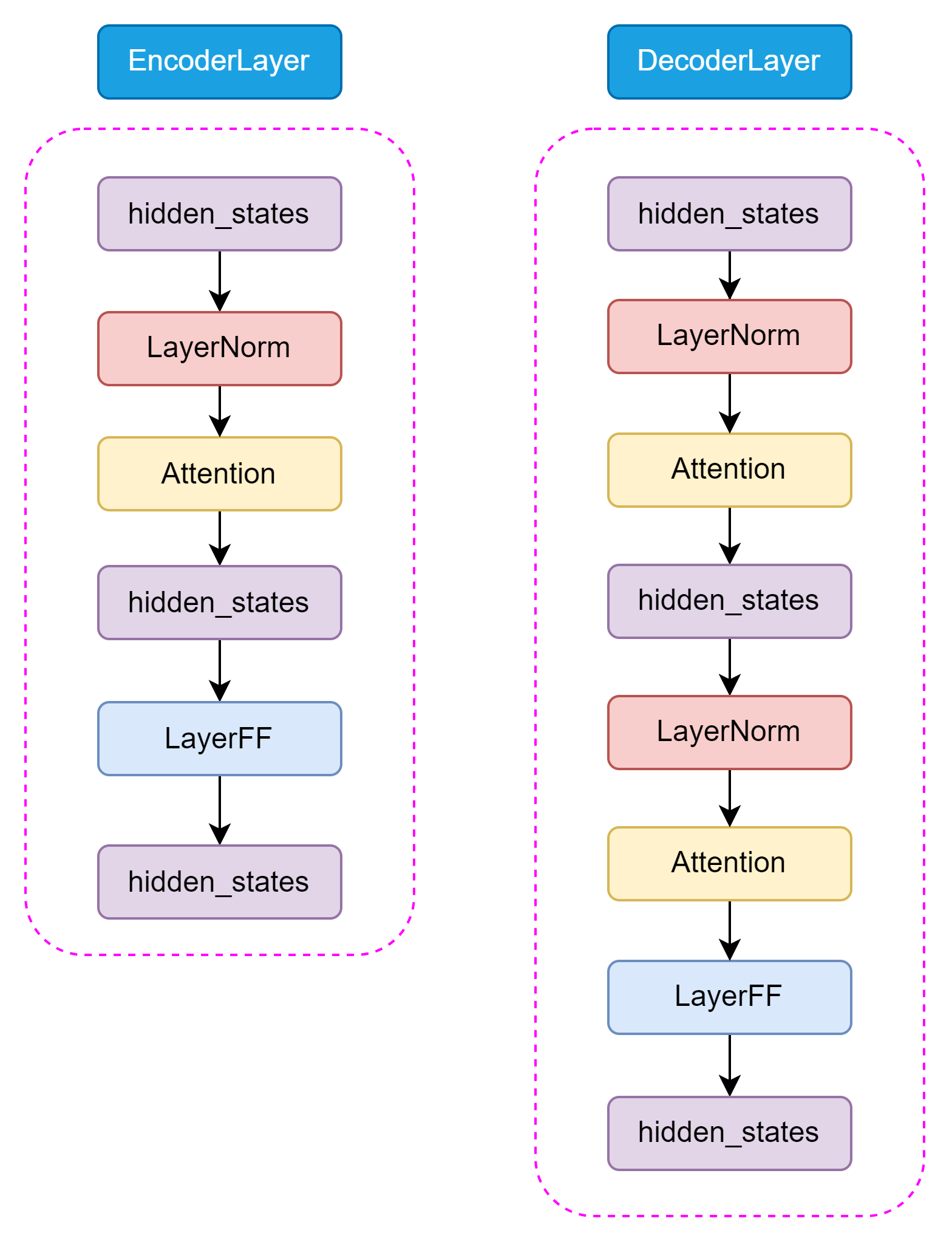
图3.9 Encoder 和 Decoder
 +
+ 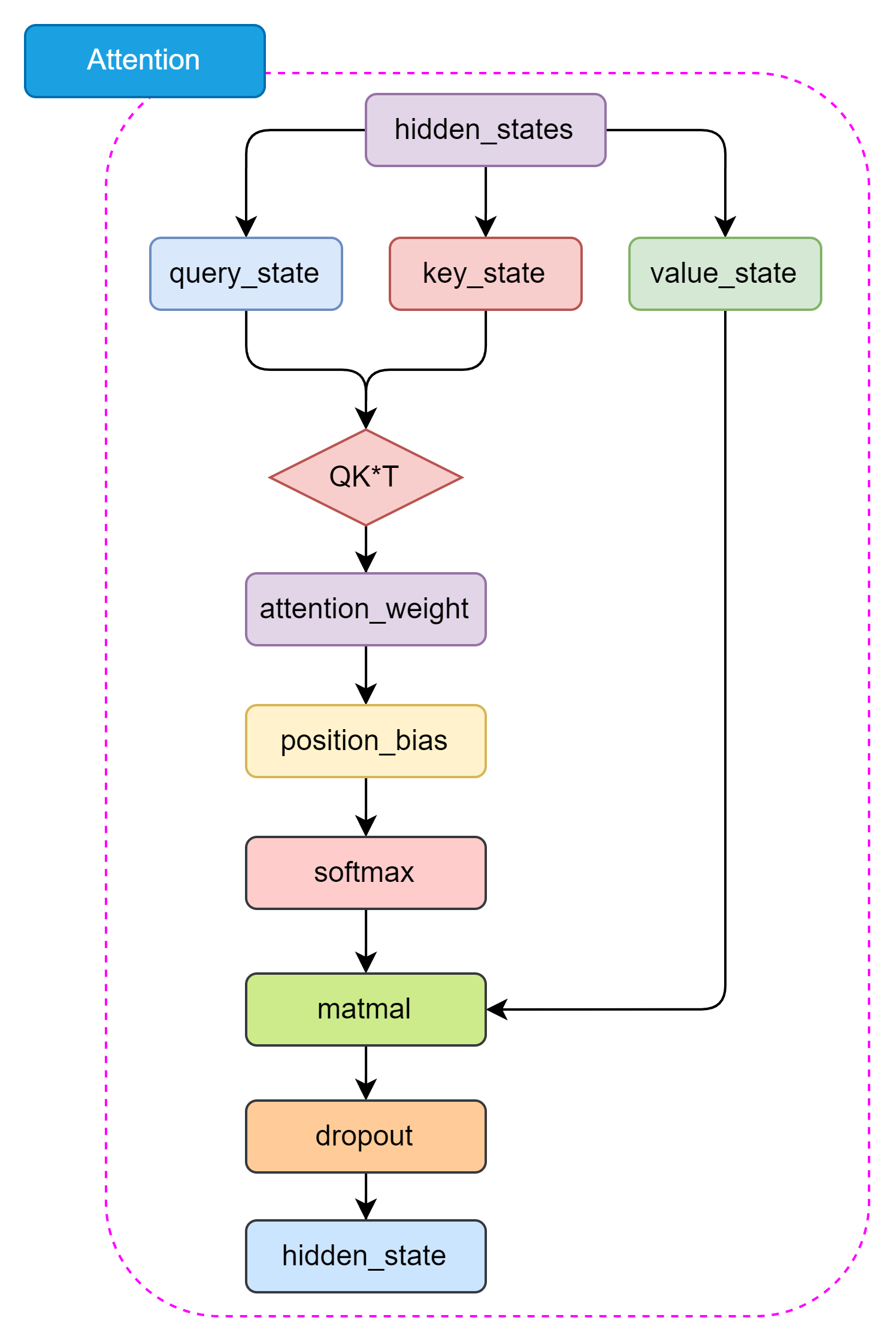 图3.10 Self-Attention 结构
图3.10 Self-Attention 结构
 +
+ 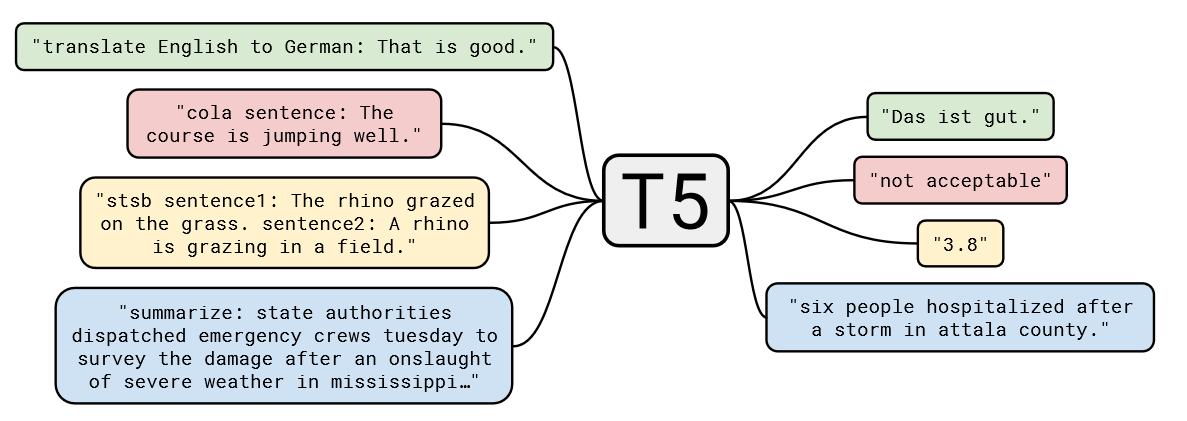
图3.11 T5 的大一统思想
 +
+ 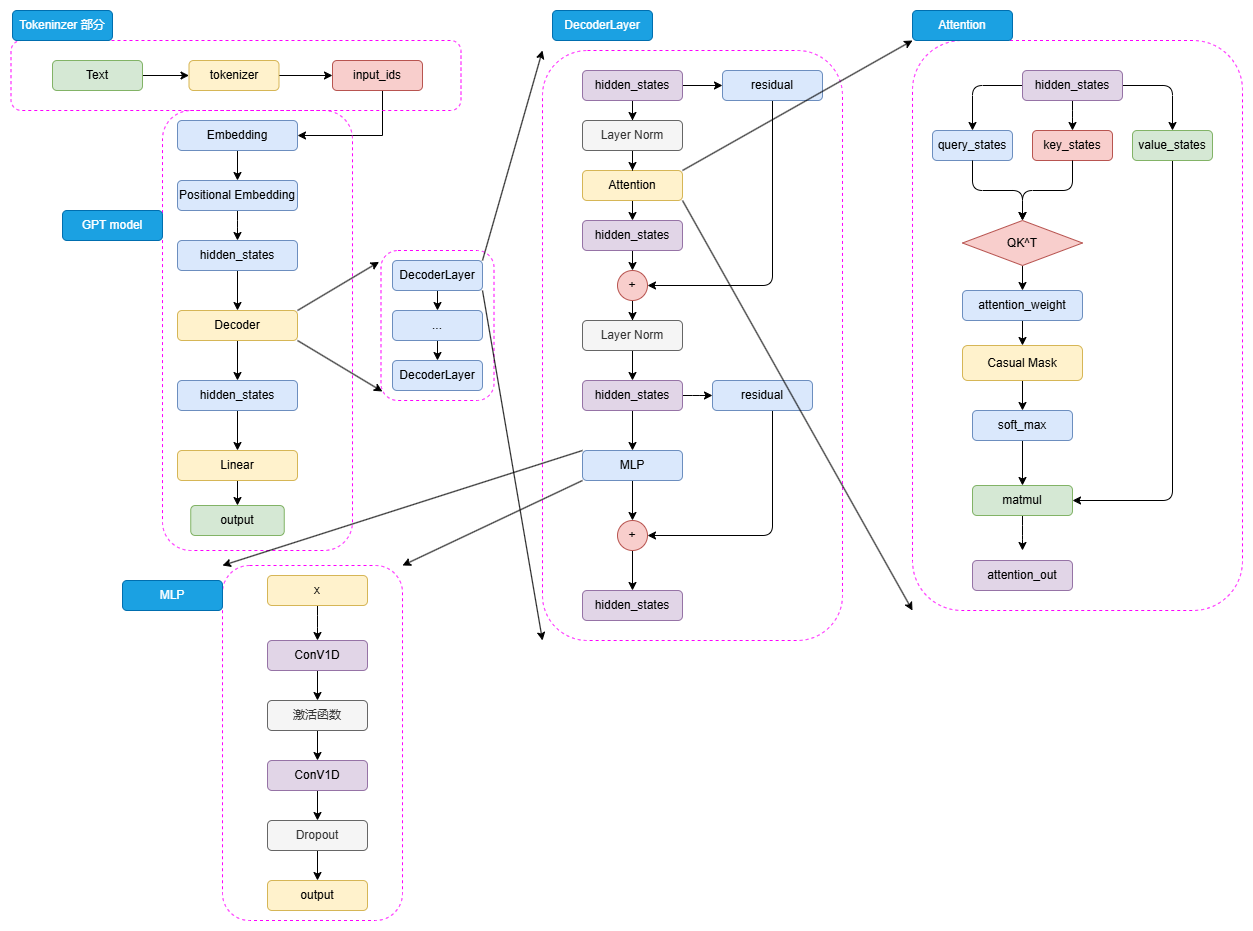
图3.12 GPT 模型结构
 +
+ 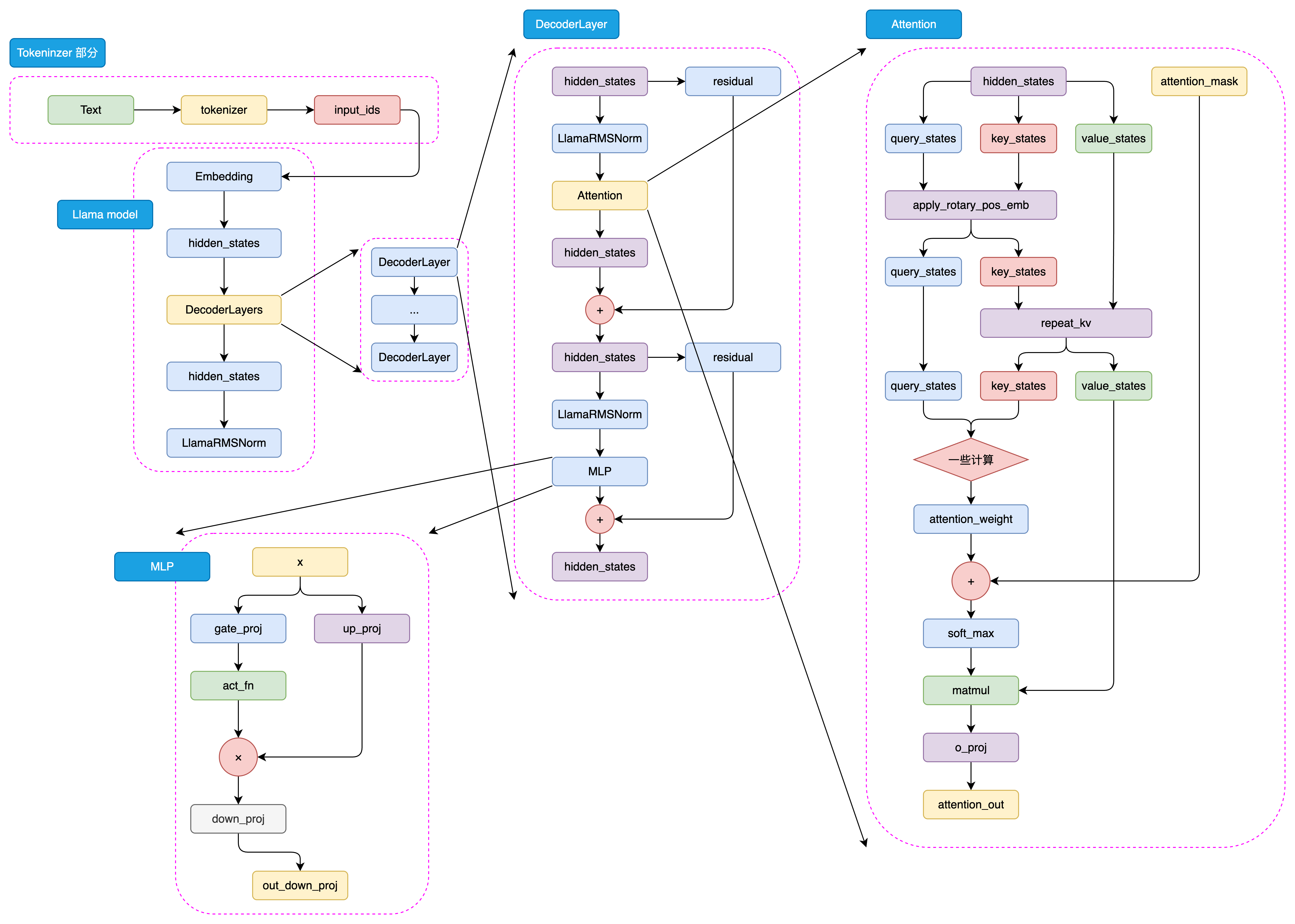
图3.13 LLaMA-3 模型结构
 +
+ 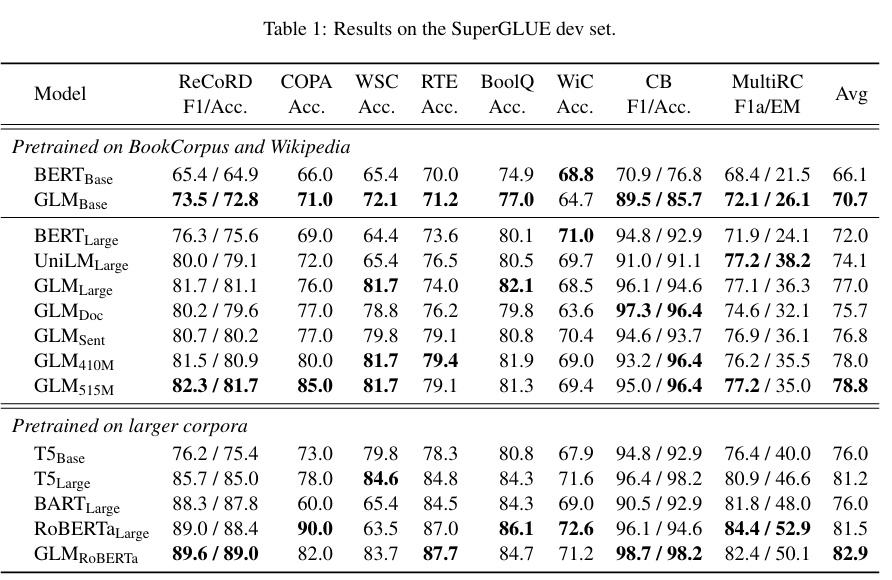
图3.14 alt text
 +
+ 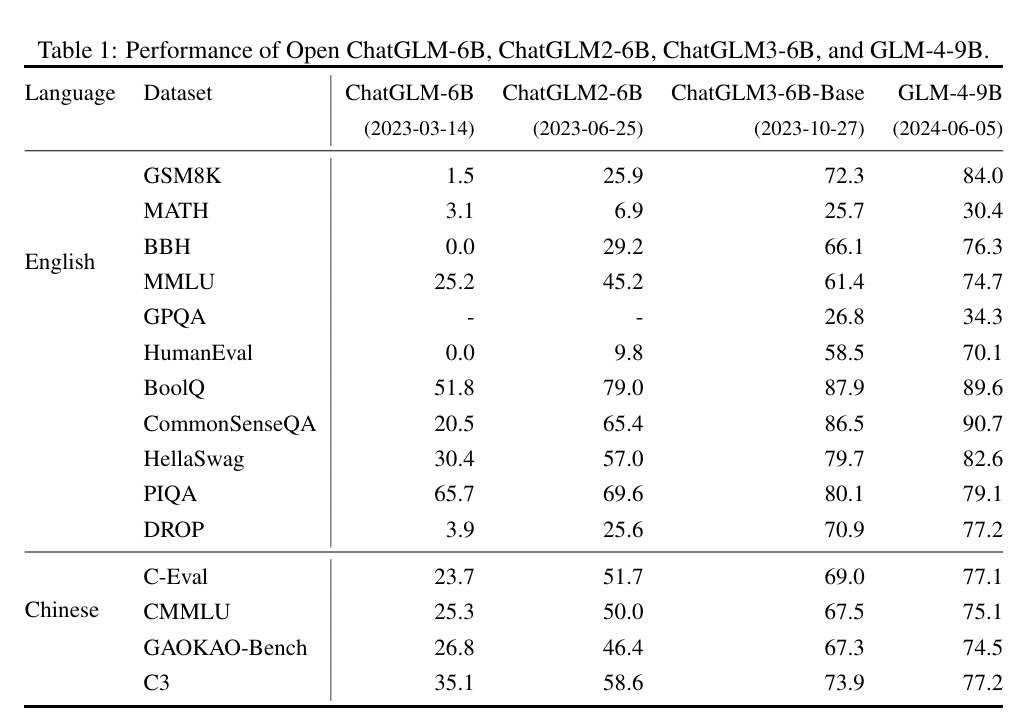
图3.15 alt text
 +
+ 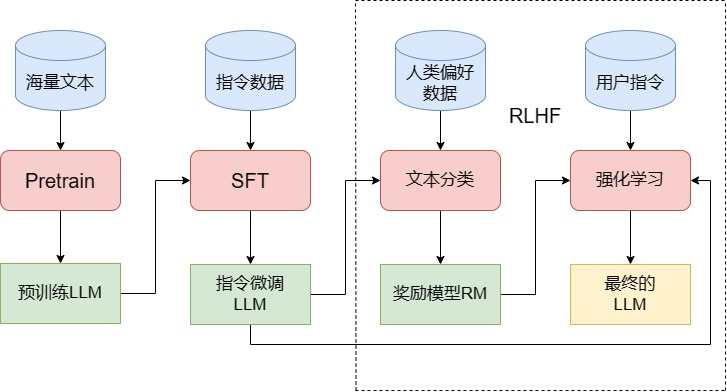
图4.1 训练 LLM 的三个阶段
 +
+ 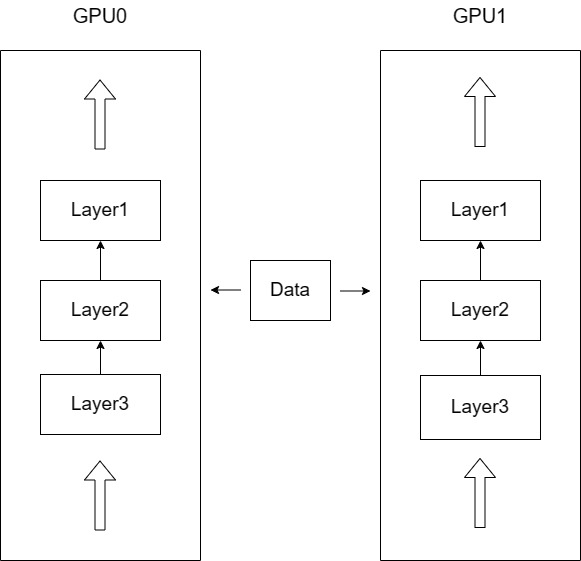
图4.2 模型、数据并行
 +
+ 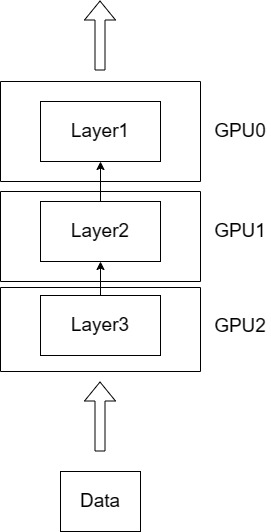
图4.3 模型并行
 +
+ 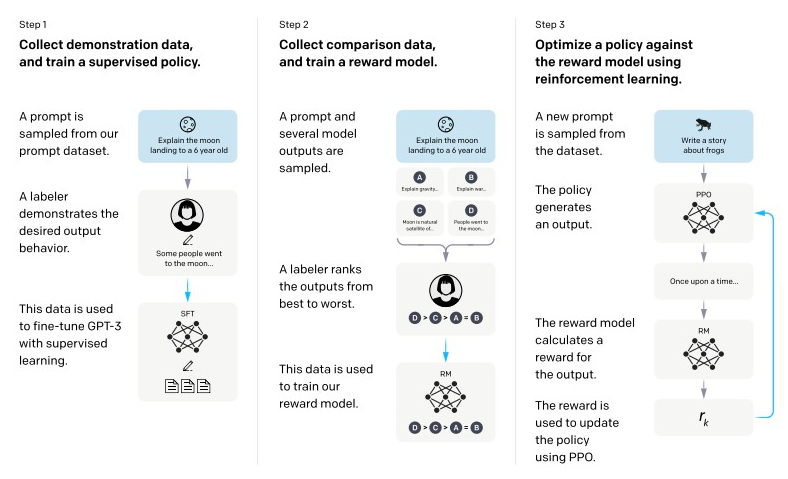
图4.4 ChatGPT 训练三个的阶段
 +
+ 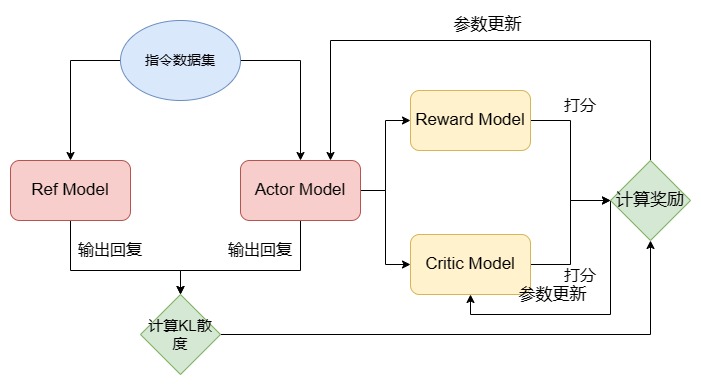
图4.5 PPO 训练流程
 +
+ 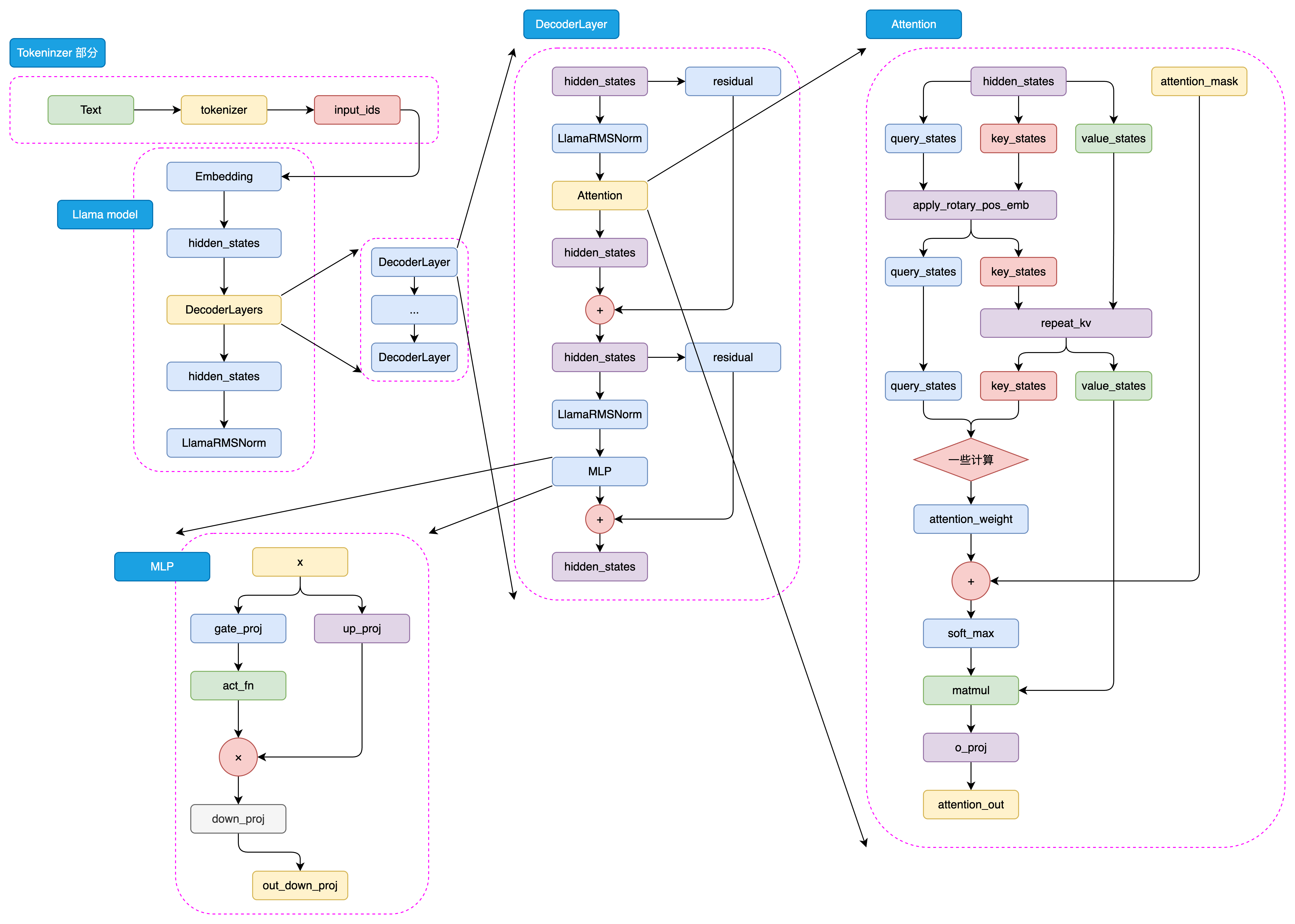
图 5.0 LLaMA2结构
 +
+ 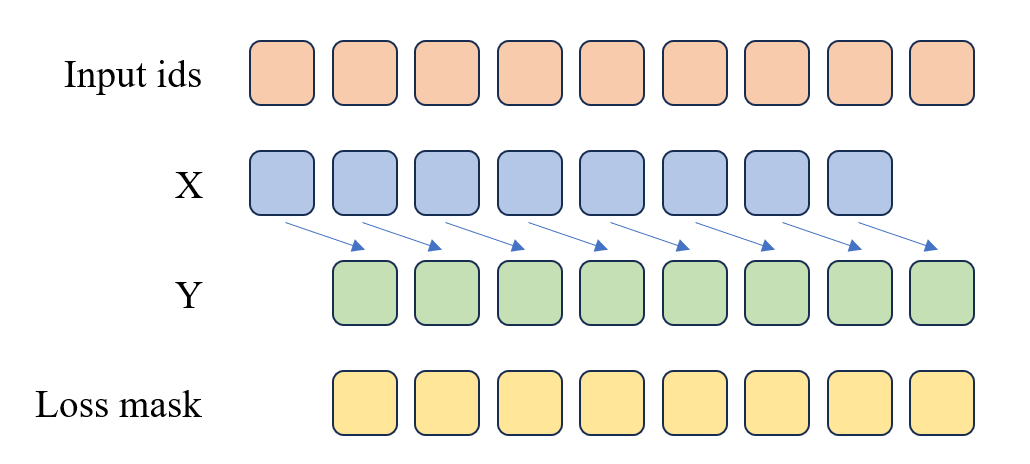
图5.1 预训练损失函数计算
 +
+ 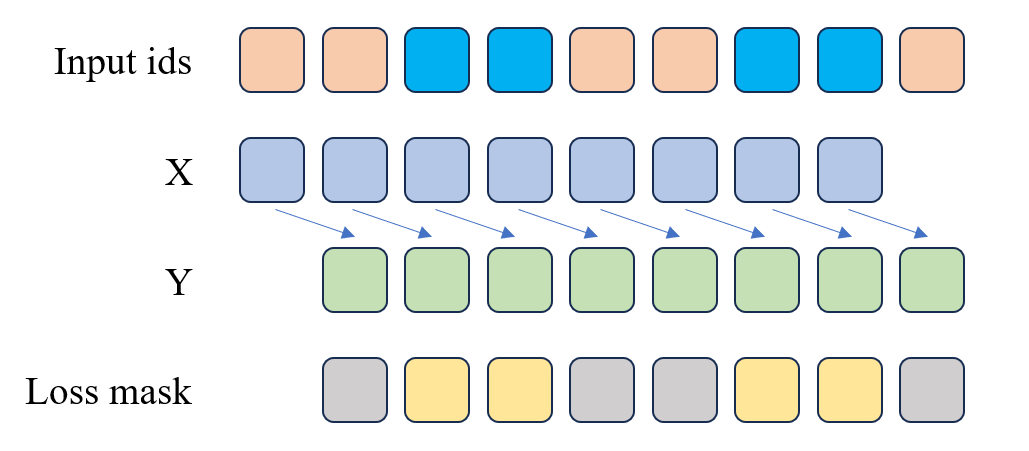
图5.2 SFT 损失函数计算
 +
+ 
图6.1 Hugging Face Transformers
 +
+ 
图6.2 Hugging Face Transformers 模型社区
 +
+ 
图6.3 Qwen-2.5-1.5B
 +
+ 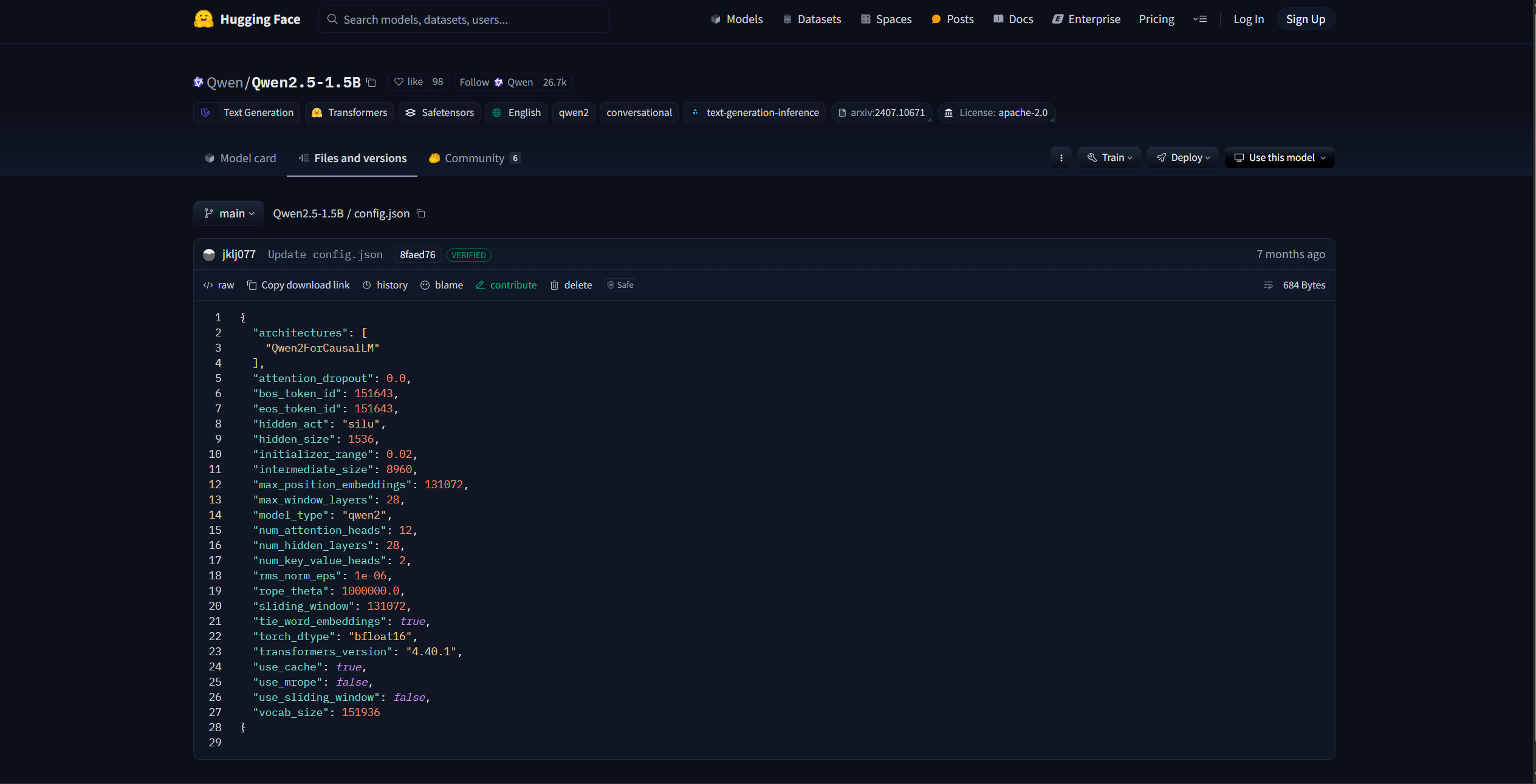
图6.4 Qwen-2.5-1.5B config.json 文件
 +
+ 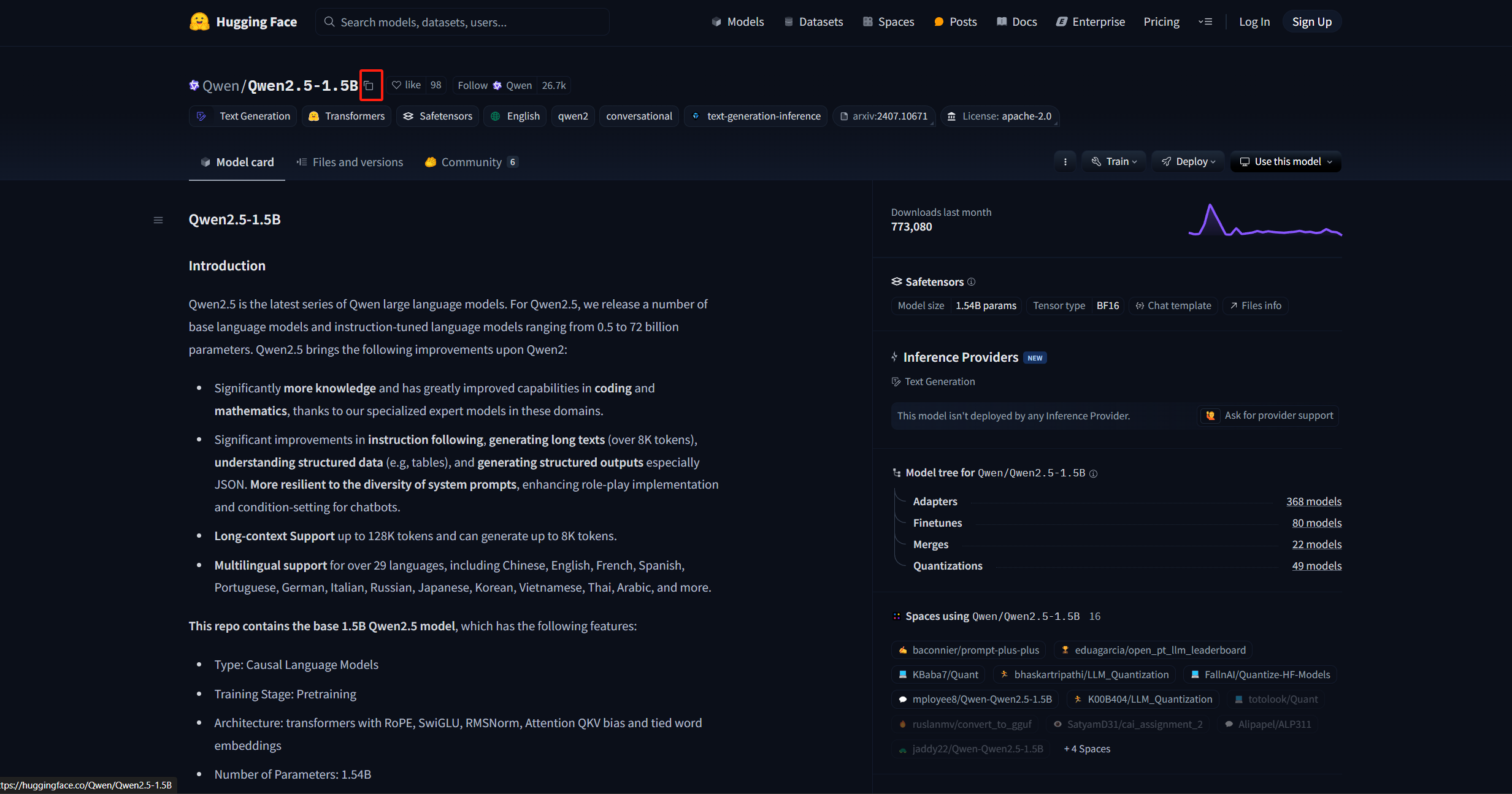
图6.5 模型下载标识
 +
+ 
图6.6 模型结构输出结果
 +
+ 
图6.7 数据集展示
 +
+ 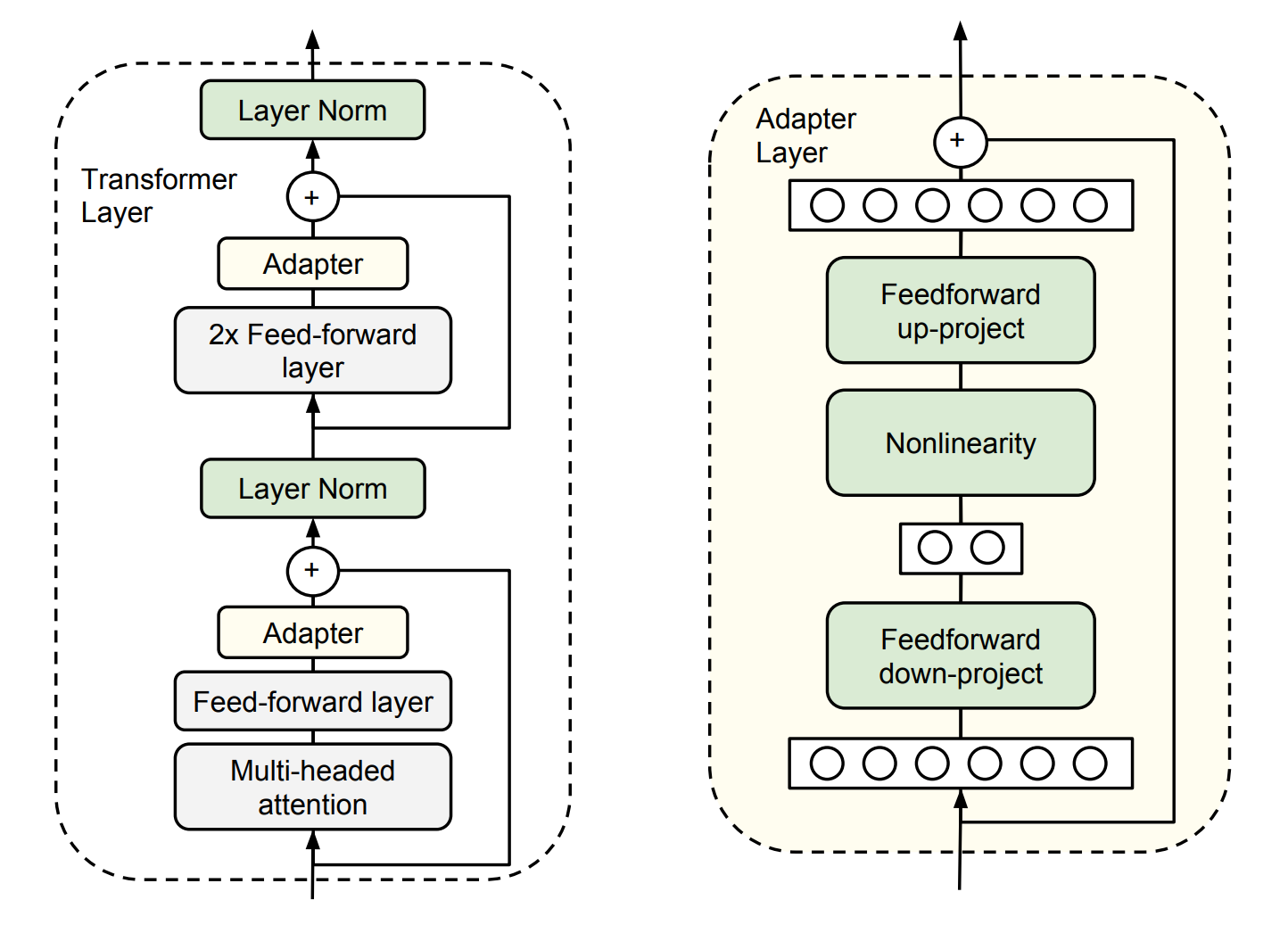
图6.8 Adapt Tuning
 +
+ 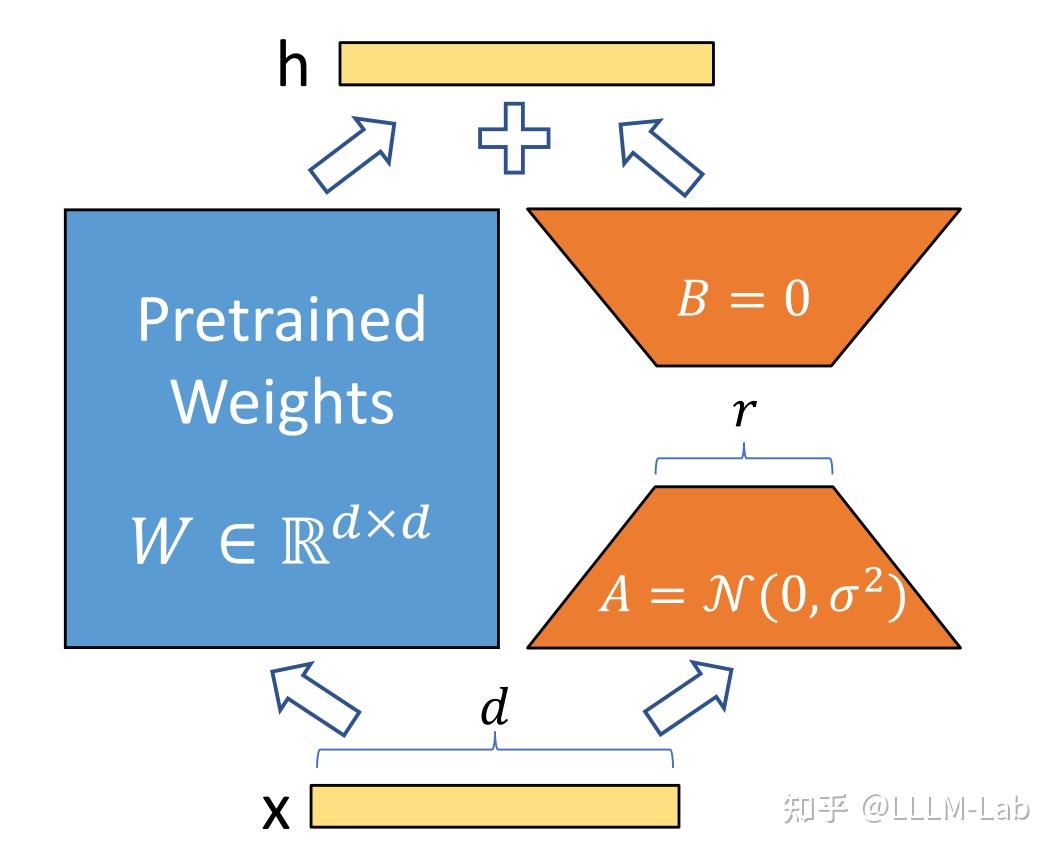
图6.9 LoRA
 +
+ 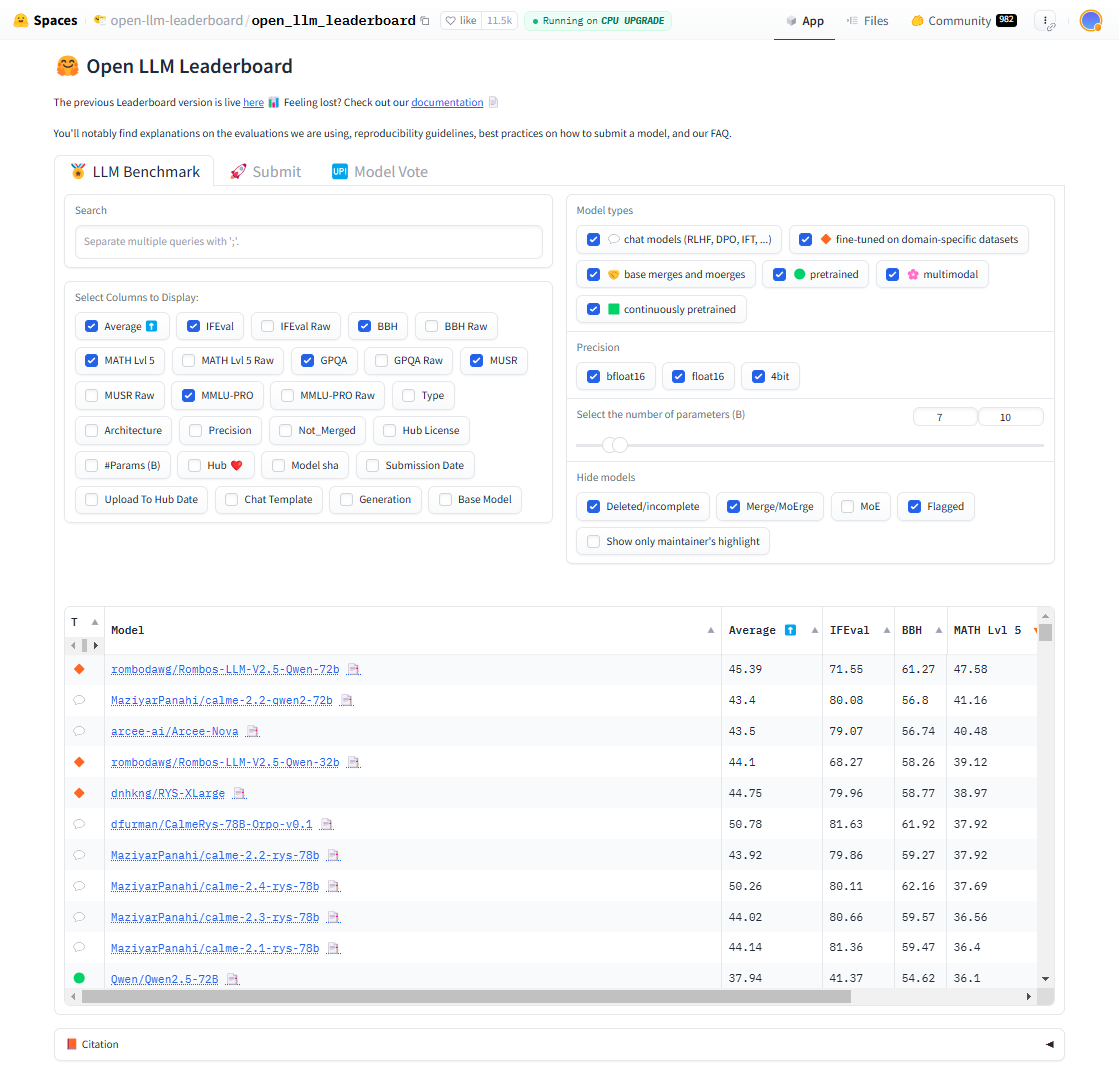
图 7.1 Open LLM Leaderboard
 +
+ 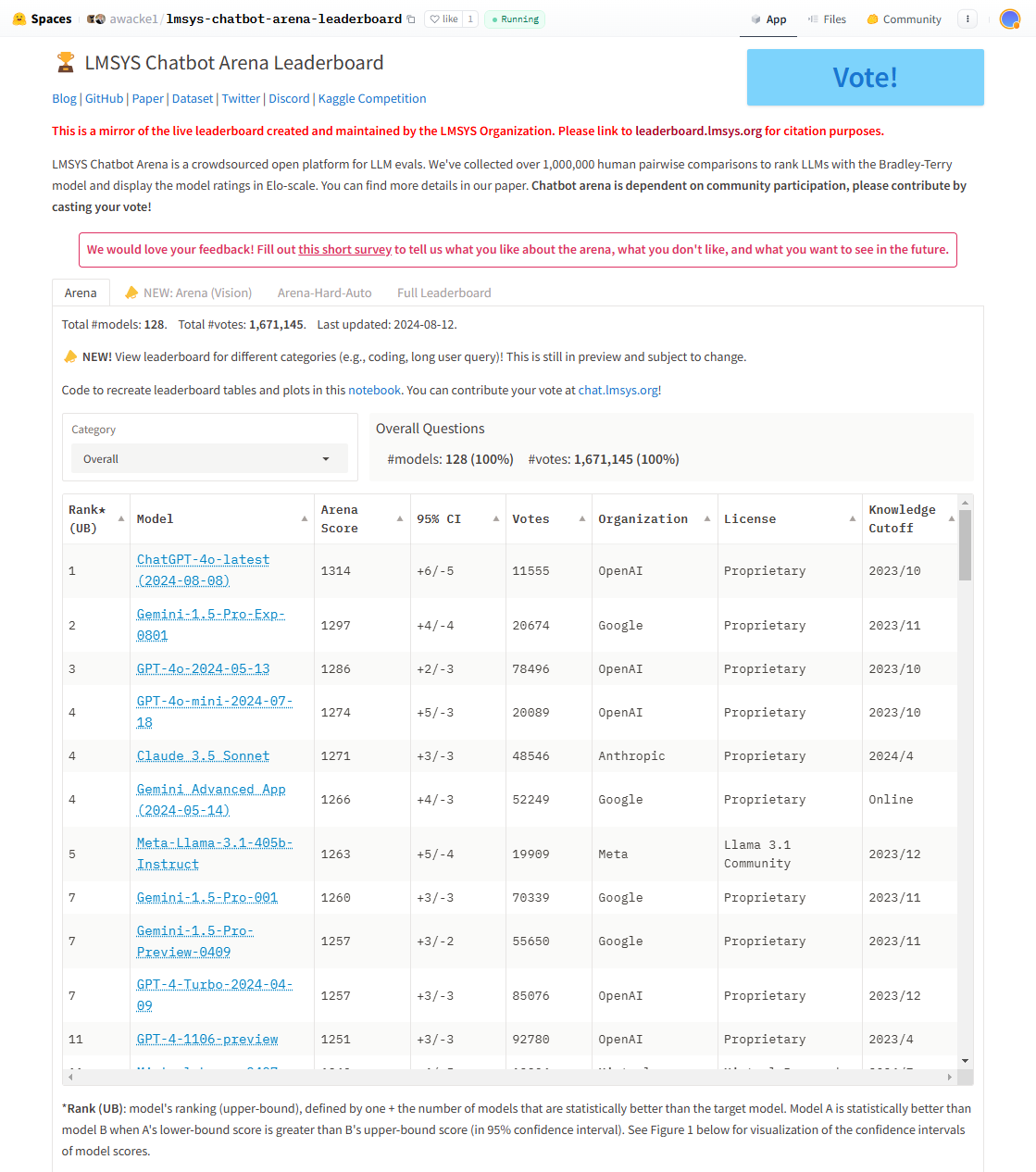
图7.2 Lmsys Chatbot Arena Leaderboard
 +
+ 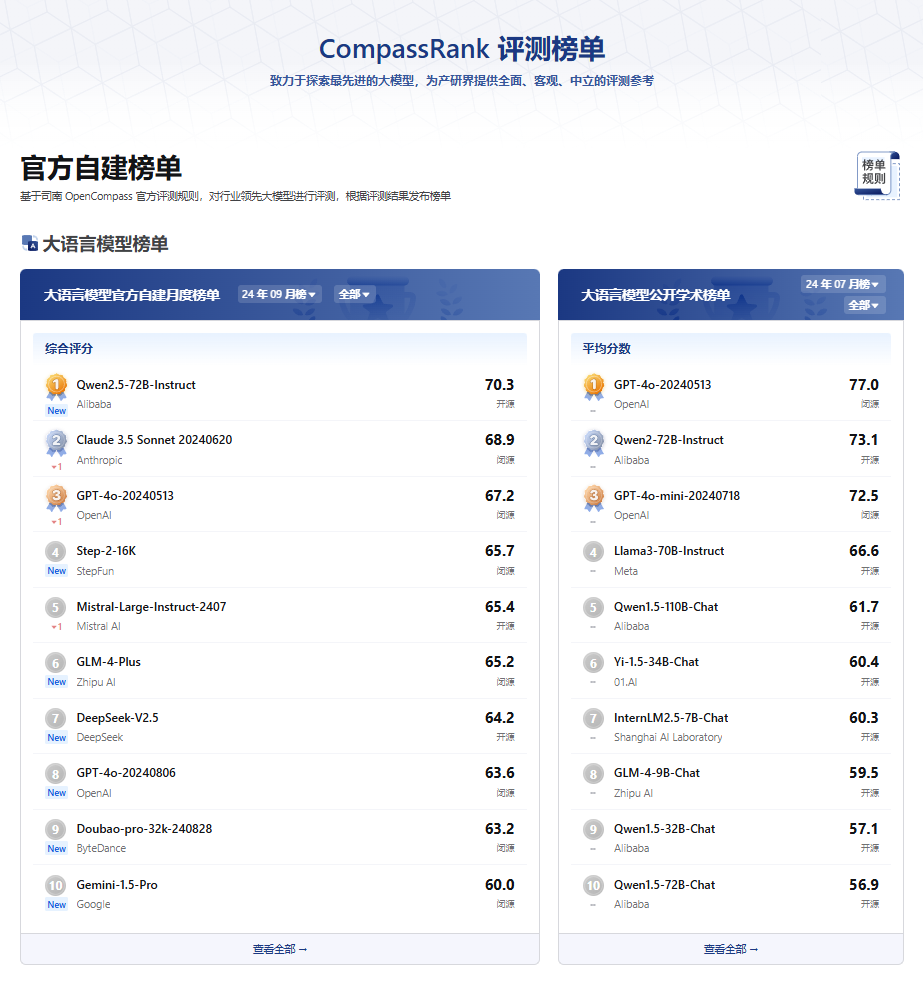
图7.3 OpenCompass
 +
+ 
图7.4 垂直领域榜单
 +
+ 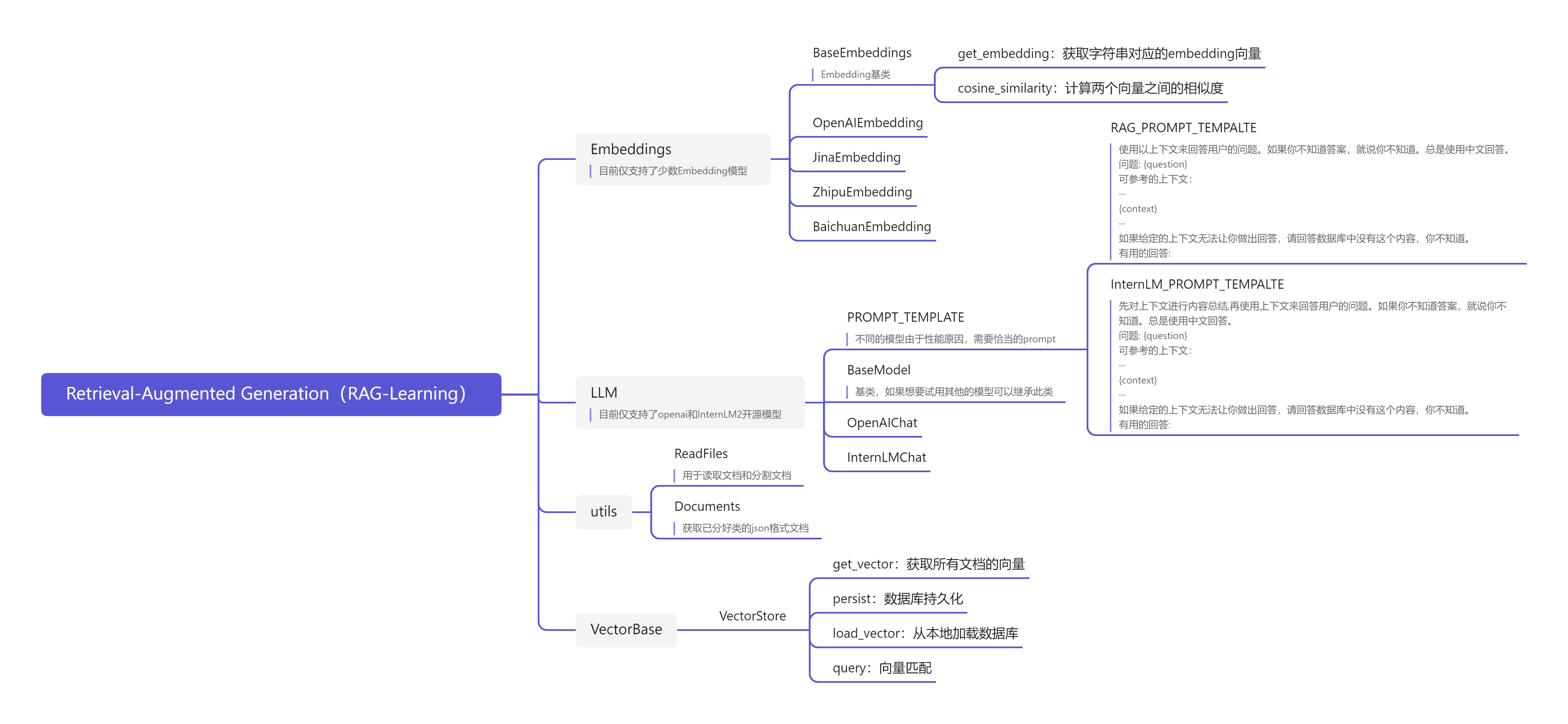
图7.5 TinyRAG 项目结构
 +
+ 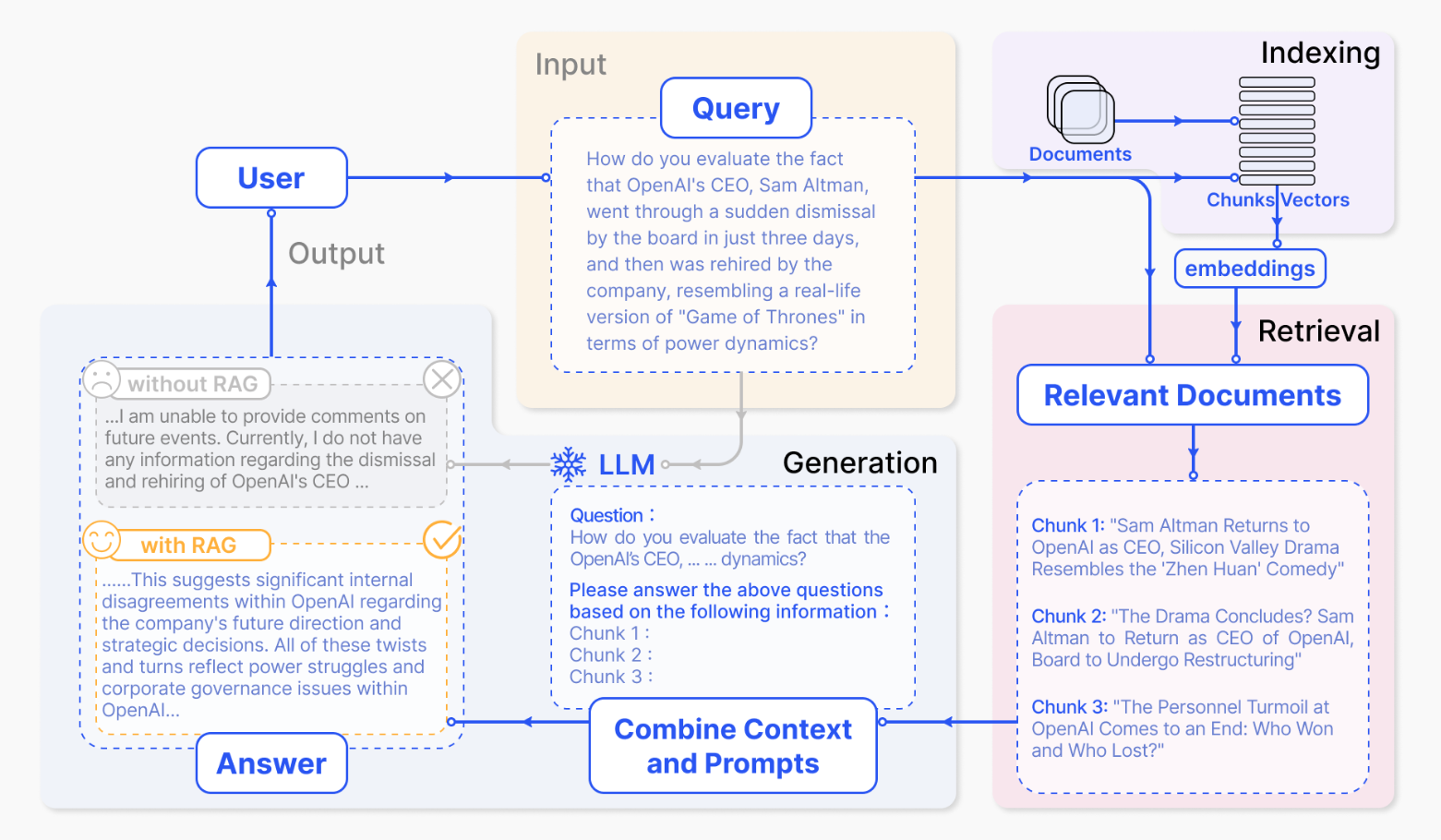
图7.6 RAG 流程图
 +
+ 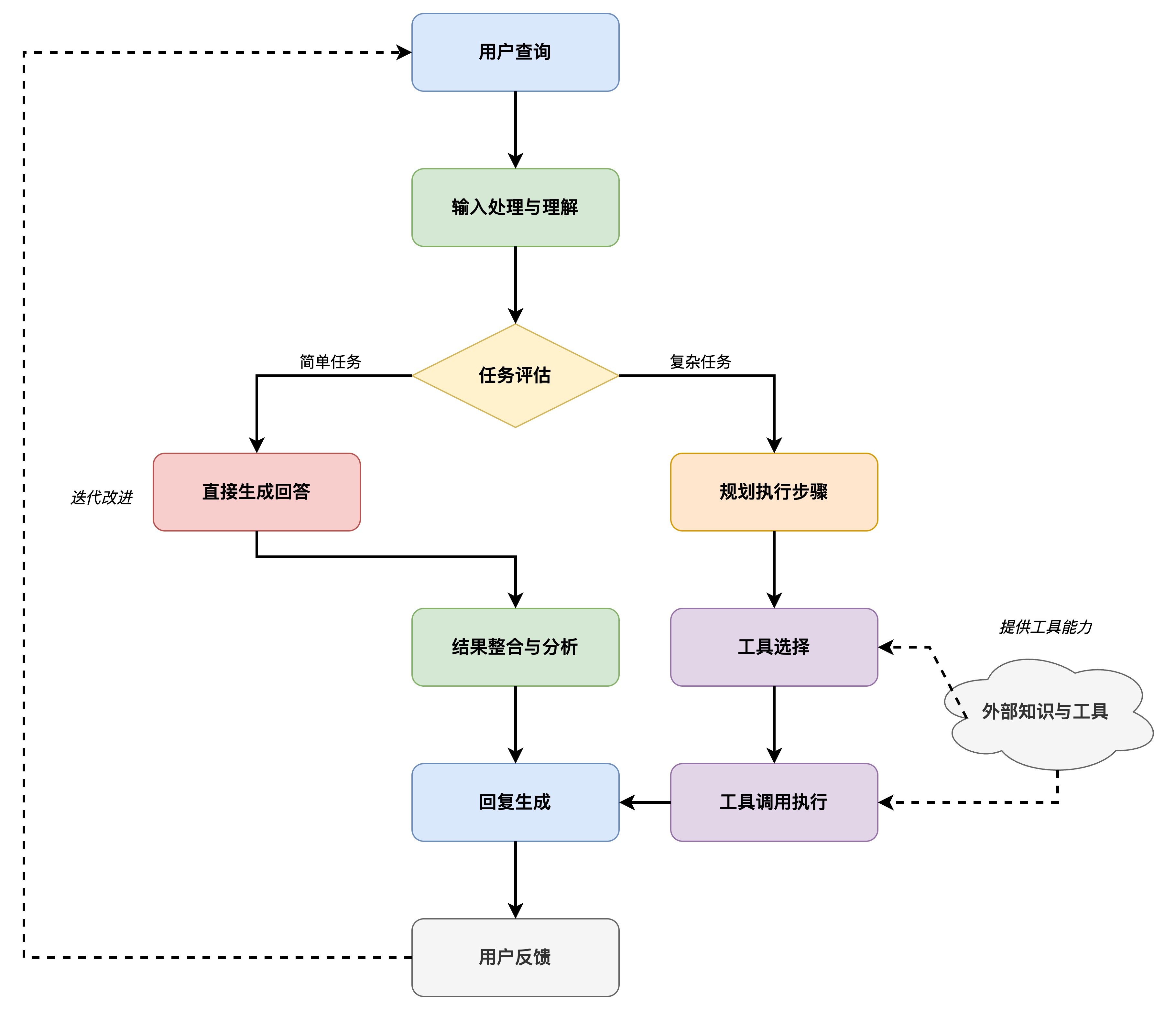
图7.7 Agent 工作原理
 +
+ 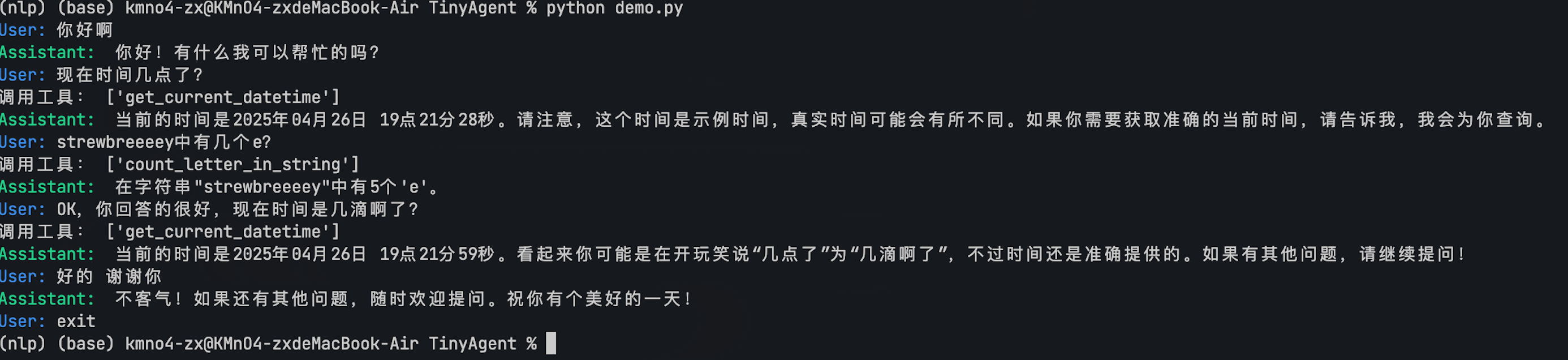
图7.8 效果示意图
 +
+ 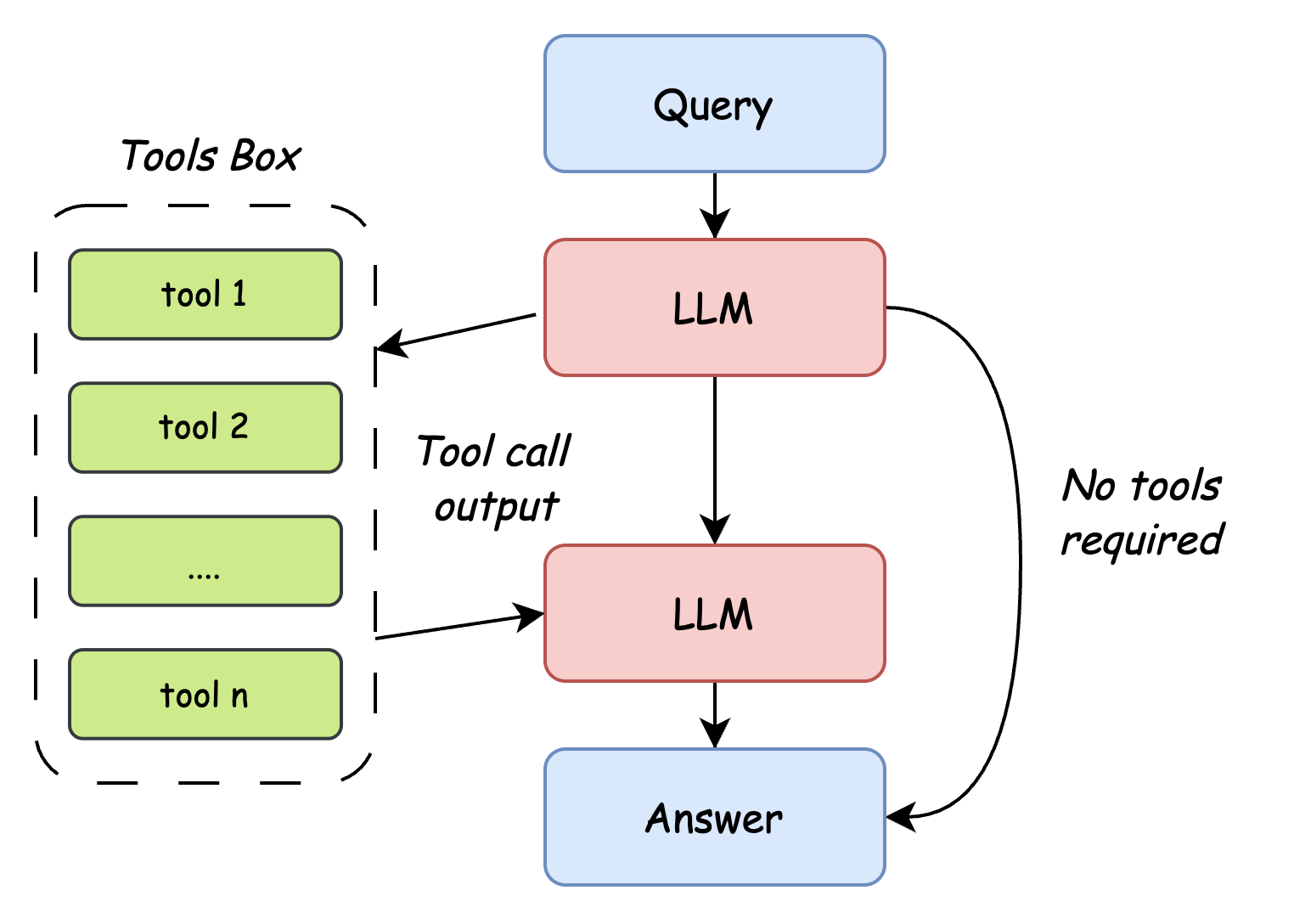
图7.9 Agent 工作流程