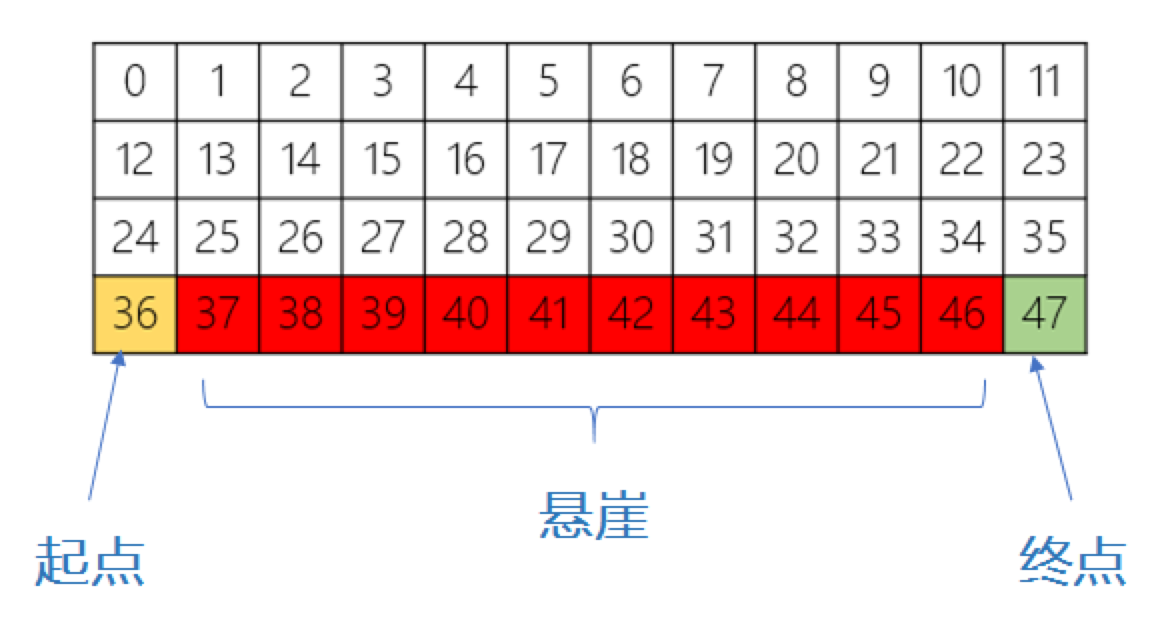
 如图,红色部分表示悬崖,数字代表智能体能够观测到的位置信息,即observation,总共会有0-47等48个不同的值,智能体再移动中会有以下限制:
* 智能体不能移出网格,如果智能体想执行某个动作移出网格,那么这一步智能体不会移动,但是这个操作依然会得到-1单位的奖励
* 如果智能体“掉入悬崖” ,会立即回到起点位置,并得到-100单位的奖励
* 当智能体移动到终点时,该回合结束,该回合总奖励为各步奖励之和
实际的仿真界面如下:
如图,红色部分表示悬崖,数字代表智能体能够观测到的位置信息,即observation,总共会有0-47等48个不同的值,智能体再移动中会有以下限制:
* 智能体不能移出网格,如果智能体想执行某个动作移出网格,那么这一步智能体不会移动,但是这个操作依然会得到-1单位的奖励
* 如果智能体“掉入悬崖” ,会立即回到起点位置,并得到-100单位的奖励
* 当智能体移动到终点时,该回合结束,该回合总奖励为各步奖励之和
实际的仿真界面如下:
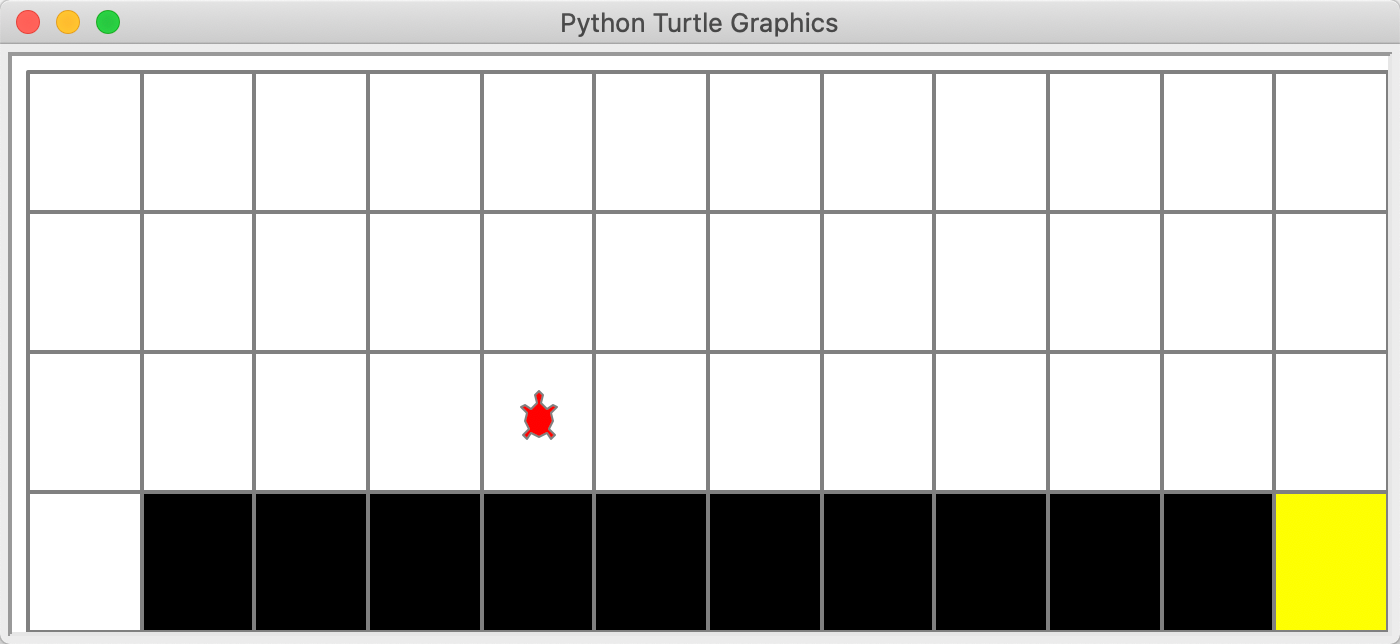 由于从起点到终点最少需要13步,每步得到-1的reward,因此最佳训练算法下,每个episode下reward总和应该为-13。
由于从起点到终点最少需要13步,每步得到-1的reward,因此最佳训练算法下,每个episode下reward总和应该为-13。