# 使用Q-learning解决悬崖寻路问题
## CliffWalking-v0环境简介
悬崖寻路问题(CliffWalking)是指在一个4 x 12的网格中,智能体以网格的左下角位置为起点,以网格的下角位置为终点,目标是移动智能体到达终点位置,智能体每次可以在上、下、左、右这4个方向中移动一步,每移动一步会得到-1单位的奖励。
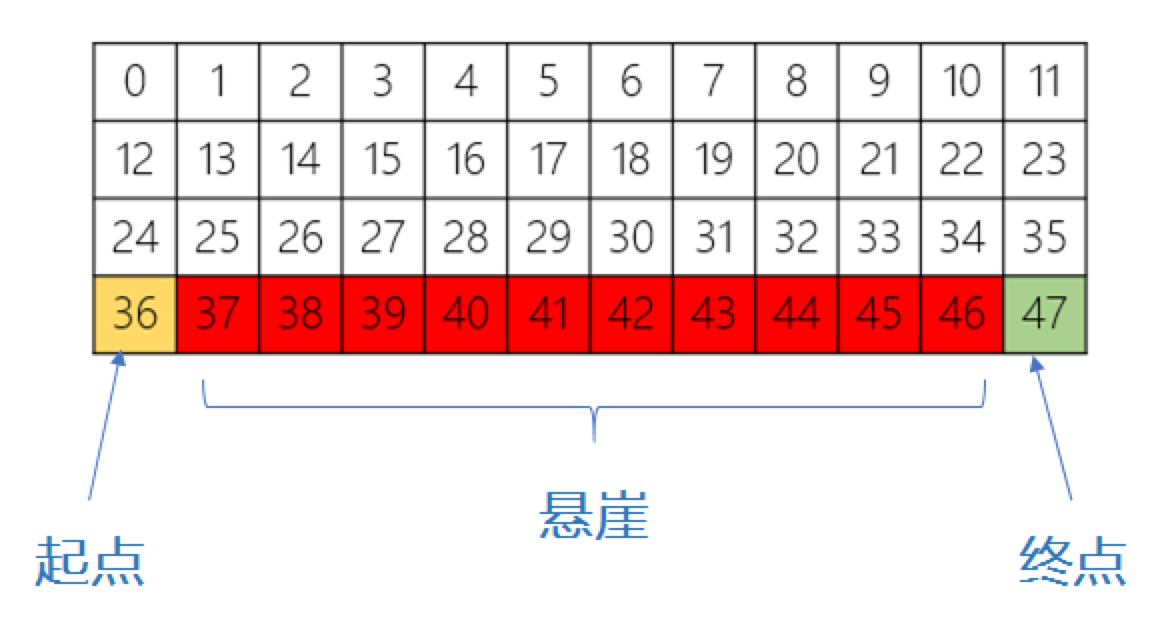 如图,红色部分表示悬崖,数字代表智能体能够观测到的位置信息,即observation,总共会有0-47等48个不同的值,智能体再移动中会有以下限制:
* 智能体不能移出网格,如果智能体想执行某个动作移出网格,那么这一步智能体不会移动,但是这个操作依然会得到-1单位的奖励
* 如果智能体“掉入悬崖” ,会立即回到起点位置,并得到-100单位的奖励
* 当智能体移动到终点时,该回合结束,该回合总奖励为各步奖励之和
实际的仿真界面如下:
如图,红色部分表示悬崖,数字代表智能体能够观测到的位置信息,即observation,总共会有0-47等48个不同的值,智能体再移动中会有以下限制:
* 智能体不能移出网格,如果智能体想执行某个动作移出网格,那么这一步智能体不会移动,但是这个操作依然会得到-1单位的奖励
* 如果智能体“掉入悬崖” ,会立即回到起点位置,并得到-100单位的奖励
* 当智能体移动到终点时,该回合结束,该回合总奖励为各步奖励之和
实际的仿真界面如下:
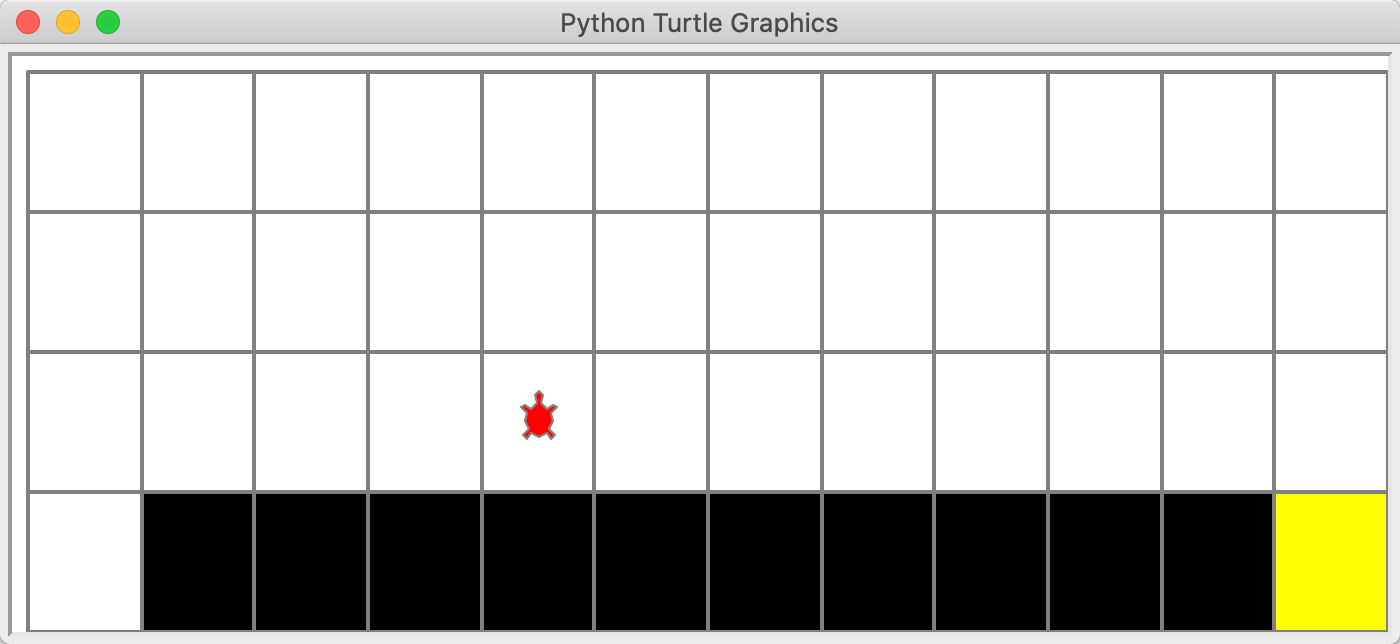 **由于从起点到终点最少需要13步,每步得到-1的reward,因此最佳训练算法下,每个episode下reward总和应该为-13**。
## RL基本训练接口
```python
env = gym.make("CliffWalking-v0") # 0 up, 1 right, 2 down, 3 left
env = CliffWalkingWapper(env)
agent = QLearning(
obs_dim=env.observation_space.n,
action_dim=env.action_space.n,
learning_rate=cfg.policy_lr,
gamma=cfg.gamma,
epsilon_start=cfg.epsilon_start,epsilon_end=cfg.epsilon_end,epsilon_decay=cfg.epsilon_decay)
render = False # 是否打开GUI画面
rewards = [] # 记录所有episode的reward
MA_rewards = [] # 记录滑动平均的reward
steps = []# 记录所有episode的steps
for i_episode in range(1,cfg.max_episodes+1):
ep_reward = 0 # 记录每个episode的reward
ep_steps = 0 # 记录每个episode走了多少step
obs = env.reset() # 重置环境, 重新开一局(即开始新的一个episode)
while True:
action = agent.sample(obs) # 根据算法选择一个动作
next_obs, reward, done, _ = env.step(action) # 与环境进行一个交互
# 训练 Q-learning算法
agent.learn(obs, action, reward, next_obs, done) # 不需要下一步的action
obs = next_obs # 存储上一个观察值
ep_reward += reward
ep_steps += 1 # 计算step数
if render:
env.render() #渲染新的一帧图形
if done:
break
steps.append(ep_steps)
rewards.append(ep_reward)
# 计算滑动平均的reward
if i_episode == 1:
MA_rewards.append(ep_reward)
else:
MA_rewards.append(
0.9*MA_rewards[-1]+0.1*ep_reward)
print('Episode %s: steps = %s , reward = %.1f, explore = %.2f' % (i_episode, ep_steps,
ep_reward,agent.epsilon))
# 每隔20个episode渲染一下看看效果
if i_episode % 20 == 0:
render = True
else:
render = False
agent.save() # 训练结束,保存模型
```
## 任务要求
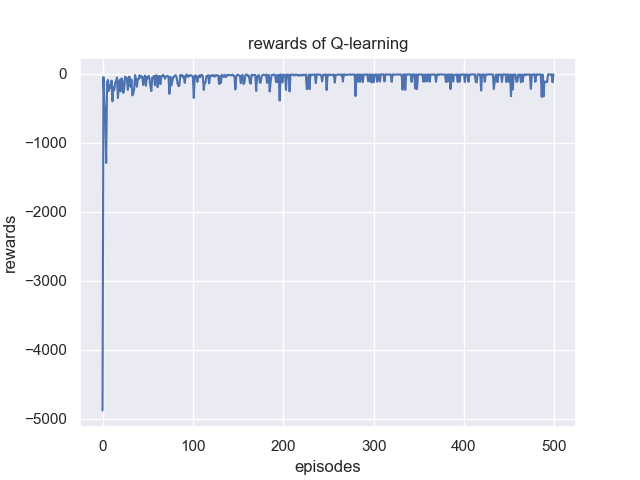
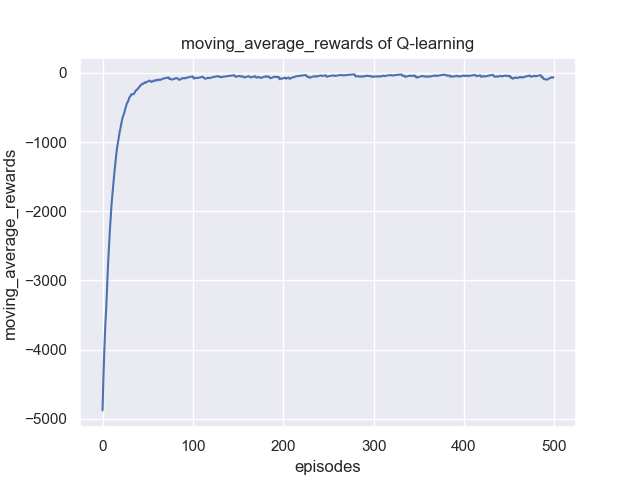
训练并绘制reward以及滑动平均后的reward随epiosde的变化曲线图并记录超参数写成报告,图示如下:
### 代码清单
**main.py**:保存强化学习基本接口,以及相应的超参数,可使用argparse
**model.py**:保存神经网络,比如全链接网络
**agent.py**: 保存算法模型,主要包含predict(预测动作)和learn两个函数
**plot.py**:保存相关绘制函数
## 备注
* 注意 e-greedy 策略的使用,以及相应的参数epsilon如何衰减
* 训练模型和测试模型的时候选择动作有一些不同,训练时采取e-greedy策略,而测试时直接选取Q值最大对应的动作,所以算法在动作选择的时候会包括sample(训练时的动作采样)和predict(测试时的动作选择)
* Q值最大对应的动作可能不止一个,此时可以随机选择一个输出结果
**由于从起点到终点最少需要13步,每步得到-1的reward,因此最佳训练算法下,每个episode下reward总和应该为-13**。
## RL基本训练接口
```python
env = gym.make("CliffWalking-v0") # 0 up, 1 right, 2 down, 3 left
env = CliffWalkingWapper(env)
agent = QLearning(
obs_dim=env.observation_space.n,
action_dim=env.action_space.n,
learning_rate=cfg.policy_lr,
gamma=cfg.gamma,
epsilon_start=cfg.epsilon_start,epsilon_end=cfg.epsilon_end,epsilon_decay=cfg.epsilon_decay)
render = False # 是否打开GUI画面
rewards = [] # 记录所有episode的reward
MA_rewards = [] # 记录滑动平均的reward
steps = []# 记录所有episode的steps
for i_episode in range(1,cfg.max_episodes+1):
ep_reward = 0 # 记录每个episode的reward
ep_steps = 0 # 记录每个episode走了多少step
obs = env.reset() # 重置环境, 重新开一局(即开始新的一个episode)
while True:
action = agent.sample(obs) # 根据算法选择一个动作
next_obs, reward, done, _ = env.step(action) # 与环境进行一个交互
# 训练 Q-learning算法
agent.learn(obs, action, reward, next_obs, done) # 不需要下一步的action
obs = next_obs # 存储上一个观察值
ep_reward += reward
ep_steps += 1 # 计算step数
if render:
env.render() #渲染新的一帧图形
if done:
break
steps.append(ep_steps)
rewards.append(ep_reward)
# 计算滑动平均的reward
if i_episode == 1:
MA_rewards.append(ep_reward)
else:
MA_rewards.append(
0.9*MA_rewards[-1]+0.1*ep_reward)
print('Episode %s: steps = %s , reward = %.1f, explore = %.2f' % (i_episode, ep_steps,
ep_reward,agent.epsilon))
# 每隔20个episode渲染一下看看效果
if i_episode % 20 == 0:
render = True
else:
render = False
agent.save() # 训练结束,保存模型
```
## 任务要求
训练并绘制reward以及滑动平均后的reward随epiosde的变化曲线图并记录超参数写成报告,图示如下:


### 代码清单
**main.py**:保存强化学习基本接口,以及相应的超参数,可使用argparse
**model.py**:保存神经网络,比如全链接网络
**agent.py**: 保存算法模型,主要包含predict(预测动作)和learn两个函数
**plot.py**:保存相关绘制函数
## 备注
* 注意 e-greedy 策略的使用,以及相应的参数epsilon如何衰减
* 训练模型和测试模型的时候选择动作有一些不同,训练时采取e-greedy策略,而测试时直接选取Q值最大对应的动作,所以算法在动作选择的时候会包括sample(训练时的动作采样)和predict(测试时的动作选择)
* Q值最大对应的动作可能不止一个,此时可以随机选择一个输出结果