Compare commits
1716 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
997390d383 | ||
|
|
bcd892ee1c | ||
|
|
19977d177e | ||
|
|
21b02da32e | ||
|
|
aa893a6d2b | ||
|
|
cbdb7fa492 | ||
|
|
925ae9842c | ||
|
|
4b58a24592 | ||
|
|
ef0957f62f | ||
|
|
363f35eeb6 | ||
|
|
2e26559e2d | ||
|
|
773690d2d6 | ||
|
|
04926005ff | ||
|
|
333ac49f95 | ||
|
|
cbe6f915fe | ||
|
|
ee4ea11706 | ||
|
|
fbc741521d | ||
|
|
bea12db8bb | ||
|
|
6da886e046 | ||
|
|
07b6f6ef73 | ||
|
|
5684f70895 | ||
|
|
692ceeff7b | ||
|
|
9020aa0530 | ||
|
|
a63e1d4403 | ||
|
|
40482ce04b | ||
|
|
65e0ff665d | ||
|
|
35baf17160 | ||
|
|
b00c9a2587 | ||
|
|
e23a25b9b7 | ||
|
|
46c0cd3030 | ||
|
|
c1ef42d61f | ||
|
|
35dc7ecf25 | ||
|
|
2012d0d8eb | ||
|
|
194b7b3870 | ||
|
|
08c49836da | ||
|
|
7581d73b8c | ||
|
|
3270604b95 | ||
|
|
c944b5e454 | ||
|
|
2517cfa3f8 | ||
|
|
659d835617 | ||
|
|
2379b9dd26 | ||
|
|
38d23a93cb | ||
|
|
abfcd969a7 | ||
|
|
0414445a85 | ||
|
|
934ba528e6 | ||
|
|
08605f254a | ||
|
|
613288d07b | ||
|
|
5029a78c9b | ||
|
|
6175fc8e05 | ||
|
|
fb21b07dcf | ||
|
|
33b4a04aa3 | ||
|
|
26b82b1725 | ||
|
|
0a263f665c | ||
|
|
3597a9590d | ||
|
|
c3e5fdb09f | ||
|
|
9b5af4bedd | ||
|
|
43e9d7727e | ||
|
|
47a271f938 | ||
|
|
78619f5909 | ||
|
|
b7b94b8f28 | ||
|
|
a1408cefc5 | ||
|
|
e56dbafc37 | ||
|
|
835767b556 | ||
|
|
5cefc85462 | ||
|
|
b69467f288 | ||
|
|
abd6503ae4 | ||
|
|
3a4fe159db | ||
|
|
185589582f | ||
|
|
99279afddd | ||
|
|
a2da2f5d90 | ||
|
|
264c208697 | ||
|
|
449174f0a0 | ||
|
|
13af581e94 | ||
|
|
e10cf02347 | ||
|
|
7a65844448 | ||
|
|
b5adda52dd | ||
|
|
35143774ba | ||
|
|
14bc31d93a | ||
|
|
0e7f7f497e | ||
|
|
4383491dec | ||
|
|
7dcc4c218f | ||
|
|
f9440cf1f1 | ||
|
|
a5f7a1afde | ||
|
|
04feaf6d20 | ||
|
|
0e0dedbfc1 | ||
|
|
fbc0aceb5e | ||
|
|
d24ae9798d | ||
|
|
cb920d7163 | ||
|
|
0bec305d59 | ||
|
|
4942550e22 | ||
|
|
7ca6f96cbc | ||
|
|
351a9c5afa | ||
|
|
18f0298a48 | ||
|
|
e8c3696786 | ||
|
|
e686c44a76 | ||
|
|
961b9544d0 | ||
|
|
0fe08d0173 | ||
|
|
dc9e885848 | ||
|
|
96f1f3d3c5 | ||
|
|
76a80ab488 | ||
|
|
9eb12859a2 | ||
|
|
ed00a602d3 | ||
|
|
19515b2769 | ||
|
|
fb56fc9deb | ||
|
|
6e2bb9712f | ||
|
|
785fb7db34 | ||
|
|
b1028b8b79 | ||
|
|
3d2eae7734 | ||
|
|
33eb64e162 | ||
|
|
3ac5c6f971 | ||
|
|
3e4a59d4c2 | ||
|
|
38ee988007 | ||
|
|
53e7ac42a7 | ||
|
|
9000aab763 | ||
|
|
781537cec8 | ||
|
|
0b283ecf20 | ||
|
|
19f52cd165 | ||
|
|
1865d09118 | ||
|
|
4ca25868c3 | ||
|
|
3aa959e5e2 | ||
|
|
5ebd432483 | ||
|
|
99b2c4c6d4 | ||
|
|
6083856137 | ||
|
|
fbc0bf93e1 | ||
|
|
c6bc0867fa | ||
|
|
c2e00e752f | ||
|
|
a3e4103336 | ||
|
|
62977aa2c8 | ||
|
|
06d5c15c9c | ||
|
|
ac16929c92 | ||
|
|
ef7df11fc4 | ||
|
|
271abeaa0f | ||
|
|
e5da2cf044 | ||
|
|
87923a4267 | ||
|
|
ecaa9565cf | ||
|
|
2152dd99e4 | ||
|
|
cb8b4a8cf3 | ||
|
|
181672324e | ||
|
|
1d46a70eed | ||
|
|
24e8b75dab | ||
|
|
0edc5a2b03 | ||
|
|
09dbc9c9c4 | ||
|
|
e2669169ea | ||
|
|
468d1ab671 | ||
|
|
916dbd6abc | ||
|
|
6cd4027265 | ||
|
|
64de6c5ed9 | ||
|
|
b937e9b21a | ||
|
|
d052cb5ca7 | ||
|
|
5a9e86c53c | ||
|
|
363b149d05 | ||
|
|
e8505a89f6 | ||
|
|
45a46eb13b | ||
|
|
f01536b40d | ||
|
|
d559d4a9aa | ||
|
|
05b5904578 | ||
|
|
ea8328eb37 | ||
|
|
fee7873b68 | ||
|
|
f9a613e222 | ||
|
|
db35986f87 | ||
|
|
3b42a17dbf | ||
|
|
275a47448b | ||
|
|
85dbbd4448 | ||
|
|
4227d67b53 | ||
|
|
6f6d3adab2 | ||
|
|
351ff9863f | ||
|
|
979c63ae58 | ||
|
|
bfcc3d5b23 | ||
|
|
68a9cc3369 | ||
|
|
b3e1448db6 | ||
|
|
eaed709aa2 | ||
|
|
02c84f5d41 | ||
|
|
1a0164c5cf | ||
|
|
91371e8eb6 | ||
|
|
b26471ae3a | ||
|
|
376b724447 | ||
|
|
bb37d6ad09 | ||
|
|
39b88090a0 | ||
|
|
e4a30865bd | ||
|
|
b81558ac71 | ||
|
|
e73eb6ae89 | ||
|
|
ab7eea1e02 | ||
|
|
f5db0bc2f0 | ||
|
|
02dd74dd08 | ||
|
|
86d5c7501a | ||
|
|
ded46466d8 | ||
|
|
44cf5b8ff7 | ||
|
|
95a5c69fec | ||
|
|
321e3bb275 | ||
|
|
4fd6e116c8 | ||
|
|
f23b9dd04f | ||
|
|
05376c1863 | ||
|
|
2138f0fba1 | ||
|
|
e3cf6a24d5 | ||
|
|
94318cc157 | ||
|
|
cd07f799a3 | ||
|
|
b14bbb0272 | ||
|
|
55019d0e21 | ||
|
|
beab742992 | ||
|
|
a4baef392f | ||
|
|
d724b9379b | ||
|
|
9db0ba27ef | ||
|
|
65e3cf98b0 | ||
|
|
92142f8f7a | ||
|
|
8ec6018eb1 | ||
|
|
54b647f534 | ||
|
|
5a909e20a9 | ||
|
|
3aedd2dcba | ||
|
|
bef1087fd9 | ||
|
|
eef5610ef0 | ||
|
|
35d4f91676 | ||
|
|
d740934533 | ||
|
|
8b63ef00d9 | ||
|
|
73d73b91fd | ||
|
|
e84d75a50a | ||
|
|
564c173428 | ||
|
|
b9b57c5dfa | ||
|
|
e40d3105a6 | ||
|
|
031294ac05 | ||
|
|
09cd3b0a18 | ||
|
|
f1d693d827 | ||
|
|
75373dd513 | ||
|
|
e064c1a7f7 | ||
|
|
a86cfc71d7 | ||
|
|
e03fcd8c47 | ||
|
|
d6d8bd6ebf | ||
|
|
df47ded859 | ||
|
|
b906be8099 | ||
|
|
447c035a55 | ||
|
|
7fce762cf4 | ||
|
|
ac3001b14c | ||
|
|
c1370e96d8 | ||
|
|
80e53529a8 | ||
|
|
07651ad259 | ||
|
|
4d5e816dd4 | ||
|
|
1e88d06248 | ||
|
|
2aaea3446c | ||
|
|
2815762a8a | ||
|
|
2bdd872943 | ||
|
|
9c11008512 | ||
|
|
36e092c9c9 | ||
|
|
78298495ac | ||
|
|
cde709fc82 | ||
|
|
d85879c66c | ||
|
|
50ef41ee50 | ||
|
|
f56400a56b | ||
|
|
2674ab7e46 | ||
|
|
daedd3071c | ||
|
|
89c2626810 | ||
|
|
8db24498d0 | ||
|
|
890b934fe9 | ||
|
|
8446489b68 | ||
|
|
5f5a5a4a56 | ||
|
|
1be712767f | ||
|
|
1ec596a7fa | ||
|
|
ba340caa5f | ||
|
|
c30b235fe3 | ||
|
|
d1fbdb3612 | ||
|
|
fcfe586f7b | ||
|
|
5296a62c45 | ||
|
|
6f5c67d8f9 | ||
|
|
a650e54831 | ||
|
|
2a62b59346 | ||
|
|
236d2bf78f | ||
|
|
6cb4be22ae | ||
|
|
2bb50f4a47 | ||
|
|
4502167216 | ||
|
|
593fb99723 | ||
|
|
f848a4ec24 | ||
|
|
7af659bda7 | ||
|
|
75aedf8601 | ||
|
|
c5c55be846 | ||
|
|
54440de9b1 | ||
|
|
4b9b2675e2 | ||
|
|
db9eaa7ec8 | ||
|
|
a283da77a1 | ||
|
|
793ef89f22 | ||
|
|
3318c3cf01 | ||
|
|
153cdcde00 | ||
|
|
bb3688e67c | ||
|
|
a89180a386 | ||
|
|
4f81f46b0b | ||
|
|
6de2e8f60f | ||
|
|
669b11b313 | ||
|
|
ce388edce8 | ||
|
|
ee1306fb3b | ||
|
|
17d0c638dc | ||
|
|
4b83f39241 | ||
|
|
f21c028908 | ||
|
|
64872fcaee | ||
|
|
76d4feec1a | ||
|
|
6aeff6767c | ||
|
|
baf915508f | ||
|
|
e39823f616 | ||
|
|
a198271deb | ||
|
|
c9fa31ca49 | ||
|
|
0dda035057 | ||
|
|
eed33408a8 | ||
|
|
9c309563de | ||
|
|
efb805a987 | ||
|
|
cd01de1344 | ||
|
|
e7315e3ffa | ||
|
|
4074dcd366 | ||
|
|
8348fa167b | ||
|
|
f11378186d | ||
|
|
8a342af11b | ||
|
|
4637f2b6e8 | ||
|
|
2b9e9a23d3 | ||
|
|
9e7f819eda | ||
|
|
de67c5d4cd | ||
|
|
0a5685435f | ||
|
|
fc2e62c7c9 | ||
|
|
346163906b | ||
|
|
5b550dccfd | ||
|
|
e665bceb5b | ||
|
|
a6aaca984f | ||
|
|
a3b36eec44 | ||
|
|
99cc99bb51 | ||
|
|
e61c72b597 | ||
|
|
9f6322494f | ||
|
|
6403fb0679 | ||
|
|
3c256d17e8 | ||
|
|
99bc50bbba | ||
|
|
5ab121f996 | ||
|
|
feccd67115 | ||
|
|
c1fd755ccb | ||
|
|
3014e5da96 | ||
|
|
8871355787 | ||
|
|
9898f2918f | ||
|
|
bb6ff56ce5 | ||
|
|
d6d0a1687b | ||
|
|
b7ecb66210 | ||
|
|
529aeaddd2 | ||
|
|
c319d78888 | ||
|
|
1c3fe73285 | ||
|
|
8ee23f2bd9 | ||
|
|
f4322cf427 | ||
|
|
26528b7e19 | ||
|
|
0fdb79b8cd | ||
|
|
a3f3613742 | ||
|
|
3cc7badbad | ||
|
|
c628c25009 | ||
|
|
5aedfb0baa | ||
|
|
93e5fd2a35 | ||
|
|
37533e5552 | ||
|
|
daf431b9f5 | ||
|
|
47110c567c | ||
|
|
2fcd6d0401 | ||
|
|
6f0ea5b76c | ||
|
|
8ed0aa68d7 | ||
|
|
26aeb5bab8 | ||
|
|
5a7ddf30d4 | ||
|
|
f82d6a5317 | ||
|
|
da76d33b8b | ||
|
|
964518572c | ||
|
|
417ff137b1 | ||
|
|
94ee34046a | ||
|
|
ece9967d3c | ||
|
|
7227ba9d0b | ||
|
|
d1d3036a2b | ||
|
|
4f03da9814 | ||
|
|
53bf39c0d1 | ||
|
|
c1d1e6a53e | ||
|
|
f0c776e254 | ||
|
|
bc6118bbf8 | ||
|
|
d09254ae87 | ||
|
|
fca743aa86 | ||
|
|
c47e5b9646 | ||
|
|
8daafff1a0 | ||
|
|
6a51d7f543 | ||
|
|
cff10438dc | ||
|
|
f5cd1e38d0 | ||
|
|
9722f43f17 | ||
|
|
2096c0908c | ||
|
|
b3058a6f1f | ||
|
|
6d64076505 | ||
|
|
fc08b283a1 | ||
|
|
8475d0cbf1 | ||
|
|
c0fab96191 | ||
|
|
f935a024f9 | ||
|
|
d991fecb73 | ||
|
|
e3029ef8cd | ||
|
|
89e651b279 | ||
|
|
f7a047594c | ||
|
|
bdf7f69390 | ||
|
|
664e3feedb | ||
|
|
f7fd62225e | ||
|
|
47a3560132 | ||
|
|
7656c63afe | ||
|
|
92de4d4bbe | ||
|
|
bc19e74411 | ||
|
|
d3879f6979 | ||
|
|
c544134556 | ||
|
|
7168d2cc3b | ||
|
|
ba2eaa8949 | ||
|
|
9063c91610 | ||
|
|
978eefaaf3 | ||
|
|
96c6b6ea96 | ||
|
|
32764be888 | ||
|
|
db4c461a7d | ||
|
|
0e741851d4 | ||
|
|
e552065031 | ||
|
|
e0a2d487ce | ||
|
|
1a120d7abf | ||
|
|
d90a63e175 | ||
|
|
d5f5c12d05 | ||
|
|
8e7361ae41 | ||
|
|
7dd86f4aa4 | ||
|
|
05f28f6966 | ||
|
|
d128ba5efd | ||
|
|
96bc7ea64f | ||
|
|
f20ff7a201 | ||
|
|
04fcf93b9a | ||
|
|
4d25f53f6b | ||
|
|
5f98ead97e | ||
|
|
4c96347af1 | ||
|
|
107d5857dd | ||
|
|
e6af7c0520 | ||
|
|
7efb3aeba7 | ||
|
|
2eb50e9b8d | ||
|
|
86367cf7a5 | ||
|
|
7bbf9f6e7e | ||
|
|
6bfee6acf1 | ||
|
|
df9dae1fc2 | ||
|
|
3813545e7e | ||
|
|
dd4afaf881 | ||
|
|
f063383bb7 | ||
|
|
5e42eb8236 | ||
|
|
2fd0a7a02b | ||
|
|
20dbe31b49 | ||
|
|
ae15e0815e | ||
|
|
2a3c50a2dd | ||
|
|
42d9986c16 | ||
|
|
736e249ad5 | ||
|
|
41d214f391 | ||
|
|
1655d5ff3e | ||
|
|
0590166439 | ||
|
|
634e32e654 | ||
|
|
cab81ce2b1 | ||
|
|
6a45b6057a | ||
|
|
be82758d56 | ||
|
|
5fe424abae | ||
|
|
ee4af3fb6c | ||
|
|
0854571eae | ||
|
|
5e5feb370b | ||
|
|
95464f29ba | ||
|
|
f7186aa347 | ||
|
|
0dff1a72c0 | ||
|
|
5da99067c8 | ||
|
|
a433eb07a3 | ||
|
|
9199cae91a | ||
|
|
1d1648fe1f | ||
|
|
2d3dee065d | ||
|
|
27cad6eca3 | ||
|
|
87972b0335 | ||
|
|
7b0e5db6ba | ||
|
|
203ff08ac5 | ||
|
|
d5615fb6c5 | ||
|
|
510dfa94f5 | ||
|
|
7155656d65 | ||
|
|
9be375de9e | ||
|
|
022c0d30eb | ||
|
|
82547ca276 | ||
|
|
d38b49e5fb | ||
|
|
a6652e6636 | ||
|
|
fbc2f3e2a4 | ||
|
|
c27a142938 | ||
|
|
0e3ea062b6 | ||
|
|
6794677006 | ||
|
|
de58cc89d5 | ||
|
|
3dda5a94cf | ||
|
|
3224f8c1ab | ||
|
|
5d00dd29e4 | ||
|
|
c94ef3cf4a | ||
|
|
236892c370 | ||
|
|
0e0b92a9fa | ||
|
|
f59d3505a8 | ||
|
|
2bd294f1bd | ||
|
|
fa9c690e60 | ||
|
|
8b769d73b8 | ||
|
|
3e1cb92001 | ||
|
|
ae6d27a454 | ||
|
|
499baf51fb | ||
|
|
828635e421 | ||
|
|
fee5c4a54f | ||
|
|
4ad24deb9c | ||
|
|
384015e648 | ||
|
|
66ddc0bf22 | ||
|
|
3bcaf8d318 | ||
|
|
475f02fbe6 | ||
|
|
9a3b48140d | ||
|
|
f342d42b86 | ||
|
|
cdbccb3b14 | ||
|
|
cc3e4d1edd | ||
|
|
db23ffae54 | ||
|
|
e50e14764f | ||
|
|
a813bf462f | ||
|
|
dfcc012201 | ||
|
|
9c1baef0b7 | ||
|
|
e5bc900b40 | ||
|
|
02692becfe | ||
|
|
8add9fe424 | ||
|
|
c54817aa01 | ||
|
|
44dc26d13e | ||
|
|
09c81d7f59 | ||
|
|
e951429ec0 | ||
|
|
3e3ff3cfb3 | ||
|
|
109cc3717b | ||
|
|
9e9b799441 | ||
|
|
8ee1f212d2 | ||
|
|
69f52798c6 | ||
|
|
de58647402 | ||
|
|
b048c04310 | ||
|
|
c20bf4cf57 | ||
|
|
cbde2e4a81 | ||
|
|
f728f33363 | ||
|
|
6df4d8ff76 | ||
|
|
580139c626 | ||
|
|
b251a127c8 | ||
|
|
a840f52908 | ||
|
|
7ff701b5d7 | ||
|
|
ef82e73fac | ||
|
|
a3655e99c3 | ||
|
|
96fd8d7682 | ||
|
|
38b18efdb2 | ||
|
|
f83e756581 | ||
|
|
99c068604a | ||
|
|
761fc762f2 | ||
|
|
8d3ee88cde | ||
|
|
42114259f9 | ||
|
|
9611171542 | ||
|
|
c40f2965dd | ||
|
|
375c6822f1 | ||
|
|
063d58edc3 | ||
|
|
3c78069f88 | ||
|
|
1f5444e86b | ||
|
|
5af8060176 | ||
|
|
12e8c88a07 | ||
|
|
85ecff451c | ||
|
|
0407f31717 | ||
|
|
a421da41cc | ||
|
|
02a199bb50 | ||
|
|
7c931c011a | ||
|
|
1b489ffc95 | ||
|
|
3eacc03095 | ||
|
|
fdc988a481 | ||
|
|
b585c0fbbd | ||
|
|
00be6b86d5 | ||
|
|
30064745c6 | ||
|
|
de7b982783 | ||
|
|
068ab15f90 | ||
|
|
218cdfe816 | ||
|
|
5c6e011489 | ||
|
|
bea2fd6899 | ||
|
|
0bb2b2da3b | ||
|
|
02b52df234 | ||
|
|
d161890994 | ||
|
|
5843a62d5e | ||
|
|
0b7d3ed0a5 | ||
|
|
1cb4cd37a2 | ||
|
|
c45037e20c | ||
|
|
edfddc18d8 | ||
|
|
bd51898ae2 | ||
|
|
b6786ef9d7 | ||
|
|
6b7e518fbe | ||
|
|
8ad4997342 | ||
|
|
3117b3a18d | ||
|
|
31da166931 | ||
|
|
788fc4a97c | ||
|
|
1cecf66a84 | ||
|
|
48d14e19ae | ||
|
|
54d8f3af87 | ||
|
|
6ffdf08bc8 | ||
|
|
d1f40c453c | ||
|
|
35340eb1e9 | ||
|
|
7f2cef7bae | ||
|
|
7ea3dd23d0 | ||
|
|
9e332b0d02 | ||
|
|
64e7a3a016 | ||
|
|
3955483811 | ||
|
|
c354518c57 | ||
|
|
a3c8398f29 | ||
|
|
8e7cbd8fa6 | ||
|
|
2b4e445f3b | ||
|
|
ccfb96be10 | ||
|
|
25272729f3 | ||
|
|
02580c70a9 | ||
|
|
d4197a9d16 | ||
|
|
a4758a3669 | ||
|
|
2ac6b1cab8 | ||
|
|
0bd34f907e | ||
|
|
377a9f308b | ||
|
|
64c129267c | ||
|
|
377b0d7707 | ||
|
|
bb0d49ee4e | ||
|
|
2c6c79ac4f | ||
|
|
950a4dce13 | ||
|
|
c1568cd64a | ||
|
|
592005be01 | ||
|
|
ec28814449 | ||
|
|
e24535418c | ||
|
|
123a2a0c73 | ||
|
|
aa0f72edd8 | ||
|
|
602d89cfe3 | ||
|
|
bfb0d6277e | ||
|
|
3814695d88 | ||
|
|
8bdc4fac46 | ||
|
|
ece2ee451c | ||
|
|
ea3e1870e7 | ||
|
|
ca527a81a4 | ||
|
|
e1b5d17b05 | ||
|
|
a84452ba1c | ||
|
|
61de7863ed | ||
|
|
e226aa255e | ||
|
|
2ade44cd32 | ||
|
|
9a9d36672f | ||
|
|
1195949854 | ||
|
|
2483a9fc2f | ||
|
|
2b7b61bd6d | ||
|
|
9acc691ca9 | ||
|
|
21bd3c60b7 | ||
|
|
138808fb67 | ||
|
|
4704ed98dd | ||
|
|
cd06a603d3 | ||
|
|
495ecdae15 | ||
|
|
c7b6f286a5 | ||
|
|
17d304920e | ||
|
|
0b0d0fcafc | ||
|
|
27f8f53350 | ||
|
|
d44166d9ac | ||
|
|
26313bc550 | ||
|
|
80e3c8d9a7 | ||
|
|
8000bb701b | ||
|
|
cc5accc51e | ||
|
|
13438bf854 | ||
|
|
629f0f050c | ||
|
|
6655d41491 | ||
|
|
1604f0567f | ||
|
|
5525aacae3 | ||
|
|
38e0e772b2 | ||
|
|
80621b95e2 | ||
|
|
3df90d902e | ||
|
|
bc3f1d5bc7 | ||
|
|
2f169bcf70 | ||
|
|
ecbb85b481 | ||
|
|
17e45276cf | ||
|
|
8d95adc409 | ||
|
|
0fcb11be35 | ||
|
|
433eafb6c8 | ||
|
|
1acf8b5096 | ||
|
|
fc933615f0 | ||
|
|
a8f39201b9 | ||
|
|
c552ab850b | ||
|
|
df8f4ae7f0 | ||
|
|
7d0bdb810d | ||
|
|
e2600f75cd | ||
|
|
df2fc10c09 | ||
|
|
56e6031f60 | ||
|
|
b244122892 | ||
|
|
713ce3294d | ||
|
|
015367acee | ||
|
|
bc92afa9b0 | ||
|
|
a356b2531e | ||
|
|
5cf120587d | ||
|
|
8e9ea6d852 | ||
|
|
b64dc83e2e | ||
|
|
701cc954cb | ||
|
|
4d7aad19d0 | ||
|
|
df5d1fbb15 | ||
|
|
e79fad6661 | ||
|
|
33c699b8b6 | ||
|
|
96046ff3e1 | ||
|
|
1a301d3c24 | ||
|
|
aaa21c6cb8 | ||
|
|
0a78cb7d06 | ||
|
|
b41aff2600 | ||
|
|
6841853ee1 | ||
|
|
e8132c8d43 | ||
|
|
b403f147ea | ||
|
|
cb66431143 | ||
|
|
e025d9d99a | ||
|
|
699f3932e1 | ||
|
|
1bf204ac82 | ||
|
|
963320a14e | ||
|
|
78bc3f7601 | ||
|
|
0aa8bc3a90 | ||
|
|
988b22dcb7 | ||
|
|
74390a2579 | ||
|
|
4a58a3fda1 | ||
|
|
e825ad99a3 | ||
|
|
59b554ee80 | ||
|
|
06297949da | ||
|
|
b2177ce256 | ||
|
|
af8d8e881e | ||
|
|
41f4743149 | ||
|
|
0c4df0130b | ||
|
|
ccb4e764ae | ||
|
|
722c96b29a | ||
|
|
7863302db7 | ||
|
|
a9c4b0e417 | ||
|
|
e8af0e5a53 | ||
|
|
744178d288 | ||
|
|
92effe53b7 | ||
|
|
50c3975b75 | ||
|
|
a5e8687639 | ||
|
|
0988039a34 | ||
|
|
8f362470b9 | ||
|
|
0622b8bda3 | ||
|
|
1863ccb1e2 | ||
|
|
fffa78a2c4 | ||
|
|
e564629f16 | ||
|
|
3786f58bb6 | ||
|
|
3b498d32ca | ||
|
|
0fe1b2fcac | ||
|
|
cc0d89805a | ||
|
|
05a0838d86 | ||
|
|
b67acd256b | ||
|
|
a50af88409 | ||
|
|
935d12f4dc | ||
|
|
0548e31875 | ||
|
|
b96b3c6481 | ||
|
|
c59967e0bd | ||
|
|
7b2dda9fa6 | ||
|
|
f5d47d9170 | ||
|
|
b22f95ed64 | ||
|
|
a6e7a7ecc4 | ||
|
|
dc00531239 | ||
|
|
4517efc502 | ||
|
|
2f523ea540 | ||
|
|
1cf1782a22 | ||
|
|
7bc667e3b9 | ||
|
|
90593b6d7a | ||
|
|
e8eb3ff192 | ||
|
|
9c5db258ec | ||
|
|
0758104e7a | ||
|
|
db1ad1d582 | ||
|
|
03954c3a35 | ||
|
|
4e96d57204 | ||
|
|
dbbfa72268 | ||
|
|
eaa9d51d00 | ||
|
|
921f926056 | ||
|
|
24ac95f365 | ||
|
|
414151b139 | ||
|
|
d3eef993de | ||
|
|
99ae5bf996 | ||
|
|
1aa60ccfbd | ||
|
|
4a09981dd8 | ||
|
|
7b4d246237 | ||
|
|
850679705e | ||
|
|
1f9bf6b4c2 | ||
|
|
c440315488 | ||
|
|
cb83e4246d | ||
|
|
b025c51852 | ||
|
|
c3e9ab7957 | ||
|
|
8559eea296 | ||
|
|
daf7f5e0a0 | ||
|
|
aae4df73fa | ||
|
|
249884a27e | ||
|
|
5da134986a | ||
|
|
d80b2eeb7d | ||
|
|
dd106453f7 | ||
|
|
4428971135 | ||
|
|
5ef16e3a6d | ||
|
|
f553927913 | ||
|
|
24b4f9f5e2 | ||
|
|
c9b96f65ab | ||
|
|
56bbfe6f24 | ||
|
|
3420f918f5 | ||
|
|
6624ed7224 | ||
|
|
bc3cda953d | ||
|
|
a546c4e83e | ||
|
|
b006aee34d | ||
|
|
189f4db616 | ||
|
|
7f8d500b13 | ||
|
|
416e8be351 | ||
|
|
317449c568 | ||
|
|
380b220df1 | ||
|
|
f26987ddf9 | ||
|
|
c0a4ce638c | ||
|
|
f8dc05a38b | ||
|
|
678a8f9bc8 | ||
|
|
e72521951c | ||
|
|
e5abac9138 | ||
|
|
0933e87944 | ||
|
|
b0959d1b18 | ||
|
|
d010ea6d51 | ||
|
|
3873d1aa4c | ||
|
|
bd3504f3b5 | ||
|
|
f601669229 | ||
|
|
890452bffd | ||
|
|
288acfb264 | ||
|
|
35c4bf85ae | ||
|
|
5d4f76a11f | ||
|
|
8ab736e4fa | ||
|
|
b87206870b | ||
|
|
40d25d23f5 | ||
|
|
a405c5c41b | ||
|
|
cf072e79d1 | ||
|
|
8cb57673b0 | ||
|
|
39ad025760 | ||
|
|
3183d284b7 | ||
|
|
5df0339279 | ||
|
|
952e2c9a30 | ||
|
|
6d1e99d8ab | ||
|
|
8ef87c285f | ||
|
|
f52db0011c | ||
|
|
f21fdcb5f5 | ||
|
|
f0c37ccf4c | ||
|
|
a4aa9ec762 | ||
|
|
0453132656 | ||
|
|
1d0a55b260 | ||
|
|
ccf187245c | ||
|
|
0aa4c7d76c | ||
|
|
08470a4cba | ||
|
|
531840c3fb | ||
|
|
2c22d70078 | ||
|
|
3e1d951af8 | ||
|
|
b5b2e7f0d8 | ||
|
|
b5d6c7fe4f | ||
|
|
ef1c816483 | ||
|
|
a20bfc08b0 | ||
|
|
256c711c6d | ||
|
|
8345bc1064 | ||
|
|
536ee3f6d8 | ||
|
|
b1d302a042 | ||
|
|
255b5e40ce | ||
|
|
75b71888d9 | ||
|
|
07893de121 | ||
|
|
8f99f4b939 | ||
|
|
23ae8f9666 | ||
|
|
30bc6a59c6 | ||
|
|
875c5dc3a1 | ||
|
|
afc0118830 | ||
|
|
d7aea9a09d | ||
|
|
9304aab940 | ||
|
|
3ef0db1890 | ||
|
|
cc36562c17 | ||
|
|
d7197d8b8c | ||
|
|
620affc987 | ||
|
|
161f4063b9 | ||
|
|
948a3d20b0 | ||
|
|
6a4739c035 | ||
|
|
ecd5c7de1c | ||
|
|
bf5bd5d444 | ||
|
|
c6efec91dd | ||
|
|
e87f5b7a1f | ||
|
|
911f43cd5c | ||
|
|
16078b95b1 | ||
|
|
aae5b0a8d3 | ||
|
|
6834b7d215 | ||
|
|
184230f934 | ||
|
|
4fbb6454c0 | ||
|
|
bdbd97149f | ||
|
|
4ffc34a5cf | ||
|
|
0ca57fa8c1 | ||
|
|
37869f58e7 | ||
|
|
8cfefc60ef | ||
|
|
cc48c26558 | ||
|
|
868aeb9572 | ||
|
|
d02563c446 | ||
|
|
fe39c7f114 | ||
|
|
6bd3f9b8ed | ||
|
|
43bb64d7d0 | ||
|
|
6c990e8482 | ||
|
|
c41df40e9f | ||
|
|
c7b83bfc0e | ||
|
|
50574a705b | ||
|
|
5e0e8b9cea | ||
|
|
54ed626294 | ||
|
|
c599463409 | ||
|
|
c32a4a12ac | ||
|
|
367d53b09b | ||
|
|
d6677b717d | ||
|
|
446eb166a3 | ||
|
|
b59b4938d6 | ||
|
|
efc94917a6 | ||
|
|
12159abba7 | ||
|
|
21a3c9fd02 | ||
|
|
3bbcc52aee | ||
|
|
d368d061f2 | ||
|
|
d409e5006b | ||
|
|
ffd80ba0e4 | ||
|
|
0591400bb3 | ||
|
|
9d1c6e9ca0 | ||
|
|
d4f6abe1be | ||
|
|
05e3bbff2f | ||
|
|
1b93fcfecc | ||
|
|
4d86003c13 | ||
|
|
1913d82b40 | ||
|
|
7716af2be0 | ||
|
|
c40be3e5a9 | ||
|
|
1e4a10bbb0 | ||
|
|
7e15800cbe | ||
|
|
631dee6d9a | ||
|
|
757e930a50 | ||
|
|
f9433e589f | ||
|
|
a98ba439bc | ||
|
|
033b1c498e | ||
|
|
83b704017c | ||
|
|
6b5331b8a7 | ||
|
|
50c4be28c2 | ||
|
|
f8cf813d83 | ||
|
|
a1ca4b9cad | ||
|
|
1204076366 | ||
|
|
e572a55907 | ||
|
|
82fc31c4e0 | ||
|
|
91c7b016a2 | ||
|
|
15e8166610 | ||
|
|
08df7383a5 | ||
|
|
2c41487a4e | ||
|
|
ae2c2bcf23 | ||
|
|
8a614c45d9 | ||
|
|
1cb54fb956 | ||
|
|
9ed239105a | ||
|
|
99e9cfc5bf | ||
|
|
9f337effbf | ||
|
|
1809f5a32d | ||
|
|
e83be4736a | ||
|
|
27e47334ea | ||
|
|
4b6da439e7 | ||
|
|
ed6ea7e63b | ||
|
|
1c759e713e | ||
|
|
f51d91b227 | ||
|
|
d771b4e985 | ||
|
|
7048a3254c | ||
|
|
aabaf491b9 | ||
|
|
6e855cca01 | ||
|
|
8c5d85298e | ||
|
|
71d0adecf0 | ||
|
|
7880f81f40 | ||
|
|
cf924d5319 | ||
|
|
03630738d9 | ||
|
|
5a80f13bec | ||
|
|
34b0d37748 | ||
|
|
423ede4584 | ||
|
|
0a71ec1606 | ||
|
|
877d890ca8 | ||
|
|
e9a7f6a099 | ||
|
|
74a1e63bd6 | ||
|
|
935362fe60 | ||
|
|
9d5c2b5480 | ||
|
|
c67cfea593 | ||
|
|
da5946d981 | ||
|
|
14b271eb08 | ||
|
|
fe5fe4544c | ||
|
|
5738cfbd89 | ||
|
|
80b973ef59 | ||
|
|
458e951d42 | ||
|
|
bcc0e5aa7a | ||
|
|
88c378bf47 | ||
|
|
c1aceafe0c | ||
|
|
99832367a2 | ||
|
|
1a365457cd | ||
|
|
996ee5609f | ||
|
|
d14b315e53 | ||
|
|
5f9441411e | ||
|
|
5bd044dc61 | ||
|
|
b85977e16b | ||
|
|
9934267077 | ||
|
|
15aa0a5198 | ||
|
|
ff72e2713b | ||
|
|
9cd4b35ea0 | ||
|
|
a31673d07c | ||
|
|
eb1d577f00 | ||
|
|
f41c965f40 | ||
|
|
967a5f293c | ||
|
|
b40c0407b3 | ||
|
|
d37b06f38b | ||
|
|
b13b85c057 | ||
|
|
fa49a14a0f | ||
|
|
8020d24226 | ||
|
|
4c1a0f80c1 | ||
|
|
a965b35fa0 | ||
|
|
3cce315100 | ||
|
|
8fbe101196 | ||
|
|
4d34940fb3 | ||
|
|
9544d338e4 | ||
|
|
36c734ca9e | ||
|
|
9072f8b5ec | ||
|
|
ac22fcdf05 | ||
|
|
e2cd1f09df | ||
|
|
5abeb360af | ||
|
|
0989195008 | ||
|
|
9538a873bc | ||
|
|
15198a62c2 | ||
|
|
9f1e6d5206 | ||
|
|
d46cd291c0 | ||
|
|
93cb465bde | ||
|
|
e913925279 | ||
|
|
f97c6f8748 | ||
|
|
7fe5b69ad2 | ||
|
|
b88b2ead7e | ||
|
|
863dd3bb81 | ||
|
|
88cef56870 | ||
|
|
191c1f99ed | ||
|
|
488f1efcca | ||
|
|
57d19c1709 | ||
|
|
99d4ff999f | ||
|
|
a98199f065 | ||
|
|
98f50e76cc | ||
|
|
a5363430b1 | ||
|
|
cf45a8bf60 | ||
|
|
2ab40201b5 | ||
|
|
a3ceaf42b2 | ||
|
|
1b1ac5e308 | ||
|
|
2546da86a0 | ||
|
|
6437f55701 | ||
|
|
2f38efe3d4 | ||
|
|
fb96921378 | ||
|
|
c582d2f50b | ||
|
|
32fe7e3e5d | ||
|
|
626e51d22d | ||
|
|
0fa1e482cd | ||
|
|
c4c229bbc5 | ||
|
|
36f5f80ccb | ||
|
|
a3eb94ddcb | ||
|
|
2a7c2b5095 | ||
|
|
047da6baa8 | ||
|
|
c533a78357 | ||
|
|
815a6a73a8 | ||
|
|
7ef59cfcf0 | ||
|
|
dcdf68ae2e | ||
|
|
34a563562e | ||
|
|
d99aa9baa2 | ||
|
|
d82e591585 | ||
|
|
c57fe53073 | ||
|
|
f55a02a851 | ||
|
|
fa14dcc492 | ||
|
|
be9aafdc5b | ||
|
|
d83dc61dd9 | ||
|
|
878479cfdb | ||
|
|
6af721b79f | ||
|
|
b7b327b9c4 | ||
|
|
8dcf34a1ab | ||
|
|
8908bb8892 | ||
|
|
ab50ec6b30 | ||
|
|
210b2cf6b8 | ||
|
|
9a7ca2cf32 | ||
|
|
264c63be4e | ||
|
|
a900019099 | ||
|
|
78e725f603 | ||
|
|
97651ba6f0 | ||
|
|
415b0334f2 | ||
|
|
0ffe355cad | ||
|
|
3042001df5 | ||
|
|
9941543d49 | ||
|
|
d039a3c44e | ||
|
|
a4a679fc2f | ||
|
|
f181707edd | ||
|
|
d6c40a0859 | ||
|
|
d7c2c49e49 | ||
|
|
3e6763f7af | ||
|
|
f02fe16254 | ||
|
|
4e40928d94 | ||
|
|
d9b936bf62 | ||
|
|
c8c02c4911 | ||
|
|
b860788281 | ||
|
|
f3ffb5753f | ||
|
|
e47c17a57f | ||
|
|
1460e2962d | ||
|
|
624c828968 | ||
|
|
031ada6f34 | ||
|
|
b9ab3f4856 | ||
|
|
5258b52f4b | ||
|
|
4778e6360e | ||
|
|
c816dca54b | ||
|
|
7e11b26ea3 | ||
|
|
10e35cbd92 | ||
|
|
07026f89f8 | ||
|
|
031bab5219 | ||
|
|
7f51ba1514 | ||
|
|
3f5a7a0f52 | ||
|
|
05e2ac5574 | ||
|
|
3087f514b9 | ||
|
|
39b6aabd21 | ||
|
|
f2eebff163 | ||
|
|
a088992e74 | ||
|
|
b73758640e | ||
|
|
f8a3756173 | ||
|
|
22dda137ca | ||
|
|
8223a5e04c | ||
|
|
94c5598fde | ||
|
|
c8e61936b3 | ||
|
|
fceed1d04e | ||
|
|
ef87a626da | ||
|
|
49f5615252 | ||
|
|
3ee94a2f24 | ||
|
|
efb4531034 | ||
|
|
de8cb063e3 | ||
|
|
cef296fbf1 | ||
|
|
1a9fd18f15 | ||
|
|
8b47fdaa6c | ||
|
|
d15490d772 | ||
|
|
b5abdcee4f | ||
|
|
ed044e0be3 | ||
|
|
043789dd45 | ||
|
|
6e8ebb97bb | ||
|
|
cd8afb3353 | ||
|
|
b4cb2e1f4e | ||
|
|
e63983e046 | ||
|
|
9ceb6d747a | ||
|
|
98cee6255a | ||
|
|
c9407e2df7 | ||
|
|
dc551de957 | ||
|
|
8ebe2ae7d5 | ||
|
|
07af676bd6 | ||
|
|
ca198ff8be | ||
|
|
746602f6d6 | ||
|
|
f968eb11e6 | ||
|
|
7e7412ea6f | ||
|
|
f37ed87e62 | ||
|
|
79f17f3510 | ||
|
|
1cd1849eb9 | ||
|
|
3ffef99e31 | ||
|
|
f761e5bccc | ||
|
|
98c8585327 | ||
|
|
bac1b05263 | ||
|
|
809067fdaf | ||
|
|
d2b5eea042 | ||
|
|
b0d3e79508 | ||
|
|
abc5f6301e | ||
|
|
29c9385b0a | ||
|
|
d58115a699 | ||
|
|
b971b05a2d | ||
|
|
d4247c967a | ||
|
|
53487bbfe6 | ||
|
|
68eb05c93b | ||
|
|
61a07668e9 | ||
|
|
a1153366f2 | ||
|
|
a7e2eb210d | ||
|
|
3d45e27f21 | ||
|
|
d831053203 | ||
|
|
fa1d99be4c | ||
|
|
c4538e2b31 | ||
|
|
95b07ec60a | ||
|
|
238c8e693c | ||
|
|
02dbce5b51 | ||
|
|
3efd722808 | ||
|
|
6505d95829 | ||
|
|
20ee3e3ba4 | ||
|
|
c093b73940 | ||
|
|
6a4900174c | ||
|
|
123646dbd4 | ||
|
|
672dcde49a | ||
|
|
e6fe864073 | ||
|
|
094d170cf2 | ||
|
|
f86ed3b180 | ||
|
|
23923b9917 | ||
|
|
3e849ddc4a | ||
|
|
a734725678 | ||
|
|
62b3097e4e | ||
|
|
e93cedc3d4 | ||
|
|
d086436c3d | ||
|
|
e40623ce1a | ||
|
|
e0117a7a16 | ||
|
|
3198925284 | ||
|
|
e22a1f917a | ||
|
|
d1c94f04f9 | ||
|
|
cca6ed937e | ||
|
|
1ed1717c0d | ||
|
|
f46718596e | ||
|
|
9925a03af6 | ||
|
|
92d9786257 | ||
|
|
5a6204b699 | ||
|
|
5386388771 | ||
|
|
d54f293ee8 | ||
|
|
063de7c030 | ||
|
|
4a99b57244 | ||
|
|
2c2aafdb72 | ||
|
|
4ea5e9d6cb | ||
|
|
94526fb45d | ||
|
|
34a16e8585 | ||
|
|
558b901e06 | ||
|
|
6e89d2f8b3 | ||
|
|
7955777882 | ||
|
|
ad872b3093 | ||
|
|
2fd7b3e3df | ||
|
|
13844b9934 | ||
|
|
7135b29abb | ||
|
|
7490c27e6b | ||
|
|
23e12e9ab2 | ||
|
|
837bd2844b | ||
|
|
ef7a4a25f0 | ||
|
|
050970dc04 | ||
|
|
8264eac1a9 | ||
|
|
f2a657ba42 | ||
|
|
ce6140ad1b | ||
|
|
566cd7461f | ||
|
|
3cc66021e9 | ||
|
|
dc1e3ed2c6 | ||
|
|
cbb2b2a0ca | ||
|
|
ad133fb064 | ||
|
|
21eb792568 | ||
|
|
e2db08a02a | ||
|
|
1c66f775ed | ||
|
|
322e55847f | ||
|
|
e47509c6da | ||
|
|
51f5d111db | ||
|
|
70002fa2a9 | ||
|
|
2ac4f550ca | ||
|
|
461f1ba2f5 | ||
|
|
8f4c2b6241 | ||
|
|
9f015a16e3 | ||
|
|
3742294ce9 | ||
|
|
07bb677822 | ||
|
|
b0646ab6da | ||
|
|
fc15e119ca | ||
|
|
4816affc38 | ||
|
|
4c9cef5ec7 | ||
|
|
da5a590bde | ||
|
|
83e8e8cb44 | ||
|
|
b35c87919d | ||
|
|
0b729c3d5e | ||
|
|
9335b446f9 | ||
|
|
ef7d4fb5fa | ||
|
|
62d1f37565 | ||
|
|
ad541a3756 | ||
|
|
4c31eee978 | ||
|
|
38739feee2 | ||
|
|
b8d5aa2beb | ||
|
|
fdceb5d1b8 | ||
|
|
2fe2305226 | ||
|
|
7e94b024ff | ||
|
|
02a1036672 | ||
|
|
a49de4cb12 | ||
|
|
2a00cc5a48 | ||
|
|
7183041cbe | ||
|
|
8b6c40375c | ||
|
|
d29ad47f7b | ||
|
|
63b76d02b5 | ||
|
|
144203ad3e | ||
|
|
9340f57b96 | ||
|
|
1aaf05b06d | ||
|
|
4c8665f633 | ||
|
|
a1c7d644b1 | ||
|
|
a73df0379a | ||
|
|
23281a4a64 | ||
|
|
fc4cc4c122 | ||
|
|
c94fcd47fa | ||
|
|
7af0951b82 | ||
|
|
86db4b132d | ||
|
|
c2a9261ccb | ||
|
|
fcd782f72d | ||
|
|
bc85a19eda | ||
|
|
32fb9a0d7f | ||
|
|
7efc96f27d | ||
|
|
2769f0d95b | ||
|
|
f998403e82 | ||
|
|
d79f6ce009 | ||
|
|
77b4431bde | ||
|
|
3de29285b8 | ||
|
|
ab673b3272 | ||
|
|
97517e1ddc | ||
|
|
580d57cd75 | ||
|
|
5edba21558 | ||
|
|
b6ee20b88c | ||
|
|
1c9e2fc822 | ||
|
|
ecd8aebda6 | ||
|
|
70b111fe0b | ||
|
|
fea17ea7a2 | ||
|
|
9bed887316 | ||
|
|
9aa19463dd | ||
|
|
9454a38ce6 | ||
|
|
6f5bd41eb0 | ||
|
|
799e506a5a | ||
|
|
467e4d0a86 | ||
|
|
180ad74948 | ||
|
|
ac547e878f | ||
|
|
fc7e31be44 | ||
|
|
12b070e0fa | ||
|
|
3e62698245 | ||
|
|
edfa9c2435 | ||
|
|
024c703124 | ||
|
|
2b2632a478 | ||
|
|
9141d17975 | ||
|
|
81638eb870 | ||
|
|
4138c692e7 | ||
|
|
895a909c84 | ||
|
|
afe17a0182 | ||
|
|
2cd849f556 | ||
|
|
56a1688cf5 | ||
|
|
f75f538343 | ||
|
|
ef49a304d6 | ||
|
|
1bd510e531 | ||
|
|
30c86b292f | ||
|
|
e28440ed74 | ||
|
|
1645583c4b | ||
|
|
07b0137e24 | ||
|
|
d9bcecb116 | ||
|
|
fb453763df | ||
|
|
c1039872b9 | ||
|
|
c9e87257a7 | ||
|
|
efcf38b0cc | ||
|
|
d5c0f439a0 | ||
|
|
905e46b22d | ||
|
|
44a37df428 | ||
|
|
83e9dc235d | ||
|
|
ebb236af5d | ||
|
|
3b7a8560e3 | ||
|
|
87b15b6021 | ||
|
|
b34b4f3630 | ||
|
|
b5e68e9633 | ||
|
|
5576fbac7e | ||
|
|
ccde72f654 | ||
|
|
f589f28f7e | ||
|
|
802db851b3 | ||
|
|
7de10ff9ab | ||
|
|
0474db416d | ||
|
|
f6dea46769 | ||
|
|
6f65a87fee | ||
|
|
397d9afc45 | ||
|
|
85986e60b5 | ||
|
|
cb2089a3db | ||
|
|
bfb96c880c | ||
|
|
a2408716ea | ||
|
|
d625201942 | ||
|
|
d03e832b98 | ||
|
|
36e11e7f83 | ||
|
|
c319671c5d | ||
|
|
417d64b1e8 | ||
|
|
8873a4a7bd | ||
|
|
cc2d44b728 | ||
|
|
0f16ddc198 | ||
|
|
3d7bcf927c | ||
|
|
4d7bf88ba2 | ||
|
|
069d2c8410 | ||
|
|
d84703bf2d | ||
|
|
165a102c07 | ||
|
|
c3768a6306 | ||
|
|
c153e37ccf | ||
|
|
3421d1ecbf | ||
|
|
5d4bc3454a | ||
|
|
a2793e2723 | ||
|
|
ee7f14ef20 | ||
|
|
1745c6ac3e | ||
|
|
0d9c70625c | ||
|
|
f45f9e243a | ||
|
|
524d52b714 | ||
|
|
d0a3105da2 | ||
|
|
3db36d0499 | ||
|
|
42e646e92c | ||
|
|
3d9c92aac5 | ||
|
|
b7e0845582 | ||
|
|
38ffc56a1a | ||
|
|
41780dff64 | ||
|
|
e0677c9d24 | ||
|
|
f2f5df33d6 | ||
|
|
7348645410 | ||
|
|
df88ba7bbf | ||
|
|
0ba9b25b38 | ||
|
|
51ad58445e | ||
|
|
3a019a0430 | ||
|
|
65d32cf645 | ||
|
|
0ea1ece26a | ||
|
|
46aac97657 | ||
|
|
d98266471d | ||
|
|
760aa86d3b | ||
|
|
d109e2e4da | ||
|
|
febe65db3f | ||
|
|
cd545592c8 | ||
|
|
5b18969a5d | ||
|
|
c5e8904ee7 | ||
|
|
ae7900cab6 | ||
|
|
5e17e6b251 | ||
|
|
52bc8eca07 | ||
|
|
e194ac641a | ||
|
|
c3a26d9c4d | ||
|
|
ceef83f11a | ||
|
|
7bc2c6d7b6 | ||
|
|
a15d8d11da | ||
|
|
90da9f669f | ||
|
|
043c08534e | ||
|
|
d195d9572b | ||
|
|
46871ad993 | ||
|
|
96f7f00098 | ||
|
|
a485c61ff6 | ||
|
|
0b80d5f172 | ||
|
|
c0f319ee48 | ||
|
|
64161c43b2 | ||
|
|
1fe1cb6d02 | ||
|
|
25da3d16d6 | ||
|
|
5ca490b829 | ||
|
|
e7ad2b085a | ||
|
|
b6dd790d19 | ||
|
|
71da3535bd | ||
|
|
5e3963a978 | ||
|
|
ad7efbd90f | ||
|
|
bfa4f010e5 | ||
|
|
0635fa803e | ||
|
|
8cfbc4db6c | ||
|
|
4ccb571266 | ||
|
|
bc8ab75c7c | ||
|
|
ffd312a679 | ||
|
|
7a1ccd3ec6 | ||
|
|
c808566b9a | ||
|
|
a9c03a44a8 | ||
|
|
43b0bf7c34 | ||
|
|
e687035722 | ||
|
|
c5a68715ea | ||
|
|
f6da5db276 | ||
|
|
72a9790858 | ||
|
|
e7a7e17e52 | ||
|
|
c9d2d14e8b | ||
|
|
1cd609d200 | ||
|
|
696b2632e9 | ||
|
|
362539bbda | ||
|
|
6d87b05fee | ||
|
|
d85531eda5 | ||
|
|
b0accadc02 | ||
|
|
5f20f61fc5 | ||
|
|
3b79cf31dc | ||
|
|
97182f9249 | ||
|
|
121c20864b | ||
|
|
aca32b3cdc | ||
|
|
efd1152d56 | ||
|
|
fc4eaad44a | ||
|
|
82315472f6 | ||
|
|
df3a959852 | ||
|
|
f70e30d129 | ||
|
|
1562cf8ad5 | ||
|
|
a78dde9dd9 | ||
|
|
c044ef087d | ||
|
|
2065a80496 | ||
|
|
2d0d58fc79 | ||
|
|
7a4c84ad13 | ||
|
|
98a311c53a | ||
|
|
416d2bea3f | ||
|
|
a3ab6d2878 | ||
|
|
d40843e373 | ||
|
|
3acdeea94b | ||
|
|
8ddc675955 | ||
|
|
0d435d5568 | ||
|
|
67353cde87 | ||
|
|
a782074f98 | ||
|
|
83476c7bc0 | ||
|
|
62bb06e207 | ||
|
|
2a08c9a014 | ||
|
|
2c6169b340 | ||
|
|
b016113fc1 | ||
|
|
43d0250614 | ||
|
|
562f030c3c | ||
|
|
107a83e62a | ||
|
|
6fec1601c9 | ||
|
|
22cdf8e637 | ||
|
|
2c794d6d79 | ||
|
|
4a10512fbb | ||
|
|
a73a583abe | ||
|
|
b4398985fd | ||
|
|
98bc660604 | ||
|
|
ac825fa50f | ||
|
|
d9c00d3d26 | ||
|
|
4089c0f80a | ||
|
|
3851f397c2 | ||
|
|
07c5fb19f4 | ||
|
|
85cfcee4bb | ||
|
|
2ca1bafc41 | ||
|
|
1d786abe33 | ||
|
|
1869c8fc44 | ||
|
|
747152be5d | ||
|
|
a73ab7d306 | ||
|
|
e8b2f6b8b7 | ||
|
|
d6a2464381 | ||
|
|
0aba387807 | ||
|
|
390bf32e43 | ||
|
|
6b0f25a67e | ||
|
|
ed45c70e58 | ||
|
|
42591d8cda | ||
|
|
131702a3fa | ||
|
|
22f25ed331 | ||
|
|
b65581de47 | ||
|
|
274891fc21 | ||
|
|
ce2b6fe852 | ||
|
|
820bb7673e | ||
|
|
57ff9cdb26 | ||
|
|
96cc434884 | ||
|
|
37e035d19e | ||
|
|
7be685702b | ||
|
|
da502a3d6d | ||
|
|
aba24882bf | ||
|
|
d65e75dc0c | ||
|
|
8332d65783 | ||
|
|
1f4b7e6633 | ||
|
|
92e631ff66 | ||
|
|
698053dbdf | ||
|
|
b81c7254ab | ||
|
|
8714548d22 | ||
|
|
e8f046c431 | ||
|
|
69cf3560b1 | ||
|
|
5bea15c5f3 | ||
|
|
c749d185a8 | ||
|
|
65f0536ff1 | ||
|
|
e24f3e0abf | ||
|
|
3c5a1534b3 | ||
|
|
1792c01ad8 | ||
|
|
952b010362 | ||
|
|
f9b1f715f5 | ||
|
|
251dbd47dc | ||
|
|
ac2c3c2af7 | ||
|
|
642412a8ec | ||
|
|
d514985640 | ||
|
|
2f855795e5 | ||
|
|
7823a1e0ce | ||
|
|
73b582951c | ||
|
|
2da383ebda | ||
|
|
bd58c3de71 | ||
|
|
3b97e550a9 | ||
|
|
6122790eea | ||
|
|
eb105844f2 | ||
|
|
a67ab8534e | ||
|
|
a5c09e95f8 | ||
|
|
b3b18c04e8 | ||
|
|
bb518d5e3e | ||
|
|
a0eba2272f | ||
|
|
30e7ee563b | ||
|
|
67d99964af | ||
|
|
06f86ed7c4 | ||
|
|
d2d7d367bc | ||
|
|
dd803fffbc | ||
|
|
8499f7ac58 | ||
|
|
04ab051c67 | ||
|
|
f931ffda97 | ||
|
|
c3e37d8374 | ||
|
|
203a410ecf | ||
|
|
09b8271cbf | ||
|
|
9398d22ab3 | ||
|
|
e58c09d445 | ||
|
|
787cb34f40 | ||
|
|
809183777d | ||
|
|
77bc4b0c2e | ||
|
|
23ab8d516b | ||
|
|
31894c0f85 | ||
|
|
9b806b49ba | ||
|
|
d27e013224 | ||
|
|
c110165373 | ||
|
|
961f25bb9a | ||
|
|
67a908a054 | ||
|
|
60a87b4f50 | ||
|
|
7c68a33d89 | ||
|
|
ea95bed85a | ||
|
|
ccee4ebb6b | ||
|
|
1f57bd2b23 | ||
|
|
4bc59a48ea | ||
|
|
f4463b5bca | ||
|
|
2c701a7e78 | ||
|
|
a65e907c2c | ||
|
|
8536c6ddfb | ||
|
|
bc76c4f88f | ||
|
|
a0d2097072 | ||
|
|
7ff71fe880 | ||
|
|
ffe99bf500 | ||
|
|
16cd10e0d7 | ||
|
|
e6d5c20afb | ||
|
|
9c396e1f7a | ||
|
|
8469a721ab | ||
|
|
54d6310426 | ||
|
|
b701d7b6af | ||
|
|
dad8b443f6 | ||
|
|
3a267ecc87 | ||
|
|
63f64fcaea | ||
|
|
8848d10d00 | ||
|
|
08be49c998 | ||
|
|
8d1b1eb84d | ||
|
|
0acffd15e3 | ||
|
|
cfbe778229 | ||
|
|
5441254b05 | ||
|
|
1116d6deaa | ||
|
|
9e8d96f5c0 | ||
|
|
2ebc74fd8d | ||
|
|
645b30cf38 | ||
|
|
73a0610730 | ||
|
|
32a19bb989 | ||
|
|
9a530f4e46 | ||
|
|
780e47ffba | ||
|
|
b31f27de97 | ||
|
|
0f720acd8a | ||
|
|
09cf8206a9 | ||
|
|
9120937398 | ||
|
|
7a66695eea | ||
|
|
8d60cdbb30 | ||
|
|
c22863ece4 | ||
|
|
73cdd797c5 | ||
|
|
7eec310929 | ||
|
|
aeebfc753b | ||
|
|
aafb493a17 | ||
|
|
9d87d9769d | ||
|
|
8b36cfb35c | ||
|
|
3b85ebfa51 | ||
|
|
f415b4664a | ||
|
|
bedd76bc60 | ||
|
|
88075d7dd8 | ||
|
|
4b59f94e75 | ||
|
|
6b4e501180 | ||
|
|
6a1af89596 | ||
|
|
a9fb890639 | ||
|
|
57cdd79003 | ||
|
|
a989382888 | ||
|
|
4ca2d957a3 | ||
|
|
706d920d65 | ||
|
|
a4c8bcf2b4 | ||
|
|
06de0232a1 | ||
|
|
8dc9be12cc | ||
|
|
53fe85e607 | ||
|
|
5f46f3f25d | ||
|
|
229066fa99 | ||
|
|
6b6c884c47 | ||
|
|
690557f878 | ||
|
|
7d59456597 | ||
|
|
fb9c8201f5 | ||
|
|
d647ddfe07 | ||
|
|
dabe1f2da6 | ||
|
|
8dda8da2b3 | ||
|
|
064d8a8349 | ||
|
|
847e79c6a0 | ||
|
|
b628e11811 | ||
|
|
440577b943 | ||
|
|
65741bc5cb | ||
|
|
fd0c18a220 | ||
|
|
b5de3942ae | ||
|
|
d6d6fc5a95 | ||
|
|
8436a3871c | ||
|
|
202673dd32 | ||
|
|
5fdda13320 | ||
|
|
e0d2058fa0 | ||
|
|
dd3d394d58 | ||
|
|
6e5831d7d6 | ||
|
|
ea54a149a8 | ||
|
|
9e7c798cd1 | ||
|
|
b4e2530b6f | ||
|
|
6b5af440f1 | ||
|
|
c362e7a4d7 | ||
|
|
068dc86480 | ||
|
|
87db5b5426 | ||
|
|
9b6cd74caa | ||
|
|
6cbfd2ab0e | ||
|
|
a46391c6b2 | ||
|
|
2c2867e3c6 | ||
|
|
9102c28247 | ||
|
|
05d1ac50c1 | ||
|
|
7d5da45567 | ||
|
|
03a4669e48 | ||
|
|
123b2f4cfc | ||
|
|
cab36be6a2 | ||
|
|
4660b1cdf2 | ||
|
|
8190da3d3e | ||
|
|
5105051f53 | ||
|
|
de1c9231ad | ||
|
|
fe72afc1cf | ||
|
|
70f1b16b3c | ||
|
|
0b5d68732f | ||
|
|
241ff00a0b | ||
|
|
4131b00965 | ||
|
|
6f6ed31b31 | ||
|
|
09006865b9 | ||
|
|
c3519a2db2 | ||
|
|
b21d47c55c | ||
|
|
c073a1e253 | ||
|
|
3545705283 | ||
|
|
9c71e5976a | ||
|
|
e25da134da | ||
|
|
b990c974b6 | ||
|
|
54db38511d | ||
|
|
23c72b3f07 | ||
|
|
98faa64260 | ||
|
|
7868bd0b77 | ||
|
|
33db5f6f8e | ||
|
|
86e95589a9 | ||
|
|
3b84877a53 | ||
|
|
ec9957c75c | ||
|
|
f434cbb16d | ||
|
|
697d9a9fd0 | ||
|
|
899a0b18eb | ||
|
|
7ccc718b4f | ||
|
|
5e34602836 | ||
|
|
588c161fef | ||
|
|
e34c54b8a6 | ||
|
|
11a9ab6b51 | ||
|
|
a8255adbb8 | ||
|
|
ab992a3d89 | ||
|
|
d84767c609 | ||
|
|
fe12a05f8f | ||
|
|
018c9b7773 | ||
|
|
851e9720ae | ||
|
|
1f5bc5f029 | ||
|
|
e76d3b74c7 | ||
|
|
f0e23ebc73 | ||
|
|
71d44bf90c | ||
|
|
7beeee29e4 | ||
|
|
8eb31f94b5 | ||
|
|
5fe2874892 | ||
|
|
460c6ee868 | ||
|
|
9663f7b473 | ||
|
|
fb666feec5 | ||
|
|
b980538946 | ||
|
|
3323400937 | ||
|
|
2f29fde426 | ||
|
|
bc5c08a54c | ||
|
|
a5b0931bce | ||
|
|
5a6361897a | ||
|
|
e7090682c8 | ||
|
|
724f3a0d32 | ||
|
|
3c6741ec82 | ||
|
|
a0260d96cb | ||
|
|
bab350e8dd | ||
|
|
72fafef059 | ||
|
|
021830b31b | ||
|
|
e082cf336e | ||
|
|
3b9ab41dcc | ||
|
|
f285a1ab6b | ||
|
|
9fb813ae97 | ||
|
|
29259b7e5a | ||
|
|
952f759e90 | ||
|
|
e8f823f34c | ||
|
|
52e9d407be | ||
|
|
62bb672a83 | ||
|
|
1eef0fa48d | ||
|
|
63bc397599 |
1
.gitattributes
vendored
Normal file
@@ -0,0 +1 @@
|
||||
*.py text=auto eol=lf
|
||||
3
.github/FUNDING.yml
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
# These are supported funding model platforms
|
||||
|
||||
custom: ['https://i.postimg.cc/qBmD1v9p/donate.png']
|
||||
37
.github/ISSUE_TEMPLATE/bug-report-bug--.md
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
---
|
||||
name: Bug report BUG报告
|
||||
about: Create a report to help us improve
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
**Describe the bug 错误描述**
|
||||
Describe clearly and concisely what the error is
|
||||
清晰简洁地描述错误是什么
|
||||
|
||||
**To Reproduce 如何重现BUG**
|
||||
Steps to reproduce the behavior:
|
||||
重现行为的步骤:
|
||||
1. Go to '...'
|
||||
2. Click on '....'
|
||||
3. Scroll down to '....'
|
||||
4. See error
|
||||
|
||||
**Expected behavior 预期结果 **
|
||||
A clear and concise description of what you expected to happen.
|
||||
对您期望发生的事情进行清晰简洁的描述
|
||||
|
||||
**Screenshots BUG发生截图**
|
||||
|
||||
**Logs 日志**
|
||||
Copy all or key content of the file to this
|
||||
复制文件的全部或关键内容到此
|
||||
Logs location:
|
||||
Windows : C:/Users/username/.mlogs/
|
||||
Linux/MacOS/BSD: /home/username/.mlogs/
|
||||
|
||||
**Running Env 运行环境**
|
||||
- OS :
|
||||
- Python Version : 3.x
|
||||
16
.github/ISSUE_TEMPLATE/feature-request------.md
vendored
Normal file
@@ -0,0 +1,16 @@
|
||||
---
|
||||
name: Feature request 新功能建议
|
||||
about: Suggest an idea for this project
|
||||
title: ''
|
||||
labels: ''
|
||||
assignees: ''
|
||||
|
||||
---
|
||||
|
||||
For the new functions you need, you can contact me through the contact information below for a paid solution. I will respond as soon as possible and deliver it in the next version.
|
||||
|
||||
对于需要的新功能,可通过下方联系方式联系我有偿解决(支持众筹),我会尽快响应,会在下一个版本交付
|
||||
|
||||
# 联系方式 Contact:
|
||||
* Email : yoshiko2.dev@gmail.com
|
||||
* Telegram : https://t.me/yoshiko2
|
||||
103
.github/workflows/main.yml
vendored
Normal file
@@ -0,0 +1,103 @@
|
||||
name: PyInstaller
|
||||
|
||||
on:
|
||||
push:
|
||||
branches:
|
||||
- master
|
||||
pull_request:
|
||||
branches:
|
||||
- master
|
||||
|
||||
jobs:
|
||||
build:
|
||||
runs-on: ${{ matrix.os }}
|
||||
|
||||
strategy:
|
||||
matrix:
|
||||
os: [windows-latest, macos-latest, ubuntu-latest]
|
||||
|
||||
steps:
|
||||
- uses: actions/checkout@v2
|
||||
|
||||
- name: Install UPX
|
||||
uses: crazy-max/ghaction-upx@v2
|
||||
if: matrix.os == 'windows-latest' || matrix.os == 'ubuntu-latest'
|
||||
with:
|
||||
install-only: true
|
||||
|
||||
- name: UPX version
|
||||
if: matrix.os == 'windows-latest' || matrix.os == 'ubuntu-latest'
|
||||
run: upx --version
|
||||
|
||||
- name: Setup Python 3.10
|
||||
uses: actions/setup-python@v2
|
||||
with:
|
||||
python-version: '3.10'
|
||||
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
python -m pip install --upgrade pip
|
||||
pip install -r requirements.txt
|
||||
pip install face_recognition --no-deps
|
||||
pip install pyinstaller
|
||||
|
||||
- name: Test number_perser.get_number
|
||||
run: |
|
||||
python number_parser.py -v
|
||||
|
||||
- name: Build with PyInstaller for macos/ubuntu
|
||||
if: matrix.os == 'macos-latest' || matrix.os == 'ubuntu-latest'
|
||||
run: |
|
||||
pyinstaller \
|
||||
--onefile Movie_Data_Capture.py \
|
||||
--python-option u \
|
||||
--hidden-import "ImageProcessing.cnn" \
|
||||
--add-data "$(python -c 'import cloudscraper as _; print(_.__path__[0])' | tail -n 1):cloudscraper" \
|
||||
--add-data "$(python -c 'import opencc as _; print(_.__path__[0])' | tail -n 1):opencc" \
|
||||
--add-data "$(python -c 'import face_recognition_models as _; print(_.__path__[0])' | tail -n 1):face_recognition_models" \
|
||||
--add-data "Img:Img" \
|
||||
--add-data "scrapinglib:scrapinglib" \
|
||||
--add-data "config.ini:." \
|
||||
|
||||
- name: Build with PyInstaller for windows
|
||||
if: matrix.os == 'windows-latest'
|
||||
run: |
|
||||
pyinstaller `
|
||||
--onefile Movie_Data_Capture.py `
|
||||
--python-option u `
|
||||
--hidden-import "ImageProcessing.cnn" `
|
||||
--add-data "$(python -c 'import cloudscraper as _; print(_.__path__[0])' | tail -n 1);cloudscraper" `
|
||||
--add-data "$(python -c 'import opencc as _; print(_.__path__[0])' | tail -n 1);opencc" `
|
||||
--add-data "$(python -c 'import face_recognition_models as _; print(_.__path__[0])' | tail -n 1);face_recognition_models" `
|
||||
--add-data "Img;Img" `
|
||||
--add-data "scrapinglib;scrapinglib" `
|
||||
--add-data "config.ini;." `
|
||||
|
||||
- name: Copy config.ini
|
||||
run: |
|
||||
cp config.ini dist/
|
||||
|
||||
- name: Set VERSION variable for macos/ubuntu
|
||||
if: matrix.os == 'macos-latest' || matrix.os == 'ubuntu-latest'
|
||||
run: |
|
||||
echo "VERSION=$(python Movie_Data_Capture.py --version)" >> $GITHUB_ENV
|
||||
|
||||
- name: Set VERSION variable for windows
|
||||
if: matrix.os == 'windows-latest'
|
||||
run: |
|
||||
echo "VERSION=$(python Movie_Data_Capture.py --version)" | Out-File -FilePath $env:GITHUB_ENV -Encoding utf8 -Append
|
||||
|
||||
- name: Upload build artifact
|
||||
uses: actions/upload-artifact@v1
|
||||
with:
|
||||
name: MDC-${{ env.VERSION }}-${{ runner.os }}-amd64
|
||||
path: dist
|
||||
|
||||
- name: Run test (Ubuntu & MacOS)
|
||||
if: matrix.os == 'ubuntu-latest' || matrix.os == 'macos-latest'
|
||||
run: |
|
||||
cd dist
|
||||
touch IPX-292.mp4
|
||||
touch STAR-437-C.mp4
|
||||
touch 122922_001.mp4
|
||||
./Movie_Data_Capture
|
||||
10
.gitignore
vendored
@@ -102,3 +102,13 @@ venv.bak/
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
|
||||
# movie files
|
||||
*.mp4
|
||||
|
||||
# success/failed folder
|
||||
JAV_output/**/*
|
||||
failed/*
|
||||
.vscode/launch.json
|
||||
|
||||
.idea
|
||||
33
.vscode/launch.json
vendored
Normal file
@@ -0,0 +1,33 @@
|
||||
{
|
||||
// 使用 IntelliSense 了解相关属性。
|
||||
// 悬停以查看现有属性的描述。
|
||||
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Python: 当前文件",
|
||||
"type": "python",
|
||||
"request": "launch",
|
||||
"console": "integratedTerminal",
|
||||
"env": {
|
||||
"PYTHONIOENCODING": "utf-8"
|
||||
},
|
||||
"program": "${workspaceFolder}/Movie_Data_capture.py",
|
||||
"program1": "${workspaceFolder}/WebCrawler/javbus.py",
|
||||
"program2": "${workspaceFolder}/WebCrawler/javdb.py",
|
||||
"program3": "${workspaceFolder}/WebCrawler/xcity.py",
|
||||
"program4": "${workspaceFolder}/number_parser.py",
|
||||
"program5": "${workspaceFolder}/config.py",
|
||||
"cwd0": "${fileDirname}",
|
||||
"cwd1": "${workspaceFolder}/dist",
|
||||
"cwd2": "${env:HOME}${env:USERPROFILE}/.mdc",
|
||||
"args0": ["-a","-p","J:/Downloads","-o","J:/log"],
|
||||
"args1": ["-g","-m","3","-c","1","-d","0"],
|
||||
"args2": ["-igd0", "-m3", "-p", "J:/output", "-q", "121220_001"],
|
||||
"args3": ["-agd0","-m3", "-q", ".*","-p","J:/#output"],
|
||||
"args4": ["-gic1", "-d0", "-m3", "-o", "avlog", "-p", "I:/output"],
|
||||
"args5": ["-gic1", "-d0", "-m1", "-o", "avlog", "-p", "J:/Downloads"],
|
||||
"args6": ["-z", "-o", "J:/log"]
|
||||
}
|
||||
]
|
||||
}
|
||||
665
ADC_function.py
Executable file → Normal file
@@ -1,97 +1,602 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import requests
|
||||
from configparser import ConfigParser
|
||||
# build-in lib
|
||||
import os.path
|
||||
import os
|
||||
import re
|
||||
import uuid
|
||||
import json
|
||||
import time
|
||||
import sys
|
||||
import typing
|
||||
from unicodedata import category
|
||||
from concurrent.futures import ThreadPoolExecutor
|
||||
|
||||
config_file='config.ini'
|
||||
config = ConfigParser()
|
||||
# third party lib
|
||||
import requests
|
||||
from requests.adapters import HTTPAdapter
|
||||
import mechanicalsoup
|
||||
from pathlib import Path
|
||||
from urllib3.util.retry import Retry
|
||||
from lxml import etree
|
||||
from cloudscraper import create_scraper
|
||||
|
||||
if os.path.exists(config_file):
|
||||
try:
|
||||
config.read(config_file, encoding='UTF-8')
|
||||
except:
|
||||
print('[-]Config.ini read failed! Please use the offical file!')
|
||||
else:
|
||||
print('[+]config.ini: not found, creating...')
|
||||
with open("config.ini", "wt", encoding='UTF-8') as code:
|
||||
print("[proxy]",file=code)
|
||||
print("proxy=127.0.0.1:1080",file=code)
|
||||
print("timeout=10", file=code)
|
||||
print("retry=3", file=code)
|
||||
print("", file=code)
|
||||
print("[Name_Rule]", file=code)
|
||||
print("location_rule='JAV_output/'+actor+'/'+number",file=code)
|
||||
print("naming_rule=number+'-'+title",file=code)
|
||||
print("", file=code)
|
||||
print("[update]",file=code)
|
||||
print("update_check=1",file=code)
|
||||
print("", file=code)
|
||||
print("[media]", file=code)
|
||||
print("media_warehouse=emby", file=code)
|
||||
print("#emby or plex", file=code)
|
||||
print("#plex only test!", file=code)
|
||||
print("", file=code)
|
||||
print("[directory_capture]", file=code)
|
||||
print("switch=0", file=code)
|
||||
print("directory=", file=code)
|
||||
print("", file=code)
|
||||
print("everyone switch:1=on, 0=off", file=code)
|
||||
time.sleep(2)
|
||||
print('[+]config.ini: created!')
|
||||
try:
|
||||
config.read(config_file, encoding='UTF-8')
|
||||
except:
|
||||
print('[-]Config.ini read failed! Please use the offical file!')
|
||||
# project wide
|
||||
import config
|
||||
|
||||
def ReadMediaWarehouse():
|
||||
return config['media']['media_warehouse']
|
||||
|
||||
def UpdateCheckSwitch():
|
||||
check=str(config['update']['update_check'])
|
||||
if check == '1':
|
||||
return '1'
|
||||
elif check == '0':
|
||||
return '0'
|
||||
elif check == '':
|
||||
return '0'
|
||||
def get_html(url,cookies = None):#网页请求核心
|
||||
def get_xpath_single(html_code: str, xpath):
|
||||
html = etree.fromstring(html_code, etree.HTMLParser())
|
||||
result1 = str(html.xpath(xpath)).strip(" ['']")
|
||||
return result1
|
||||
|
||||
|
||||
G_USER_AGENT = r'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.133 Safari/537.36'
|
||||
|
||||
|
||||
def get_html(url, cookies: dict = None, ua: str = None, return_type: str = None, encoding: str = None, json_headers=None):
|
||||
"""
|
||||
网页请求核心函数
|
||||
"""
|
||||
verify = config.getInstance().cacert_file()
|
||||
config_proxy = config.getInstance().proxy()
|
||||
errors = ""
|
||||
|
||||
headers = {"User-Agent": ua or G_USER_AGENT} # noqa
|
||||
if json_headers is not None:
|
||||
headers.update(json_headers)
|
||||
|
||||
for i in range(config_proxy.retry):
|
||||
try:
|
||||
proxy = config['proxy']['proxy']
|
||||
timeout = int(config['proxy']['timeout'])
|
||||
retry_count = int(config['proxy']['retry'])
|
||||
except:
|
||||
print('[-]Proxy config error! Please check the config.')
|
||||
i = 0
|
||||
while i < retry_count:
|
||||
try:
|
||||
if not str(config['proxy']['proxy']) == '':
|
||||
proxies = {"http": "http://" + proxy,"https": "https://" + proxy}
|
||||
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3100.0 Safari/537.36'}
|
||||
getweb = requests.get(str(url), headers=headers, timeout=timeout,proxies=proxies, cookies=cookies)
|
||||
getweb.encoding = 'utf-8'
|
||||
return getweb.text
|
||||
if config_proxy.enable:
|
||||
proxies = config_proxy.proxies()
|
||||
result = requests.get(str(url), headers=headers, timeout=config_proxy.timeout, proxies=proxies,
|
||||
verify=verify,
|
||||
cookies=cookies)
|
||||
else:
|
||||
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
|
||||
getweb = requests.get(str(url), headers=headers, timeout=timeout, cookies=cookies)
|
||||
getweb.encoding = 'utf-8'
|
||||
return getweb.text
|
||||
result = requests.get(str(url), headers=headers, timeout=config_proxy.timeout, cookies=cookies)
|
||||
|
||||
if return_type == "object":
|
||||
return result
|
||||
elif return_type == "content":
|
||||
return result.content
|
||||
else:
|
||||
result.encoding = encoding or result.apparent_encoding
|
||||
return result.text
|
||||
except Exception as e:
|
||||
print("[-]Connect retry {}/{}".format(i + 1, config_proxy.retry))
|
||||
errors = str(e)
|
||||
if "getaddrinfo failed" in errors:
|
||||
print("[-]Connect Failed! Please Check your proxy config")
|
||||
debug = config.getInstance().debug()
|
||||
if debug:
|
||||
print("[-]" + errors)
|
||||
else:
|
||||
print("[-]" + errors)
|
||||
print('[-]Connect Failed! Please check your Proxy or Network!')
|
||||
raise Exception('Connect Failed')
|
||||
|
||||
|
||||
def post_html(url: str, query: dict, headers: dict = None) -> requests.Response:
|
||||
config_proxy = config.getInstance().proxy()
|
||||
errors = ""
|
||||
headers_ua = {"User-Agent": G_USER_AGENT}
|
||||
if headers is None:
|
||||
headers = headers_ua
|
||||
else:
|
||||
headers.update(headers_ua)
|
||||
|
||||
for i in range(config_proxy.retry):
|
||||
try:
|
||||
if config_proxy.enable:
|
||||
proxies = config_proxy.proxies()
|
||||
result = requests.post(url, data=query, proxies=proxies, headers=headers, timeout=config_proxy.timeout)
|
||||
else:
|
||||
result = requests.post(url, data=query, headers=headers, timeout=config_proxy.timeout)
|
||||
return result
|
||||
except Exception as e:
|
||||
print("[-]Connect retry {}/{}".format(i + 1, config_proxy.retry))
|
||||
errors = str(e)
|
||||
print("[-]Connect Failed! Please check your Proxy or Network!")
|
||||
print("[-]" + errors)
|
||||
|
||||
|
||||
G_DEFAULT_TIMEOUT = 10 # seconds
|
||||
|
||||
|
||||
class TimeoutHTTPAdapter(HTTPAdapter):
|
||||
def __init__(self, *args, **kwargs):
|
||||
self.timeout = G_DEFAULT_TIMEOUT
|
||||
if "timeout" in kwargs:
|
||||
self.timeout = kwargs["timeout"]
|
||||
del kwargs["timeout"]
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
def send(self, request, **kwargs):
|
||||
timeout = kwargs.get("timeout")
|
||||
if timeout is None:
|
||||
kwargs["timeout"] = self.timeout
|
||||
return super().send(request, **kwargs)
|
||||
|
||||
|
||||
# with keep-alive feature
|
||||
def get_html_session(url: str = None, cookies: dict = None, ua: str = None, return_type: str = None,
|
||||
encoding: str = None):
|
||||
config_proxy = config.getInstance().proxy()
|
||||
session = requests.Session()
|
||||
if isinstance(cookies, dict) and len(cookies):
|
||||
requests.utils.add_dict_to_cookiejar(session.cookies, cookies)
|
||||
retries = Retry(total=config_proxy.retry, connect=config_proxy.retry, backoff_factor=1,
|
||||
status_forcelist=[429, 500, 502, 503, 504])
|
||||
session.mount("https://", TimeoutHTTPAdapter(max_retries=retries, timeout=config_proxy.timeout))
|
||||
session.mount("http://", TimeoutHTTPAdapter(max_retries=retries, timeout=config_proxy.timeout))
|
||||
if config_proxy.enable:
|
||||
session.verify = config.getInstance().cacert_file()
|
||||
session.proxies = config_proxy.proxies()
|
||||
headers = {"User-Agent": ua or G_USER_AGENT}
|
||||
session.headers = headers
|
||||
try:
|
||||
if isinstance(url, str) and len(url):
|
||||
result = session.get(str(url))
|
||||
else: # 空url参数直接返回可重用session对象,无需设置return_type
|
||||
return session
|
||||
if not result.ok:
|
||||
return None
|
||||
if return_type == "object":
|
||||
return result
|
||||
elif return_type == "content":
|
||||
return result.content
|
||||
elif return_type == "session":
|
||||
return result, session
|
||||
else:
|
||||
result.encoding = encoding or "utf-8"
|
||||
return result.text
|
||||
except requests.exceptions.ProxyError:
|
||||
print("[-]get_html_session() Proxy error! Please check your Proxy")
|
||||
except requests.exceptions.RequestException:
|
||||
i += 1
|
||||
print('[-]Connect retry '+str(i)+'/'+str(retry_count))
|
||||
except requests.exceptions.ConnectionError:
|
||||
i += 1
|
||||
print('[-]Connect retry '+str(i)+'/'+str(retry_count))
|
||||
pass
|
||||
except Exception as e:
|
||||
print(f"[-]get_html_session() failed. {e}")
|
||||
return None
|
||||
|
||||
|
||||
def get_html_by_browser(url: str = None, cookies: dict = None, ua: str = None, return_type: str = None,
|
||||
encoding: str = None, use_scraper: bool = False):
|
||||
config_proxy = config.getInstance().proxy()
|
||||
s = create_scraper(browser={'custom': ua or G_USER_AGENT, }) if use_scraper else requests.Session()
|
||||
if isinstance(cookies, dict) and len(cookies):
|
||||
requests.utils.add_dict_to_cookiejar(s.cookies, cookies)
|
||||
retries = Retry(total=config_proxy.retry, connect=config_proxy.retry, backoff_factor=1,
|
||||
status_forcelist=[429, 500, 502, 503, 504])
|
||||
s.mount("https://", TimeoutHTTPAdapter(max_retries=retries, timeout=config_proxy.timeout))
|
||||
s.mount("http://", TimeoutHTTPAdapter(max_retries=retries, timeout=config_proxy.timeout))
|
||||
if config_proxy.enable:
|
||||
s.verify = config.getInstance().cacert_file()
|
||||
s.proxies = config_proxy.proxies()
|
||||
try:
|
||||
browser = mechanicalsoup.StatefulBrowser(user_agent=ua or G_USER_AGENT, session=s)
|
||||
if isinstance(url, str) and len(url):
|
||||
result = browser.open(url)
|
||||
else:
|
||||
return browser
|
||||
if not result.ok:
|
||||
return None
|
||||
|
||||
if return_type == "object":
|
||||
return result
|
||||
elif return_type == "content":
|
||||
return result.content
|
||||
elif return_type == "browser":
|
||||
return result, browser
|
||||
else:
|
||||
result.encoding = encoding or "utf-8"
|
||||
return result.text
|
||||
except requests.exceptions.ProxyError:
|
||||
print("[-]get_html_by_browser() Proxy error! Please check your Proxy")
|
||||
except Exception as e:
|
||||
print(f'[-]get_html_by_browser() Failed! {e}')
|
||||
return None
|
||||
|
||||
|
||||
def get_html_by_form(url, form_select: str = None, fields: dict = None, cookies: dict = None, ua: str = None,
|
||||
return_type: str = None, encoding: str = None):
|
||||
config_proxy = config.getInstance().proxy()
|
||||
s = requests.Session()
|
||||
if isinstance(cookies, dict) and len(cookies):
|
||||
requests.utils.add_dict_to_cookiejar(s.cookies, cookies)
|
||||
retries = Retry(total=config_proxy.retry, connect=config_proxy.retry, backoff_factor=1,
|
||||
status_forcelist=[429, 500, 502, 503, 504])
|
||||
s.mount("https://", TimeoutHTTPAdapter(max_retries=retries, timeout=config_proxy.timeout))
|
||||
s.mount("http://", TimeoutHTTPAdapter(max_retries=retries, timeout=config_proxy.timeout))
|
||||
if config_proxy.enable:
|
||||
s.verify = config.getInstance().cacert_file()
|
||||
s.proxies = config_proxy.proxies()
|
||||
try:
|
||||
browser = mechanicalsoup.StatefulBrowser(user_agent=ua or G_USER_AGENT, session=s)
|
||||
result = browser.open(url)
|
||||
if not result.ok:
|
||||
return None
|
||||
form = browser.select_form() if form_select is None else browser.select_form(form_select)
|
||||
if isinstance(fields, dict):
|
||||
for k, v in fields.items():
|
||||
browser[k] = v
|
||||
response = browser.submit_selected()
|
||||
|
||||
if return_type == "object":
|
||||
return response
|
||||
elif return_type == "content":
|
||||
return response.content
|
||||
elif return_type == "browser":
|
||||
return response, browser
|
||||
else:
|
||||
result.encoding = encoding or "utf-8"
|
||||
return response.text
|
||||
except requests.exceptions.ProxyError:
|
||||
print("[-]get_html_by_form() Proxy error! Please check your Proxy")
|
||||
except Exception as e:
|
||||
print(f'[-]get_html_by_form() Failed! {e}')
|
||||
return None
|
||||
|
||||
|
||||
def get_html_by_scraper(url: str = None, cookies: dict = None, ua: str = None, return_type: str = None,
|
||||
encoding: str = None):
|
||||
config_proxy = config.getInstance().proxy()
|
||||
session = create_scraper(browser={'custom': ua or G_USER_AGENT, })
|
||||
if isinstance(cookies, dict) and len(cookies):
|
||||
requests.utils.add_dict_to_cookiejar(session.cookies, cookies)
|
||||
retries = Retry(total=config_proxy.retry, connect=config_proxy.retry, backoff_factor=1,
|
||||
status_forcelist=[429, 500, 502, 503, 504])
|
||||
session.mount("https://", TimeoutHTTPAdapter(max_retries=retries, timeout=config_proxy.timeout))
|
||||
session.mount("http://", TimeoutHTTPAdapter(max_retries=retries, timeout=config_proxy.timeout))
|
||||
if config_proxy.enable:
|
||||
session.verify = config.getInstance().cacert_file()
|
||||
session.proxies = config_proxy.proxies()
|
||||
try:
|
||||
if isinstance(url, str) and len(url):
|
||||
result = session.get(str(url))
|
||||
else: # 空url参数直接返回可重用scraper对象,无需设置return_type
|
||||
return session
|
||||
if not result.ok:
|
||||
return None
|
||||
if return_type == "object":
|
||||
return result
|
||||
elif return_type == "content":
|
||||
return result.content
|
||||
elif return_type == "scraper":
|
||||
return result, session
|
||||
else:
|
||||
result.encoding = encoding or "utf-8"
|
||||
return result.text
|
||||
except requests.exceptions.ProxyError:
|
||||
print("[-]get_html_by_scraper() Proxy error! Please check your Proxy")
|
||||
except Exception as e:
|
||||
print(f"[-]get_html_by_scraper() failed. {e}")
|
||||
return None
|
||||
|
||||
|
||||
# def get_javlib_cookie() -> [dict, str]:
|
||||
# import cloudscraper
|
||||
# switch, proxy, timeout, retry_count, proxytype = config.getInstance().proxy()
|
||||
# proxies = get_proxy(proxy, proxytype)
|
||||
#
|
||||
# raw_cookie = {}
|
||||
# user_agent = ""
|
||||
#
|
||||
# # Get __cfduid/cf_clearance and user-agent
|
||||
# for i in range(retry_count):
|
||||
# try:
|
||||
# if switch == 1 or switch == '1':
|
||||
# raw_cookie, user_agent = cloudscraper.get_cookie_string(
|
||||
# "http://www.javlibrary.com/",
|
||||
# proxies=proxies
|
||||
# )
|
||||
# else:
|
||||
# raw_cookie, user_agent = cloudscraper.get_cookie_string(
|
||||
# "http://www.javlibrary.com/"
|
||||
# )
|
||||
# except requests.exceptions.ProxyError:
|
||||
# print("[-] ProxyError, retry {}/{}".format(i + 1, retry_count))
|
||||
# except cloudscraper.exceptions.CloudflareIUAMError:
|
||||
# print("[-] IUAMError, retry {}/{}".format(i + 1, retry_count))
|
||||
#
|
||||
# return raw_cookie, user_agent
|
||||
|
||||
|
||||
def translate(
|
||||
src: str,
|
||||
target_language: str = config.getInstance().get_target_language(),
|
||||
engine: str = config.getInstance().get_translate_engine(),
|
||||
app_id: str = "",
|
||||
key: str = "",
|
||||
delay: int = 0,
|
||||
) -> str:
|
||||
"""
|
||||
translate japanese kana to simplified chinese
|
||||
翻译日语假名到简体中文
|
||||
:raises ValueError: Non-existent translation engine
|
||||
"""
|
||||
trans_result = ""
|
||||
# 中文句子如果包含&等符号会被谷歌翻译截断损失内容,而且中文翻译到中文也没有意义,故而忽略,只翻译带有日语假名的
|
||||
if (is_japanese(src) == False) and ("zh_" in target_language):
|
||||
return src
|
||||
if engine == "google-free":
|
||||
gsite = config.getInstance().get_translate_service_site()
|
||||
if not re.match('^translate\.google\.(com|com\.\w{2}|\w{2})$', gsite):
|
||||
gsite = 'translate.google.cn'
|
||||
url = (
|
||||
f"https://{gsite}/translate_a/single?client=gtx&dt=t&dj=1&ie=UTF-8&sl=auto&tl={target_language}&q={src}"
|
||||
)
|
||||
result = get_html(url=url, return_type="object")
|
||||
if not result.ok:
|
||||
print('[-]Google-free translate web API calling failed.')
|
||||
return ''
|
||||
|
||||
translate_list = [i["trans"] for i in result.json()["sentences"]]
|
||||
trans_result = trans_result.join(translate_list)
|
||||
elif engine == "azure":
|
||||
url = "https://api.cognitive.microsofttranslator.com/translate?api-version=3.0&to=" + target_language
|
||||
headers = {
|
||||
'Ocp-Apim-Subscription-Key': key,
|
||||
'Ocp-Apim-Subscription-Region': "global",
|
||||
'Content-type': 'application/json',
|
||||
'X-ClientTraceId': str(uuid.uuid4())
|
||||
}
|
||||
body = json.dumps([{'text': src}])
|
||||
result = post_html(url=url, query=body, headers=headers)
|
||||
translate_list = [i["text"] for i in result.json()[0]["translations"]]
|
||||
trans_result = trans_result.join(translate_list)
|
||||
elif engine == "deeplx":
|
||||
url = config.getInstance().get_translate_service_site()
|
||||
res = requests.post(f"{url}/translate", json={
|
||||
'text': src,
|
||||
'source_lang': 'auto',
|
||||
'target_lang': target_language,
|
||||
})
|
||||
if res.text.strip():
|
||||
trans_result = res.json().get('data')
|
||||
else:
|
||||
raise ValueError("Non-existent translation engine")
|
||||
|
||||
time.sleep(delay)
|
||||
return trans_result
|
||||
|
||||
|
||||
def load_cookies(cookie_json_filename: str) -> typing.Tuple[typing.Optional[dict], typing.Optional[str]]:
|
||||
"""
|
||||
加载cookie,用于以会员方式访问非游客内容
|
||||
|
||||
:filename: cookie文件名。获取cookie方式:从网站登录后,通过浏览器插件(CookieBro或EdittThisCookie)或者直接在地址栏网站链接信息处都可以复制或者导出cookie内容,以JSON方式保存
|
||||
|
||||
# 示例: FC2-755670 url https://javdb9.com/v/vO8Mn
|
||||
# json 文件格式
|
||||
# 文件名: 站点名.json,示例 javdb9.json
|
||||
# 内容(文件编码:UTF-8):
|
||||
{
|
||||
"over18":"1",
|
||||
"redirect_to":"%2Fv%2FvO8Mn",
|
||||
"remember_me_token":"***********",
|
||||
"_jdb_session":"************",
|
||||
"locale":"zh",
|
||||
"__cfduid":"*********",
|
||||
"theme":"auto"
|
||||
}
|
||||
"""
|
||||
filename = os.path.basename(cookie_json_filename)
|
||||
if not len(filename):
|
||||
return None, None
|
||||
path_search_order = (
|
||||
Path.cwd() / filename,
|
||||
Path.home() / filename,
|
||||
Path.home() / f".mdc/{filename}",
|
||||
Path.home() / f".local/share/mdc/{filename}"
|
||||
)
|
||||
cookies_filename = None
|
||||
try:
|
||||
for p in path_search_order:
|
||||
if p.is_file():
|
||||
cookies_filename = str(p.resolve())
|
||||
break
|
||||
if not cookies_filename:
|
||||
return None, None
|
||||
return json.loads(Path(cookies_filename).read_text(encoding='utf-8')), cookies_filename
|
||||
except:
|
||||
return None, None
|
||||
|
||||
|
||||
def file_modification_days(filename: str) -> int:
|
||||
"""
|
||||
文件修改时间距此时的天数
|
||||
"""
|
||||
mfile = Path(filename)
|
||||
if not mfile.is_file():
|
||||
return 9999
|
||||
mtime = int(mfile.stat().st_mtime)
|
||||
now = int(time.time())
|
||||
days = int((now - mtime) / (24 * 60 * 60))
|
||||
if days < 0:
|
||||
return 9999
|
||||
return days
|
||||
|
||||
|
||||
def file_not_exist_or_empty(filepath) -> bool:
|
||||
return not os.path.isfile(filepath) or os.path.getsize(filepath) == 0
|
||||
|
||||
|
||||
def is_japanese(raw: str) -> bool:
|
||||
"""
|
||||
日语简单检测
|
||||
"""
|
||||
return bool(re.search(r'[\u3040-\u309F\u30A0-\u30FF\uFF66-\uFF9F]', raw, re.UNICODE))
|
||||
|
||||
|
||||
def download_file_with_filename(url: str, filename: str, path: str) -> None:
|
||||
"""
|
||||
download file save to give path with given name from given url
|
||||
"""
|
||||
conf = config.getInstance()
|
||||
config_proxy = conf.proxy()
|
||||
|
||||
for i in range(config_proxy.retry):
|
||||
try:
|
||||
if config_proxy.enable:
|
||||
if not os.path.exists(path):
|
||||
try:
|
||||
os.makedirs(path)
|
||||
except:
|
||||
print(f"[-]Fatal error! Can not make folder '{path}'")
|
||||
os._exit(0)
|
||||
r = get_html(url=url, return_type='content')
|
||||
if r == '':
|
||||
print('[-]Movie Download Data not found!')
|
||||
return
|
||||
with open(os.path.join(path, filename), "wb") as code:
|
||||
code.write(r)
|
||||
return
|
||||
else:
|
||||
if not os.path.exists(path):
|
||||
try:
|
||||
os.makedirs(path)
|
||||
except:
|
||||
print(f"[-]Fatal error! Can not make folder '{path}'")
|
||||
os._exit(0)
|
||||
r = get_html(url=url, return_type='content')
|
||||
if r == '':
|
||||
print('[-]Movie Download Data not found!')
|
||||
return
|
||||
with open(os.path.join(path, filename), "wb") as code:
|
||||
code.write(r)
|
||||
return
|
||||
except requests.exceptions.ProxyError:
|
||||
i += 1
|
||||
print('[-]Connect retry '+str(i)+'/'+str(retry_count))
|
||||
print('[-]Download : Connect retry ' + str(i) + '/' + str(config_proxy.retry))
|
||||
except requests.exceptions.ConnectTimeout:
|
||||
i += 1
|
||||
print('[-]Connect retry '+str(i)+'/'+str(retry_count))
|
||||
print('[-]Download : Connect retry ' + str(i) + '/' + str(config_proxy.retry))
|
||||
except requests.exceptions.ConnectionError:
|
||||
i += 1
|
||||
print('[-]Download : Connect retry ' + str(i) + '/' + str(config_proxy.retry))
|
||||
except requests.exceptions.RequestException:
|
||||
i += 1
|
||||
print('[-]Download : Connect retry ' + str(i) + '/' + str(config_proxy.retry))
|
||||
except IOError:
|
||||
raise ValueError(f"[-]Create Directory '{path}' failed!")
|
||||
return
|
||||
print('[-]Connect Failed! Please check your Proxy or Network!')
|
||||
raise ValueError('[-]Connect Failed! Please check your Proxy or Network!')
|
||||
return
|
||||
|
||||
|
||||
def download_one_file(args) -> str:
|
||||
"""
|
||||
download file save to given path from given url
|
||||
wrapped for map function
|
||||
"""
|
||||
|
||||
(url, save_path, json_headers) = args
|
||||
if json_headers is not None:
|
||||
filebytes = get_html(url, return_type='content', json_headers=json_headers['headers'])
|
||||
else:
|
||||
filebytes = get_html(url, return_type='content')
|
||||
if isinstance(filebytes, bytes) and len(filebytes):
|
||||
with save_path.open('wb') as fpbyte:
|
||||
if len(filebytes) == fpbyte.write(filebytes):
|
||||
return str(save_path)
|
||||
|
||||
|
||||
def parallel_download_files(dn_list: typing.Iterable[typing.Sequence], parallel: int = 0, json_headers=None):
|
||||
"""
|
||||
download files in parallel 多线程下载文件
|
||||
|
||||
用法示例: 2线程同时下载两个不同文件,并保存到不同路径,路径目录可未创建,但需要具备对目标目录和文件的写权限
|
||||
parallel_download_files([
|
||||
('https://site1/img/p1.jpg', 'C:/temp/img/p1.jpg'),
|
||||
('https://site2/cover/n1.xml', 'C:/tmp/cover/n1.xml')
|
||||
])
|
||||
|
||||
:dn_list: 可以是 tuple或者list: ((url1, save_fullpath1),(url2, save_fullpath2),) fullpath可以是str或Path
|
||||
:parallel: 并行下载的线程池线程数,为0则由函数自己决定
|
||||
"""
|
||||
mp_args = []
|
||||
for url, fullpath in dn_list:
|
||||
if url and isinstance(url, str) and url.startswith('http') \
|
||||
and fullpath and isinstance(fullpath, (str, Path)) and len(str(fullpath)):
|
||||
fullpath = Path(fullpath)
|
||||
fullpath.parent.mkdir(parents=True, exist_ok=True)
|
||||
mp_args.append((url, fullpath, json_headers))
|
||||
if not len(mp_args):
|
||||
return []
|
||||
if not isinstance(parallel, int) or parallel not in range(1, 200):
|
||||
parallel = min(5, len(mp_args))
|
||||
with ThreadPoolExecutor(parallel) as pool:
|
||||
results = list(pool.map(download_one_file, mp_args))
|
||||
return results
|
||||
|
||||
|
||||
def delete_all_elements_in_list(string: str, lists: typing.Iterable[str]):
|
||||
"""
|
||||
delete same string in given list
|
||||
"""
|
||||
new_lists = []
|
||||
for i in lists:
|
||||
if i != string:
|
||||
new_lists.append(i)
|
||||
return new_lists
|
||||
|
||||
|
||||
def delete_all_elements_in_str(string_delete: str, string: str):
|
||||
"""
|
||||
delete same string in given list
|
||||
"""
|
||||
for i in string:
|
||||
if i == string_delete:
|
||||
string = string.replace(i, "")
|
||||
return string
|
||||
|
||||
|
||||
# print format空格填充对齐内容包含中文时的空格计算
|
||||
def cn_space(v: str, n: int) -> int:
|
||||
return n - [category(c) for c in v].count('Lo')
|
||||
|
||||
|
||||
"""
|
||||
Usage: python ./ADC_function.py https://cn.bing.com/
|
||||
Purpose: benchmark get_html_session
|
||||
benchmark get_html_by_scraper
|
||||
benchmark get_html_by_browser
|
||||
benchmark get_html
|
||||
TODO: may be this should move to unittest directory
|
||||
"""
|
||||
if __name__ == "__main__":
|
||||
import sys, timeit
|
||||
from http.client import HTTPConnection
|
||||
|
||||
|
||||
def benchmark(times: int, url):
|
||||
print(f"HTTP GET Benchmark times:{times} url:{url}")
|
||||
tm = timeit.timeit(f"_ = session1.get('{url}')",
|
||||
"from __main__ import get_html_session;session1=get_html_session()",
|
||||
number=times)
|
||||
print(f' *{tm:>10.5f}s get_html_session() Keep-Alive enable')
|
||||
tm = timeit.timeit(f"_ = scraper1.get('{url}')",
|
||||
"from __main__ import get_html_by_scraper;scraper1=get_html_by_scraper()",
|
||||
number=times)
|
||||
print(f' *{tm:>10.5f}s get_html_by_scraper() Keep-Alive enable')
|
||||
tm = timeit.timeit(f"_ = browser1.open('{url}')",
|
||||
"from __main__ import get_html_by_browser;browser1=get_html_by_browser()",
|
||||
number=times)
|
||||
print(f' *{tm:>10.5f}s get_html_by_browser() Keep-Alive enable')
|
||||
tm = timeit.timeit(f"_ = get_html('{url}')",
|
||||
"from __main__ import get_html",
|
||||
number=times)
|
||||
print(f' *{tm:>10.5f}s get_html()')
|
||||
|
||||
|
||||
# target_url = "https://www.189.cn/"
|
||||
target_url = "http://www.chinaunicom.com"
|
||||
HTTPConnection.debuglevel = 1
|
||||
html_session = get_html_session()
|
||||
_ = html_session.get(target_url)
|
||||
HTTPConnection.debuglevel = 0
|
||||
|
||||
# times
|
||||
t = 100
|
||||
if len(sys.argv) > 1:
|
||||
target_url = sys.argv[1]
|
||||
benchmark(t, target_url)
|
||||
|
||||
@@ -1,153 +0,0 @@
|
||||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import glob
|
||||
import os
|
||||
import time
|
||||
import re
|
||||
import sys
|
||||
from ADC_function import *
|
||||
import json
|
||||
import shutil
|
||||
from configparser import ConfigParser
|
||||
os.chdir(os.getcwd())
|
||||
|
||||
# ============global var===========
|
||||
|
||||
version='1.3'
|
||||
|
||||
config = ConfigParser()
|
||||
config.read(config_file, encoding='UTF-8')
|
||||
|
||||
Platform = sys.platform
|
||||
|
||||
# ==========global var end=========
|
||||
|
||||
def UpdateCheck():
|
||||
if UpdateCheckSwitch() == '1':
|
||||
html2 = get_html('https://raw.githubusercontent.com/yoshiko2/AV_Data_Capture/master/update_check.json')
|
||||
html = json.loads(str(html2))
|
||||
|
||||
if not version == html['version']:
|
||||
print('[*] * New update ' + html['version'] + ' *')
|
||||
print('[*] * Download *')
|
||||
print('[*] ' + html['download'])
|
||||
print('[*]=====================================')
|
||||
else:
|
||||
print('[+]Update Check disabled!')
|
||||
def movie_lists():
|
||||
global exclude_directory_1
|
||||
global exclude_directory_2
|
||||
directory = config['directory_capture']['directory']
|
||||
total=[]
|
||||
file_type = ['mp4','avi','rmvb','wmv','mov','mkv','flv','ts']
|
||||
exclude_directory_1 = config['common']['failed_output_folder']
|
||||
exclude_directory_2 = config['common']['success_output_folder']
|
||||
if directory=='*':
|
||||
remove_total = []
|
||||
for o in file_type:
|
||||
remove_total += glob.glob(r"./" + exclude_directory_1 + "/*." + o)
|
||||
remove_total += glob.glob(r"./" + exclude_directory_2 + "/*." + o)
|
||||
for i in os.listdir(os.getcwd()):
|
||||
for a in file_type:
|
||||
total += glob.glob(r"./" + i + "/*." + a)
|
||||
for b in remove_total:
|
||||
total.remove(b)
|
||||
return total
|
||||
for a in file_type:
|
||||
total += glob.glob(r"./" + directory + "/*." + a)
|
||||
return total
|
||||
def CreatFailedFolder():
|
||||
if not os.path.exists('failed/'): # 新建failed文件夹
|
||||
try:
|
||||
os.makedirs('failed/')
|
||||
except:
|
||||
print("[-]failed!can not be make folder 'failed'\n[-](Please run as Administrator)")
|
||||
os._exit(0)
|
||||
def lists_from_test(custom_nuber): #电影列表
|
||||
a=[]
|
||||
a.append(custom_nuber)
|
||||
return a
|
||||
def CEF(path):
|
||||
try:
|
||||
files = os.listdir(path) # 获取路径下的子文件(夹)列表
|
||||
for file in files:
|
||||
os.removedirs(path + '/' + file) # 删除这个空文件夹
|
||||
print('[+]Deleting empty folder', path + '/' + file)
|
||||
except:
|
||||
a=''
|
||||
def rreplace(self, old, new, *max):
|
||||
#从右开始替换文件名中内容,源字符串,将被替换的子字符串, 新字符串,用于替换old子字符串,可选字符串, 替换不超过 max 次
|
||||
count = len(self)
|
||||
if max and str(max[0]).isdigit():
|
||||
count = max[0]
|
||||
return new.join(self.rsplit(old, count))
|
||||
def getNumber(filepath):
|
||||
filepath = filepath.replace('.\\','')
|
||||
try: # 普通提取番号 主要处理包含减号-的番号
|
||||
filepath = filepath.replace("_", "-")
|
||||
filepath.strip('22-sht.me').strip('-HD').strip('-hd')
|
||||
filename = str(re.sub("\[\d{4}-\d{1,2}-\d{1,2}\] - ", "", filepath)) # 去除文件名中时间
|
||||
try:
|
||||
file_number = re.search('\w+-\d+', filename).group()
|
||||
except: # 提取类似mkbd-s120番号
|
||||
file_number = re.search('\w+-\w+\d+', filename).group()
|
||||
return file_number
|
||||
except: # 提取不含减号-的番号
|
||||
try:
|
||||
filename = str(re.sub("ts6\d", "", filepath)).strip('Tokyo-hot').strip('tokyo-hot')
|
||||
filename = str(re.sub(".*?\.com-\d+", "", filename)).replace('_', '')
|
||||
file_number = str(re.search('\w+\d{4}', filename).group(0))
|
||||
return file_number
|
||||
except: # 提取无减号番号
|
||||
filename = str(re.sub("ts6\d", "", filepath)) # 去除ts64/265
|
||||
filename = str(re.sub(".*?\.com-\d+", "", filename))
|
||||
file_number = str(re.match('\w+', filename).group())
|
||||
file_number = str(file_number.replace(re.match("^[A-Za-z]+", file_number).group(),re.match("^[A-Za-z]+", file_number).group() + '-'))
|
||||
return file_number
|
||||
|
||||
def RunCore():
|
||||
if Platform == 'win32':
|
||||
if os.path.exists('core.py'):
|
||||
os.system('python core.py' + ' "' + i + '" --number "' + getNumber(i) + '"') # 从py文件启动(用于源码py)
|
||||
elif os.path.exists('core.exe'):
|
||||
os.system('core.exe' + ' "' + i + '" --number "' + getNumber(i) + '"') # 从exe启动(用于EXE版程序)
|
||||
elif os.path.exists('core.py') and os.path.exists('core.exe'):
|
||||
os.system('python core.py' + ' "' + i + '" --number "' + getNumber(i) + '"') # 从py文件启动(用于源码py)
|
||||
else:
|
||||
if os.path.exists('core.py'):
|
||||
os.system('python3 core.py' + ' "' + i + '" --number "' + getNumber(i) + '"') # 从py文件启动(用于源码py)
|
||||
elif os.path.exists('core.exe'):
|
||||
os.system('core.exe' + ' "' + i + '" --number "' + getNumber(i) + '"') # 从exe启动(用于EXE版程序)
|
||||
elif os.path.exists('core.py') and os.path.exists('core.exe'):
|
||||
os.system('python3 core.py' + ' "' + i + '" --number "' + getNumber(i) + '"') # 从py文件启动(用于源码py)
|
||||
|
||||
if __name__ =='__main__':
|
||||
print('[*]===========AV Data Capture===========')
|
||||
print('[*] Version '+version)
|
||||
print('[*]=====================================')
|
||||
CreatFailedFolder()
|
||||
UpdateCheck()
|
||||
os.chdir(os.getcwd())
|
||||
|
||||
count = 0
|
||||
count_all = str(len(movie_lists()))
|
||||
print('[+]Find',str(len(movie_lists())),'movies')
|
||||
for i in movie_lists(): #遍历电影列表 交给core处理
|
||||
count = count + 1
|
||||
percentage = str(count/int(count_all)*100)[:4]+'%'
|
||||
print('[!] - '+percentage+' ['+str(count)+'/'+count_all+'] -')
|
||||
try:
|
||||
print("[!]Making Data for [" + i + "], the number is [" + getNumber(i) + "]")
|
||||
RunCore()
|
||||
print("[*]=====================================")
|
||||
except: # 番号提取异常
|
||||
print('[-]' + i + ' Cannot catch the number :')
|
||||
print('[-]Move ' + i + ' to failed folder')
|
||||
shutil.move(i, str(os.getcwd()) + '/' + 'failed/')
|
||||
continue
|
||||
|
||||
CEF(exclude_directory_1)
|
||||
CEF(exclude_directory_2)
|
||||
print("[+]All finished!!!")
|
||||
input("[+][+]Press enter key exit, you can check the error messge before you exit.\n[+][+]按回车键结束,你可以在结束之前查看和错误信息。")
|
||||
114
ImageProcessing/__init__.py
Normal file
@@ -0,0 +1,114 @@
|
||||
import sys
|
||||
sys.path.append('../')
|
||||
|
||||
import logging
|
||||
import os
|
||||
import config
|
||||
import importlib
|
||||
from pathlib import Path
|
||||
from PIL import Image
|
||||
import shutil
|
||||
from ADC_function import file_not_exist_or_empty
|
||||
|
||||
|
||||
def face_crop_width(filename, width, height):
|
||||
aspect_ratio = config.getInstance().face_aspect_ratio()
|
||||
# 新宽度是高度的2/3
|
||||
cropWidthHalf = int(height/3)
|
||||
try:
|
||||
locations_model = config.getInstance().face_locations_model().lower().split(',')
|
||||
locations_model = filter(lambda x: x, locations_model)
|
||||
for model in locations_model:
|
||||
center, top = face_center(filename, model)
|
||||
# 如果找到就跳出循环
|
||||
if center:
|
||||
cropLeft = center-cropWidthHalf
|
||||
cropRight = center+cropWidthHalf
|
||||
# 越界处理
|
||||
if cropLeft < 0:
|
||||
cropLeft = 0
|
||||
cropRight = cropWidthHalf * aspect_ratio
|
||||
elif cropRight > width:
|
||||
cropLeft = width - cropWidthHalf * aspect_ratio
|
||||
cropRight = width
|
||||
return (cropLeft, 0, cropRight, height)
|
||||
except:
|
||||
print('[-]Not found face! ' + filename)
|
||||
# 默认靠右切
|
||||
return (width-cropWidthHalf * aspect_ratio, 0, width, height)
|
||||
|
||||
|
||||
def face_crop_height(filename, width, height):
|
||||
cropHeight = int(width*3/2)
|
||||
try:
|
||||
locations_model = config.getInstance().face_locations_model().lower().split(',')
|
||||
locations_model = filter(lambda x: x, locations_model)
|
||||
for model in locations_model:
|
||||
center, top = face_center(filename, model)
|
||||
# 如果找到就跳出循环
|
||||
if top:
|
||||
# 头部靠上
|
||||
cropTop = top
|
||||
cropBottom = cropHeight + top
|
||||
if cropBottom > height:
|
||||
cropTop = 0
|
||||
cropBottom = cropHeight
|
||||
return (0, cropTop, width, cropBottom)
|
||||
except:
|
||||
print('[-]Not found face! ' + filename)
|
||||
# 默认从顶部向下切割
|
||||
return (0, 0, width, cropHeight)
|
||||
|
||||
|
||||
def cutImage(imagecut, path, thumb_path, poster_path, skip_facerec=False):
|
||||
conf = config.getInstance()
|
||||
fullpath_fanart = os.path.join(path, thumb_path)
|
||||
fullpath_poster = os.path.join(path, poster_path)
|
||||
aspect_ratio = conf.face_aspect_ratio()
|
||||
if conf.face_aways_imagecut():
|
||||
imagecut = 1
|
||||
elif conf.download_only_missing_images() and not file_not_exist_or_empty(fullpath_poster):
|
||||
return
|
||||
# imagecut为4时同时也是有码影片 也用人脸识别裁剪封面
|
||||
if imagecut == 1 or imagecut == 4: # 剪裁大封面
|
||||
try:
|
||||
img = Image.open(fullpath_fanart)
|
||||
width, height = img.size
|
||||
if width/height > 2/3: # 如果宽度大于2
|
||||
if imagecut == 4:
|
||||
# 以人像为中心切取
|
||||
img2 = img.crop(face_crop_width(fullpath_fanart, width, height))
|
||||
elif skip_facerec:
|
||||
# 有码封面默认靠右切
|
||||
img2 = img.crop((width - int(height / 3) * aspect_ratio, 0, width, height))
|
||||
else:
|
||||
# 以人像为中心切取
|
||||
img2 = img.crop(face_crop_width(fullpath_fanart, width, height))
|
||||
elif width/height < 2/3: # 如果高度大于3
|
||||
# 从底部向上切割
|
||||
img2 = img.crop(face_crop_height(fullpath_fanart, width, height))
|
||||
else: # 如果等于2/3
|
||||
img2 = img
|
||||
img2.save(fullpath_poster)
|
||||
print(f"[+]Image Cutted! {Path(fullpath_poster).name}")
|
||||
except Exception as e:
|
||||
print(e)
|
||||
print('[-]Cover cut failed!')
|
||||
elif imagecut == 0: # 复制封面
|
||||
shutil.copyfile(fullpath_fanart, fullpath_poster)
|
||||
print(f"[+]Image Copyed! {Path(fullpath_poster).name}")
|
||||
|
||||
|
||||
def face_center(filename, model):
|
||||
try:
|
||||
mod = importlib.import_module('.' + model, 'ImageProcessing')
|
||||
return mod.face_center(filename, model)
|
||||
except Exception as e:
|
||||
print('[-]Model found face ' + filename)
|
||||
if config.getInstance().debug() == 1:
|
||||
logging.error(e)
|
||||
return (0, 0)
|
||||
|
||||
if __name__ == '__main__':
|
||||
cutImage(1,'z:/t/','p.jpg','o.jpg')
|
||||
#cutImage(1,'H:\\test\\','12.jpg','test.jpg')
|
||||
8
ImageProcessing/cnn.py
Normal file
@@ -0,0 +1,8 @@
|
||||
import sys
|
||||
sys.path.append('../')
|
||||
|
||||
from ImageProcessing.hog import face_center as hog_face_center
|
||||
|
||||
|
||||
def face_center(filename, model):
|
||||
return hog_face_center(filename, model)
|
||||
17
ImageProcessing/hog.py
Normal file
@@ -0,0 +1,17 @@
|
||||
import face_recognition
|
||||
|
||||
|
||||
def face_center(filename, model):
|
||||
image = face_recognition.load_image_file(filename)
|
||||
face_locations = face_recognition.face_locations(image, 1, model)
|
||||
print('[+]Found person [' + str(len(face_locations)) + '] By model hog')
|
||||
maxRight = 0
|
||||
maxTop = 0
|
||||
for face_location in face_locations:
|
||||
top, right, bottom, left = face_location
|
||||
# 中心点
|
||||
x = int((right+left)/2)
|
||||
if x > maxRight:
|
||||
maxRight = x
|
||||
maxTop = top
|
||||
return maxRight,maxTop
|
||||
BIN
Img/4K.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 34 KiB |
BIN
Img/HACK.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
BIN
Img/ISO.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 43 KiB |
BIN
Img/LEAK.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 29 KiB |
BIN
Img/SUB.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
BIN
Img/UMR.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 20 KiB |
BIN
Img/UNCENSORED.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
38
Makefile
Normal file
@@ -0,0 +1,38 @@
|
||||
#.PHONY: help prepare-dev test lint run doc
|
||||
|
||||
#VENV_NAME?=venv
|
||||
#VENV_ACTIVATE=. $(VENV_NAME)/bin/activate
|
||||
#PYTHON=${VENV_NAME}/bin/python3
|
||||
SHELL = /bin/bash
|
||||
|
||||
.DEFAULT: make
|
||||
make:
|
||||
@echo "[+]make prepare-dev"
|
||||
#sudo apt-get -y install python3 python3-pip
|
||||
pip3 install -r requirements.txt
|
||||
pip3 install pyinstaller
|
||||
|
||||
#@echo "[+]Set CLOUDSCRAPER_PATH variable"
|
||||
#export cloudscraper_path=$(python3 -c 'import cloudscraper as _; print(_.__path__[0])' | tail -n 1)
|
||||
|
||||
@echo "[+]Pyinstaller make"
|
||||
pyinstaller --onefile Movie_Data_Capture.py --hidden-import ADC_function.py --hidden-import core.py \
|
||||
--hidden-import "ImageProcessing.cnn" \
|
||||
--python-option u \
|
||||
--add-data "`python3 -c 'import cloudscraper as _; print(_.__path__[0])' | tail -n 1`:cloudscraper" \
|
||||
--add-data "`python3 -c 'import opencc as _; print(_.__path__[0])' | tail -n 1`:opencc" \
|
||||
--add-data "`python3 -c 'import face_recognition_models as _; print(_.__path__[0])' | tail -n 1`:face_recognition_models" \
|
||||
--add-data "Img:Img" \
|
||||
--add-data "config.ini:." \
|
||||
|
||||
@echo "[+]Move to bin"
|
||||
if [ ! -d "./bin" ];then mkdir bin; fi
|
||||
mv dist/* bin/
|
||||
cp config.ini bin/
|
||||
rm -rf dist/
|
||||
|
||||
@echo "[+]Clean cache"
|
||||
@find . -name '*.pyc' -delete
|
||||
@find . -name '__pycache__' -type d | xargs rm -fr
|
||||
@find . -name '.pytest_cache' -type d | xargs rm -fr
|
||||
rm -rf build/
|
||||
24750
MappingTable/c_number.json
Normal file
8220
MappingTable/mapping_actor.xml
Normal file
411
MappingTable/mapping_info.xml
Normal file
@@ -0,0 +1,411 @@
|
||||
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
|
||||
<!-- 说明:可使用文本编辑器打开本文件后自行编辑。
|
||||
keyword:用于匹配标签/导演/系列/制作/发行的关键词,每个名字前后都需要用逗号隔开。当其中包含刮削得到的关键词时,可以输出对应语言的词。
|
||||
zh_cn/zh_tw/jp:指对应语言输出的词,按设置的对应语言输出。当输出词为“删除”时表示:遇到该关键词时,在对应内容中删除该关键词-->
|
||||
<info>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",成人奖,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",觸摸打字,触摸打字,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",10枚組,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",Don Cipote's choice,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",DVD多士爐,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",R-18,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",Vシネマ,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",イメージビデオ(男性),"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",サンプル動画,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",其他,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",放置,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",獨立製作,独立制作,独占配信,配信専用,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",特典あり(AVベースボール),"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",天堂TV,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",性愛,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",限時降價,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",亞洲女演員,亚洲女演员,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",字幕,中文字幕,中文,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",AV女优,女优,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",HDTV,HD DVD,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",MicroSD,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",R-15,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",UMD,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",VHS,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",愛好,文化,爱好、文化,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",訪問,访问,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",感官作品,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",高畫質,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",高清,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",素人作品,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",友誼,友谊,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",正常,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",蓝光,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",冒險,冒险,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",模擬,模拟,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",年輕女孩,年轻女孩,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",去背影片,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",天賦,天赋,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",形象俱樂部,形象俱乐部,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",懸疑,悬疑,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",亞洲,亚洲,"/>
|
||||
<a zh_cn="删除" zh_tw="删除" jp="删除" keyword=",ハロウィーンキャンペーン,"/>
|
||||
|
||||
<a zh_cn="16小时+" zh_tw="16小時+" jp="16時間以上作品" keyword=",16小時以上作品,16小时以上作品,16時間以上作品,16小时+,16小時+,"/>
|
||||
<a zh_cn="3D" zh_tw="3D" jp="3D" keyword=",3D,"/>
|
||||
<a zh_cn="3D卡通" zh_tw="3D卡通" jp="3Dエロアニメ" keyword=",3D卡通,3Dエロアニメ,"/>
|
||||
<a zh_cn="4K" zh_tw="4K" jp="4K" keyword=",4K,"/>
|
||||
<a zh_cn="DMM独家" zh_tw="DMM獨家" jp="DMM獨家" keyword=",DMM獨家,DMM独家,DMM專屬,DMM专属,"/>
|
||||
<a zh_cn="M女" zh_tw="M女" jp="M女" keyword=",M女,"/>
|
||||
<a zh_cn="SM" zh_tw="SM" jp="SM" keyword=",SM,"/>
|
||||
<a zh_cn="轻虐" zh_tw="輕虐" jp="微SM" keyword=",微SM,轻虐,輕虐,"/>
|
||||
<a zh_cn="VR" zh_tw="VR" jp="VR" keyword=",VR,VR専用,高品质VR,ハイクオリティVR,"/>
|
||||
<a zh_cn="武术格斗" zh_tw="武術格鬥" jp="アクション" keyword=",格鬥家,格斗家,戰鬥行動,战斗行动,アクション,武术格斗,武術格鬥,"/>
|
||||
<a zh_cn="绝顶高潮" zh_tw="絕頂高潮" jp="アクメ・オーガズム" keyword=",极致·性高潮,アクメ・オーガズム,绝顶高潮,絕頂高潮,"/>
|
||||
<a zh_cn="运动" zh_tw="運動" jp="アスリート" keyword=",运动员,アスリート,運動,运动,"/>
|
||||
<a zh_cn="COSPLAY" zh_tw="COSPLAY" jp="COSPLAY" keyword=",COSPLAY,COSPLAY服飾,COSPLAY服饰,アニメ,"/>
|
||||
<a zh_cn="动画角色" zh_tw="動畫角色" jp="動畫人物" keyword=",动漫,動画,動畫人物,动画人物,动画角色,動畫角色,"/>
|
||||
<a zh_cn="角色扮演" zh_tw="角色扮演" jp="角色扮演" keyword=",角色扮演者,角色扮演,コスプレ,"/>
|
||||
<a zh_cn="萝莉Cos" zh_tw="蘿莉Cos" jp="蘿莉Cos" keyword=",蘿莉角色扮演,萝莉角色扮演,萝莉Cos,蘿莉Cos,"/>
|
||||
<a zh_cn="纯欲" zh_tw="純欲" jp="エロス" keyword=",エロス,纯欲,純欲,"/>
|
||||
<a zh_cn="御宅族" zh_tw="御宅族" jp="オタク" keyword=",御宅族,オタク,"/>
|
||||
<a zh_cn="辅助自慰" zh_tw="輔助自慰" jp="オナサポ" keyword=",自慰辅助,オナサポ,辅助自慰,輔助自慰,"/>
|
||||
<a zh_cn="自慰" zh_tw="自慰" jp="自慰" keyword=",自慰,オナニー,"/>
|
||||
<a zh_cn="洗浴" zh_tw="洗浴" jp="お風呂" keyword=",淋浴,お風呂,洗浴,洗澡,"/>
|
||||
<a zh_cn="温泉" zh_tw="溫泉" jp="溫泉" keyword=",温泉,溫泉,"/>
|
||||
<a zh_cn="寝取" zh_tw="寢取" jp="寝取られ" keyword=",寝取,寢取,寝取られ,寝取り·寝取られ·ntr,寝取り·寝取られ·NTR,"/>
|
||||
<a zh_cn="老太婆" zh_tw="老太婆" jp="お婆ちゃん" keyword=",お婆ちゃん,老太婆,"/>
|
||||
<a zh_cn="老年男性" zh_tw="老年男性" jp="お爺ちゃん" keyword=",高龄男,お爺ちゃん,老年男性,"/>
|
||||
<a zh_cn="接吻" zh_tw="接吻" jp="キス・接吻" keyword=",接吻,キス・接吻,"/>
|
||||
<a zh_cn="女同接吻" zh_tw="女同接吻" jp="女同接吻" keyword=",女同接吻,"/>
|
||||
<a zh_cn="介绍影片" zh_tw="介紹影片" jp="コミック雑誌" keyword=",コミック雑誌,介绍影片,介紹影片,"/>
|
||||
<a zh_cn="心理惊悚" zh_tw="心理驚悚" jp="サイコ・スリラー" keyword=",サイコ・スリラー,心理惊悚,心理驚悚,"/>
|
||||
<a zh_cn="打屁股" zh_tw="打屁股" jp="スパンキング" keyword=",虐打,スパンキング,打屁股,"/>
|
||||
<a zh_cn="夫妻交换" zh_tw="夫妻交換" jp="スワッピング・夫婦交換" keyword=",夫妻交换,スワッピング・夫婦交換,夫妻交換,"/>
|
||||
<a zh_cn="性感" zh_tw="性感" jp="セクシー" keyword=",性感的,性感的x,セクシー,"/>
|
||||
<a zh_cn="性感内衣" zh_tw="性感内衣" jp="性感内衣" keyword=",性感内衣,內衣,内衣,ランジェリー,"/>
|
||||
<a zh_cn="养尊处优" zh_tw="養尊處優" jp="セレブ" keyword=",セレブ,养尊处优,養尊處優,"/>
|
||||
<a zh_cn="拉拉队" zh_tw="拉拉隊" jp="チアガール" keyword=",拉拉队长,チアガール,拉拉隊,"/>
|
||||
<a zh_cn="假阳具" zh_tw="假陽具" jp="ディルド" keyword=",ディルド,假阳具,假陽具,"/>
|
||||
<a zh_cn="约会" zh_tw="約會" jp="デート" keyword=",约会,デート,約會,"/>
|
||||
<a zh_cn="巨根" zh_tw="巨根" jp="デカチン・巨根" keyword=",巨大陰莖,巨大阴茎,デカチン・巨根,"/>
|
||||
<a zh_cn="不戴套" zh_tw="不戴套" jp="生ハメ" keyword=",不戴套,生ハメ,"/>
|
||||
<a zh_cn="不穿内裤" zh_tw="不穿內褲" jp="ノーパン" keyword=",无内裤,ノーパン,不穿内裤,不穿內褲,"/>
|
||||
<a zh_cn="不穿胸罩" zh_tw="不穿胸罩" jp="ノーブラ" keyword=",无胸罩,ノーブラ,不穿胸罩,"/>
|
||||
<a zh_cn="后宫" zh_tw="後宮" jp="ハーレム" keyword=",ハーレム,后宫,後宮,"/>
|
||||
<a zh_cn="后入" zh_tw="後入" jp="バック" keyword=",背后,バック,后入,後入,"/>
|
||||
<a zh_cn="妓女" zh_tw="妓女" jp="ビッチ" keyword=",ビッチ,妓女,风俗女郎(性工作者),"/>
|
||||
<a zh_cn="感谢祭" zh_tw="感謝祭" jp="ファン感謝・訪問" keyword=",粉丝感谢,ファン感謝・訪問,感谢祭,感謝祭,"/>
|
||||
<a zh_cn="大保健" zh_tw="大保健" jp="ヘルス・ソープ" keyword=",ヘルス・ソープ,大保健,按摩,マッサージ,"/>
|
||||
<a zh_cn="按摩棒" zh_tw="按摩棒" jp="按摩棒" keyword=",女優按摩棒,女优按摩棒,按摩棒,电动按摩棒,電動按摩棒,電マ,バイブ,"/>
|
||||
<a zh_cn="男同性恋" zh_tw="男同性戀" jp="ボーイ ズラブ" keyword=",ボーイズラブ,男同,男同性戀,男同性恋,"/>
|
||||
<a zh_cn="酒店" zh_tw="酒店" jp="ホテル" keyword=",ホテル,酒店,飯店,"/>
|
||||
<a zh_cn="酒店小姐" zh_tw="酒店小姐" jp="キャバ嬢" keyword=",キャバ嬢,酒店小姐,"/>
|
||||
<a zh_cn="妈妈的朋友" zh_tw="媽媽的朋友" jp="ママ友" keyword=",ママ友,妈妈的朋友,媽媽的朋友,"/>
|
||||
<a zh_cn="喜剧" zh_tw="喜劇" jp="ラブコメ" keyword=",喜剧,爱情喜剧,ラブコメ,喜劇,滑稽模仿,堵嘴·喜劇,整人・喜剧,"/>
|
||||
<a zh_cn="恶搞" zh_tw="惡搞" jp="パロディ" keyword=",パロディ,惡搞,整人,"/>
|
||||
<a zh_cn="白眼失神" zh_tw="白眼失神" jp="白目・失神" keyword=",翻白眼・失神,白目・失神,白眼失神,"/>
|
||||
<a zh_cn="白人" zh_tw="白人" jp="白人" keyword=",白人,"/>
|
||||
<a zh_cn="招待小姐" zh_tw="招待小姐" jp="受付嬢" keyword=",招待小姐,受付嬢,接待员,"/>
|
||||
<a zh_cn="薄马赛克" zh_tw="薄馬賽克" jp="薄馬賽克" keyword=",薄馬賽克,薄马赛克,"/>
|
||||
<a zh_cn="鼻钩" zh_tw="鼻鉤" jp="鼻フック" keyword=",鼻勾,鼻フック,鼻钩,鼻鉤,"/>
|
||||
<a zh_cn="变性人" zh_tw="變性人" jp="變性者" keyword=",變性者,变性者,变性人,變性人,"/>
|
||||
<a zh_cn="医院诊所" zh_tw="醫院診所" jp="病院・クリニック" keyword=",医院・诊所,病院・クリニック,医院诊所,醫院診所,"/>
|
||||
<a zh_cn="社团经理" zh_tw="社團經理" jp="部活・マネージャー" keyword=",社团・经理,部活・マネージャー,社团经理,社團經理,"/>
|
||||
<a zh_cn="下属·同事" zh_tw="下屬·同事" jp="部下・同僚" keyword=",下属・同事,部下・同僚,下属·同事,下屬·同事,同事,下屬,下属,"/>
|
||||
<a zh_cn="残忍" zh_tw="殘忍" jp="殘忍" keyword=",殘忍,殘忍畫面,残忍画面,奇異的,奇异的,"/>
|
||||
<a zh_cn="插入异物" zh_tw="插入異物" jp="插入異物" keyword=",插入異物,插入异物,"/>
|
||||
<a zh_cn="超乳" zh_tw="超乳" jp="超乳" keyword=",超乳,"/>
|
||||
<a zh_cn="潮吹" zh_tw="潮吹" jp="潮吹" keyword=",潮吹,潮吹き,"/>
|
||||
<a zh_cn="男优潮吹" zh_tw="男優潮吹" jp="男の潮吹き" keyword=",男潮吹,男の潮吹き,男优潮吹,男優潮吹,"/>
|
||||
<a zh_cn="巴士导游" zh_tw="巴士導遊" jp="車掌小姐" keyword=",車掌小姐,车掌小姐,巴士乘务员,巴士乘務員,巴士导游,巴士導遊,バスガイド,"/>
|
||||
<a zh_cn="熟女" zh_tw="熟女" jp="熟女" keyword=",熟女,成熟的女人,"/>
|
||||
<a zh_cn="出轨" zh_tw="出軌" jp="出軌" keyword=",出軌,出轨,"/>
|
||||
<a zh_cn="白天出轨" zh_tw="白天出軌" jp="白天出轨" keyword=",白天出軌,白天出轨,通姦,"/>
|
||||
<a zh_cn="处男" zh_tw="處男" jp="處男" keyword=",處男,处男,"/>
|
||||
<a zh_cn="处女" zh_tw="處女" jp="處女" keyword=",處女,处女,処女,童貞,"/>
|
||||
<a zh_cn="触手" zh_tw="觸手" jp="觸手" keyword=",觸手,触手,"/>
|
||||
<a zh_cn="胁迫" zh_tw="胁迫" jp="胁迫" keyword=",魔鬼系,粗暴,胁迫,"/>
|
||||
<a zh_cn="催眠" zh_tw="催眠" jp="催眠" keyword=",催眠,"/>
|
||||
<a zh_cn="打手枪" zh_tw="打手槍" jp="打手槍" keyword=",手淫,打手枪,打手槍,手コキ,"/>
|
||||
<a zh_cn="单体作品" zh_tw="單體作品" jp="單體作品" keyword=",单体作品,單體作品,単体作品,AV女优片,"/>
|
||||
<a zh_cn="荡妇" zh_tw="蕩婦" jp="蕩婦" keyword=",蕩婦,荡妇,"/>
|
||||
<a zh_cn="搭讪" zh_tw="搭訕" jp="搭訕" keyword=",倒追,女方搭讪,女方搭訕,搭讪,搭訕,ナンパ,"/>
|
||||
<a zh_cn="女医师" zh_tw="女醫師" jp="女醫師" keyword=",女医师,女醫師,女医,"/>
|
||||
<a zh_cn="主观视角" zh_tw="主觀視角" jp="主觀視角" keyword=",第一人稱攝影,第一人称摄影,主观视角,主觀視角,第一人称视点,主観,"/>
|
||||
<a zh_cn="多P" zh_tw="多P" jp="多P" keyword=",多P,"/>
|
||||
<a zh_cn="恶作剧" zh_tw="惡作劇" jp="惡作劇" keyword=",惡作劇,恶作剧,"/>
|
||||
<a zh_cn="放尿" zh_tw="放尿" jp="放尿" keyword=",放尿,"/>
|
||||
<a zh_cn="女服务生" zh_tw="女服務生" jp="ウェイトレス" keyword=",服務生,服务生,女服务生,女服務生,ウェイトレス,"/>
|
||||
<a zh_cn="蒙面" zh_tw="蒙面" jp="覆面・マスク" keyword=",蒙面・面罩,蒙面・面具,覆面・マスク,"/>
|
||||
<a zh_cn="肛交" zh_tw="肛交" jp="肛交" keyword=",肛交,アナル,"/>
|
||||
<a zh_cn="肛内中出" zh_tw="肛內中出" jp="肛內中出" keyword=",肛内中出,肛內中出,"/>
|
||||
<a zh_cn="个子高" zh_tw="個子高" jp="个子高" keyword=",高,个子高,個子高,"/>
|
||||
<a zh_cn="高中生" zh_tw="高中生" jp="高中生" keyword=",高中女生,高中生,"/>
|
||||
<a zh_cn="歌德萝莉" zh_tw="歌德蘿莉" jp="哥德蘿莉" keyword=",歌德萝莉,哥德蘿莉,歌德蘿莉,"/>
|
||||
<a zh_cn="各种职业" zh_tw="各種職業" jp="各種職業" keyword=",各種職業,各种职业,多種職業,多种职业,職業色々,"/>
|
||||
<a zh_cn="职业装" zh_tw="職業裝" jp="職業裝" keyword=",OL,洽公服装,职业装,職業裝,ビジネススーツ,"/>
|
||||
<a zh_cn="女性向" zh_tw="女性向" jp="女性向け" keyword=",給女性觀眾,给女性观众,女性向,女性向け,"/>
|
||||
<a zh_cn="公主" zh_tw="公主" jp="公主" keyword=",公主,"/>
|
||||
<a zh_cn="故事集" zh_tw="故事集" jp="故事集" keyword=",故事集,"/>
|
||||
<a zh_cn="寡妇" zh_tw="寡婦" jp="寡婦" keyword=",寡婦,寡妇,"/>
|
||||
<a zh_cn="灌肠" zh_tw="灌腸" jp="灌腸" keyword=",灌腸,灌肠,"/>
|
||||
<a zh_cn="进口" zh_tw="進口" jp="國外進口" keyword=",海外,進口,进口,國外進口,国外进口,"/>
|
||||
<a zh_cn="流汗" zh_tw="流汗" jp="汗だく" keyword=",流汗,汗だく,"/>
|
||||
<a zh_cn="共演" zh_tw="共演" jp="合作作品" keyword=",合作作品,共演,"/>
|
||||
<a zh_cn="和服・丧服" zh_tw="和服・喪服" jp="和服・喪服" keyword=",和服・丧服,和服,喪服,和服、丧服,和服・喪服,和服·丧服,和服·喪服,"/>
|
||||
<a zh_cn="和服・浴衣" zh_tw="和服・浴衣" jp="和服・浴衣" keyword=",浴衣,和服・浴衣,和服、浴衣,"/>
|
||||
<a zh_cn="调教・奴隶" zh_tw="調教・奴隸" jp="調教・奴隸" keyword=",奴隸,奴隶,奴隷,調教・奴隷,調教,调教,调教・奴隶,调教·奴隶,調教·奴隸,調教・奴隸."/>
|
||||
<a zh_cn="黑帮成员" zh_tw="黑幫成員" jp="黑幫成員" keyword=",黑幫成員,黑帮成员,"/>
|
||||
<a zh_cn="黑人" zh_tw="黑人" jp="黑人演員" keyword=",黑人,黑人演員,黑人演员,黒人男優,"/>
|
||||
<a zh_cn="护士" zh_tw="護士" jp="ナース" keyword=",護士,护士,ナース,"/>
|
||||
<a zh_cn="痴汉" zh_tw="痴漢" jp="痴漢" keyword=",痴漢,痴汉,"/>
|
||||
<a zh_cn="痴女" zh_tw="癡女" jp="癡女" keyword=",花癡,痴女,癡女,"/>
|
||||
<a zh_cn="新娘" zh_tw="新娘" jp="新娘" keyword=",花嫁,新娘,新娘,年輕妻子,新娘、年轻妻子,新娘、年輕妻子,新娘、少妇,新娘、少婦,花嫁・若妻,"/>
|
||||
<a zh_cn="少妇" zh_tw="少婦" jp="少婦" keyword=",少妇,少婦,"/>
|
||||
<a zh_cn="妄想" zh_tw="妄想" jp="妄想" keyword=",幻想,妄想,妄想族,"/>
|
||||
<a zh_cn="肌肉" zh_tw="肌肉" jp="肌肉" keyword=",肌肉,"/>
|
||||
<a zh_cn="及膝袜" zh_tw="及膝襪" jp="及膝襪" keyword=",及膝襪,及膝袜,"/>
|
||||
<a zh_cn="纪录片" zh_tw="紀錄片" jp="纪录片" keyword=",紀錄片,纪录片,"/>
|
||||
<a zh_cn="家庭教师" zh_tw="家庭教師" jp="家庭教師" keyword=",家教,家庭教师,家庭教師,"/>
|
||||
<a zh_cn="娇小" zh_tw="嬌小" jp="嬌小的" keyword=",迷你系,迷你係列,娇小,嬌小,瘦小身型,嬌小的,迷你系‧小隻女,ミニ系・小柄,"/>
|
||||
<a zh_cn="性教学" zh_tw="性教學" jp="性教學" keyword=",教學,教学,性教学,性教學,"/>
|
||||
<a zh_cn="姐姐" zh_tw="姐姐" jp="姐姐" keyword=",姐姐,姐姐系,お姉さん,"/>
|
||||
<a zh_cn="姐·妹" zh_tw="姐·妹" jp="姐·妹" keyword=",妹妹,姐妹,姐·妹,姊妹,"/>
|
||||
<a zh_cn="穿衣幹砲" zh_tw="穿衣幹砲" jp="着エロ" keyword=",穿衣幹砲,着エロ,"/>
|
||||
<a zh_cn="紧缚" zh_tw="緊縛" jp="緊縛" keyword=",緊縛,紧缚,縛り・緊縛,紧缚,"/>
|
||||
<a zh_cn="紧身衣" zh_tw="緊身衣" jp="緊身衣" keyword=",緊身衣,紧身衣,紧缚皮衣,緊縛皮衣,紧身衣激凸,緊身衣激凸,ボディコン,"/>
|
||||
<a zh_cn="经典老片" zh_tw="經典老片" jp="經典" keyword=",經典,经典,经典老片,經典老片,"/>
|
||||
<a zh_cn="拘束" zh_tw="拘束" jp="拘束" keyword=",拘束,"/>
|
||||
<a zh_cn="监禁" zh_tw="監禁" jp="監禁" keyword=",監禁,监禁,"/>
|
||||
<a zh_cn="强奸" zh_tw="強姦" jp="強姦" keyword=",強姦,强奸,強暴,强暴,レイプ,"/>
|
||||
<a zh_cn="轮奸" zh_tw="輪姦" jp="輪姦" keyword=",輪姦,轮奸,轮姦,"/>
|
||||
<a zh_cn="私处近拍" zh_tw="私處近拍" jp="私處近拍" keyword=",私处近拍,私處近拍,局部特寫,局部特写,局部アップ,"/>
|
||||
<a zh_cn="巨尻" zh_tw="巨尻" jp="巨尻" keyword=",大屁股,巨大屁股,巨尻,"/>
|
||||
<a zh_cn="美尻" zh_tw="美尻" jp="美尻" keyword=",美尻,"/>
|
||||
<a zh_cn="巨乳" zh_tw="巨乳" jp="巨乳" keyword=",巨乳,巨乳爆乳,爱巨乳,愛巨乳,巨乳フェチ,"/>
|
||||
<a zh_cn="窈窕" zh_tw="窈窕" jp="スレンダー" keyword=",窈窕,スレンダー,"/>
|
||||
<a zh_cn="美腿" zh_tw="美腿" jp="美腿" keyword=",美腿,美脚,爱美腿,愛美腿,脚フェチ,"/>
|
||||
<a zh_cn="修长" zh_tw="修長" jp="長身" keyword=",修長,長身,"/>
|
||||
<a zh_cn="爱美臀" zh_tw="愛美臀" jp="尻フェチ" keyword=",爱美臀,愛美臀,尻フェチ,"/>
|
||||
<a zh_cn="奇幻" zh_tw="奇幻" jp="科幻" keyword=",科幻,奇幻,"/>
|
||||
<a zh_cn="空姐" zh_tw="空姐" jp="スチュワーデス" keyword=",空中小姐,空姐,スチュワーデス,"/>
|
||||
<a zh_cn="恐怖" zh_tw="恐怖" jp="恐怖" keyword=",恐怖,"/>
|
||||
<a zh_cn="口交" zh_tw="口交" jp="フェラ" keyword=",口交,フェラ,双重口交,雙重口交,Wフェラ,"/>
|
||||
<a zh_cn="强迫口交" zh_tw="強迫口交" jp="強迫口交" keyword=",强迫口交,強迫口交,イラマチオ,"/>
|
||||
<a zh_cn="偷拍" zh_tw="偷拍" jp="盗撮" keyword=",偷拍,盗撮,"/>
|
||||
<a zh_cn="蜡烛" zh_tw="蠟燭" jp="蝋燭" keyword=",蜡烛,蝋燭,蠟燭,"/>
|
||||
<a zh_cn="滥交" zh_tw="濫交" jp="濫交" keyword=",濫交,滥交,乱交,亂交,"/>
|
||||
<a zh_cn="酒醉" zh_tw="酒醉" jp="爛醉如泥的" keyword=",爛醉如泥的,烂醉如泥的,酒醉,"/>
|
||||
<a zh_cn="立即插入" zh_tw="立即插入" jp="立即插入" keyword=",立即口交,即兴性交,立即插入,马上幹,馬上幹,即ハメ,"/>
|
||||
<a zh_cn="连裤袜" zh_tw="連褲襪" jp="連褲襪" keyword=",連褲襪,连裤袜,"/>
|
||||
<a zh_cn="连发" zh_tw="連發" jp="連発" keyword=",连发,連發,連発,"/>
|
||||
<a zh_cn="恋爱" zh_tw="戀愛" jp="戀愛" keyword=",戀愛,恋爱,恋愛,"/>
|
||||
<a zh_cn="恋乳癖" zh_tw="戀乳癖" jp="戀乳癖" keyword=",戀乳癖,恋乳癖,"/>
|
||||
<a zh_cn="恋腿癖" zh_tw="戀腿癖" jp="戀腿癖" keyword=",戀腿癖,恋腿癖,"/>
|
||||
<a zh_cn="猎艳" zh_tw="獵艷" jp="獵豔" keyword=",獵豔,猎艳,獵艷,"/>
|
||||
<a zh_cn="乱伦" zh_tw="亂倫" jp="亂倫" keyword=",亂倫,乱伦,"/>
|
||||
<a zh_cn="萝莉" zh_tw="蘿莉" jp="蘿莉塔" keyword=",蘿莉塔,萝莉塔,ロリ,"/>
|
||||
<a zh_cn="裸体围裙" zh_tw="裸體圍裙" jp="裸體圍裙" keyword=",裸體圍裙,裸体围裙,真空围裙,真空圍裙,裸エプロン,"/>
|
||||
<a zh_cn="旅行" zh_tw="旅行" jp="旅行" keyword=",旅行,"/>
|
||||
<a zh_cn="骂倒" zh_tw="罵倒" jp="罵倒" keyword=",罵倒,骂倒,"/>
|
||||
<a zh_cn="蛮横娇羞" zh_tw="蠻橫嬌羞" jp="蠻橫嬌羞" keyword=",蠻橫嬌羞,蛮横娇羞,"/>
|
||||
<a zh_cn="猫耳" zh_tw="貓耳" jp="貓耳女" keyword=",貓耳女,猫耳女,"/>
|
||||
<a zh_cn="美容院" zh_tw="美容院" jp="美容院" keyword=",美容院,エステ,"/>
|
||||
<a zh_cn="短裙" zh_tw="短裙" jp="短裙" keyword=",短裙,"/>
|
||||
<a zh_cn="美少女" zh_tw="美少女" jp="美少女" keyword=",美少女,美少女電影,美少女电影,"/>
|
||||
<a zh_cn="迷你裙" zh_tw="迷你裙" jp="迷你裙" keyword=",迷你裙,ミニスカ,"/>
|
||||
<a zh_cn="迷你裙警察" zh_tw="迷你裙警察" jp="迷你裙警察" keyword=",迷你裙警察,"/>
|
||||
<a zh_cn="秘书" zh_tw="秘書" jp="秘書" keyword=",秘書,秘书,"/>
|
||||
<a zh_cn="面试" zh_tw="面試" jp="面接" keyword=",面试,面接,面試,"/>
|
||||
<a zh_cn="苗条" zh_tw="苗條" jp="苗條" keyword=",苗條,苗条,"/>
|
||||
<a zh_cn="明星脸" zh_tw="明星臉" jp="明星臉" keyword=",明星臉,明星脸,"/>
|
||||
<a zh_cn="模特" zh_tw="模特" jp="模特兒" keyword=",模特兒,模特儿,モデル,"/>
|
||||
<a zh_cn="魔法少女" zh_tw="魔法少女" jp="魔法少女" keyword=",魔法少女,"/>
|
||||
<a zh_cn="母亲" zh_tw="母親" jp="母親" keyword=",母親,母亲,妈妈系,媽媽系,お母さん,"/>
|
||||
<a zh_cn="义母" zh_tw="義母" jp="母親" keyword=",义母,義母,"/>
|
||||
<a zh_cn="母乳" zh_tw="母乳" jp="母乳" keyword=",母乳,"/>
|
||||
<a zh_cn="女强男" zh_tw="女强男" jp="逆レイプ" keyword=",逆レイプ,女强男,"/>
|
||||
<a zh_cn="养女" zh_tw="養女" jp="娘・養女" keyword=",养女,娘・養女,"/>
|
||||
<a zh_cn="女大学生" zh_tw="女大學生" jp="女子大生" keyword=",女大學生,女大学生,女子大生,"/>
|
||||
<a zh_cn="女祭司" zh_tw="女祭司" jp="女祭司" keyword=",女祭司,"/>
|
||||
<a zh_cn="女搜查官" zh_tw="女搜查官" jp="女檢察官" keyword=",女檢察官,女检察官,女搜查官,"/>
|
||||
<a zh_cn="女教师" zh_tw="女教師" jp="女教師" keyword=",女教師,女教师,"/>
|
||||
<a zh_cn="女忍者" zh_tw="女忍者" jp="女忍者" keyword=",女忍者,くノ一,"/>
|
||||
<a zh_cn="女上司" zh_tw="女上司" jp="女上司" keyword=",女上司,"/>
|
||||
<a zh_cn="骑乘位" zh_tw="騎乘位" jp="騎乗位" keyword=",女上位,骑乘,騎乘,骑乘位,騎乘位,騎乗位,"/>
|
||||
<a zh_cn="辣妹" zh_tw="辣妹" jp="辣妹" keyword=",女生,辣妹,ギャル,"/>
|
||||
<a zh_cn="女同性恋" zh_tw="女同性戀" jp="女同性戀" keyword=",女同性戀,女同性恋,女同志,レズ,"/>
|
||||
<a zh_cn="女王" zh_tw="女王" jp="女王様" keyword=",女王,女王様,"/>
|
||||
<a zh_cn="女医生" zh_tw="女醫生" jp="女醫生" keyword=",女醫生,女医生,"/>
|
||||
<a zh_cn="女仆" zh_tw="女僕" jp="メイド" keyword=",女傭,女佣,女仆,女僕,メイド,"/>
|
||||
<a zh_cn="女优最佳合集" zh_tw="女優最佳合集" jp="女優ベスト・総集編" keyword=",女優ベスト・総集編,女优最佳合集,女優最佳合集,"/>
|
||||
<a zh_cn="女战士" zh_tw="女戰士" jp="超級女英雄" keyword=",行動,行动,超級女英雄,女战士,女戰士,"/>
|
||||
<a zh_cn="女主播" zh_tw="女主播" jp="女子アナ" keyword=",女主播,女子アナ,"/>
|
||||
<a zh_cn="女主人" zh_tw="女主人" jp="老闆娘" keyword=",女主人,老闆娘,女主人,老板娘、女主人,女主人、女老板,女将・女主人,"/>
|
||||
<a zh_cn="女装人妖" zh_tw="女裝人妖" jp="女裝人妖" keyword=",女裝人妖,女装人妖,"/>
|
||||
<a zh_cn="呕吐" zh_tw="嘔吐" jp="嘔吐" keyword=",呕吐,嘔吐,"/>
|
||||
<a zh_cn="粪便" zh_tw="糞便" jp="糞便" keyword=",排便,粪便,糞便,食糞,食粪,"/>
|
||||
<a zh_cn="坦克" zh_tw="坦克" jp="胖女人" keyword=",胖女人,坦克,"/>
|
||||
<a zh_cn="泡泡袜" zh_tw="泡泡襪" jp="泡泡襪" keyword=",泡泡袜,泡泡襪,"/>
|
||||
<a zh_cn="泡沫浴" zh_tw="泡沫浴" jp="泡沫浴" keyword=",泡沫浴,"/>
|
||||
<a zh_cn="美臀" zh_tw="美臀" jp="屁股" keyword=",美臀,屁股,"/>
|
||||
<a zh_cn="平胸" zh_tw="平胸" jp="貧乳・微乳" keyword=",平胸,貧乳・微乳,"/>
|
||||
<a zh_cn="丈母娘" zh_tw="丈母娘" jp="婆婆" keyword=",婆婆,后母,丈母娘,"/>
|
||||
<a zh_cn="恋物癖" zh_tw="戀物癖" jp="戀物癖" keyword="戀物癖,恋物癖,其他戀物癖,其他恋物癖,"/>
|
||||
<a zh_cn="其他癖好" zh_tw="其他癖好" jp="その他フェチ" keyword="其他癖好,その他フェチ,"/>
|
||||
<a zh_cn="旗袍" zh_tw="旗袍" jp="旗袍" keyword=",旗袍,"/>
|
||||
<a zh_cn="企画" zh_tw="企畫" jp="企畫" keyword=",企畫,企画,"/>
|
||||
<a zh_cn="车震" zh_tw="車震" jp="汽車性愛" keyword=",汽車性愛,汽车性爱,车震,車震,车床族,車床族,カーセックス,"/>
|
||||
<a zh_cn="大小姐" zh_tw="大小姐" jp="千金小姐" keyword=",大小姐,千金小姐,"/>
|
||||
<a zh_cn="情侣" zh_tw="情侶" jp="情侶" keyword=",情侶,情侣,伴侶,伴侣,カップル,"/>
|
||||
<a zh_cn="拳交" zh_tw="拳交" jp="拳交" keyword=",拳交,"/>
|
||||
<a zh_cn="晒黑" zh_tw="曬黑" jp="日焼け" keyword=",曬黑,晒黑,日焼け,"/>
|
||||
<a zh_cn="美乳" zh_tw="美乳" jp="美乳" keyword=",乳房,美乳,"/>
|
||||
<a zh_cn="乳交" zh_tw="乳交" jp="乳交" keyword=",乳交,パイズリ,"/>
|
||||
<a zh_cn="乳液" zh_tw="乳液" jp="乳液" keyword=",乳液,ローション・オイル,ローション·オイル,"/>
|
||||
<a zh_cn="软体" zh_tw="軟體" jp="軟体" keyword=",软体,軟体,軟體,"/>
|
||||
<a zh_cn="搔痒" zh_tw="搔癢" jp="瘙癢" keyword=",搔痒,瘙癢,搔癢,"/>
|
||||
<a zh_cn="设计环节" zh_tw="設計環節" jp="設置項目" keyword=",設置項目,设计环节,設計環節,"/>
|
||||
<a zh_cn="丰乳肥臀" zh_tw="豐乳肥臀" jp="身體意識" keyword=",身體意識,身体意识,丰乳肥臀,豐乳肥臀,"/>
|
||||
<a zh_cn="深喉" zh_tw="深喉" jp="深喉" keyword=",深喉,"/>
|
||||
<a zh_cn="时间停止" zh_tw="時間停止" jp="時間停止" keyword=",时间停止,時間停止,"/>
|
||||
<a zh_cn="插入手指" zh_tw="插入手指" jp="手指插入" keyword=",手指插入,插入手指,"/>
|
||||
<a zh_cn="首次亮相" zh_tw="首次亮相" jp="首次亮相" keyword=",首次亮相,"/>
|
||||
<a zh_cn="叔母" zh_tw="叔母" jp="叔母さん" keyword=",叔母,叔母さん,"/>
|
||||
<a zh_cn="数位马赛克" zh_tw="數位馬賽克" jp="數位馬賽克" keyword=",數位馬賽克,数位马赛克,"/>
|
||||
<a zh_cn="双性人" zh_tw="雙性人" jp="雙性人" keyword=",雙性人,双性人,"/>
|
||||
<a zh_cn="韵律服" zh_tw="韻律服" jp="レオタード" keyword=",韵律服,韻律服,レオタード,"/>
|
||||
<a zh_cn="水手服" zh_tw="水手服" jp="セーラー服" keyword=",水手服,セーラー服,"/>
|
||||
<a zh_cn="丝袜" zh_tw="絲襪" jp="絲襪" keyword=",丝袜,絲襪,パンスト,"/>
|
||||
<a zh_cn="特摄" zh_tw="特攝" jp="特攝" keyword=",特效,特摄,特攝,"/>
|
||||
<a zh_cn="经历告白" zh_tw="經歷告白" jp="體驗懺悔" keyword=",體驗懺悔,经历告白,經歷告白,"/>
|
||||
<a zh_cn="体操服" zh_tw="體操服" jp="體育服" keyword=",体操服,體育服,體操服,"/>
|
||||
<a zh_cn="舔阴" zh_tw="舔陰" jp="舔陰" keyword=",舔陰,舔阴,舔鲍,クンニ,"/>
|
||||
<a zh_cn="跳蛋" zh_tw="跳蛋" jp="ローター" keyword=",跳蛋,ローター,"/>
|
||||
<a zh_cn="跳舞" zh_tw="跳舞" jp="跳舞" keyword=",跳舞,"/>
|
||||
<a zh_cn="青梅竹马" zh_tw="青梅竹馬" jp="童年朋友" keyword=",童年朋友,青梅竹马,青梅竹馬,"/>
|
||||
<a zh_cn="偷窥" zh_tw="偷窺" jp="偷窥" keyword=",偷窺,偷窥,"/>
|
||||
<a zh_cn="投稿" zh_tw="投稿" jp="投稿" keyword=",投稿,"/>
|
||||
<a zh_cn="赛车女郎" zh_tw="賽車女郎" jp="レースクィーン" keyword=",賽車女郎,赛车女郎,レースクィーン,"/>
|
||||
<a zh_cn="兔女郎" zh_tw="兔女郎" jp="兔女郎" keyword=",兔女郎,バニーガール,"/>
|
||||
<a zh_cn="吞精" zh_tw="吞精" jp="吞精" keyword=",吞精,ごっくん,"/>
|
||||
<a zh_cn="成人动画" zh_tw="成人動畫" jp="アニメ" keyword=",成人动画,成人動畫,アニメ,"/>
|
||||
<a zh_cn="成人娃娃" zh_tw="成人娃娃" jp="娃娃" keyword=",娃娃,成人娃娃,"/>
|
||||
<a zh_cn="玩物" zh_tw="玩物" jp="玩具" keyword=",玩具,玩物,"/>
|
||||
<a zh_cn="适合手机垂直播放" zh_tw="適合手機垂直播放" jp="為智能手機推薦垂直視頻" keyword=",スマホ専用縦動画,為智能手機推薦垂直視頻,适合手机垂直播放,適合手機垂直播放,"/>
|
||||
<a zh_cn="猥亵穿着" zh_tw="猥褻穿着" jp="猥褻穿著" keyword=",猥褻穿著,猥亵穿着,猥褻穿着,"/>
|
||||
<a zh_cn="无码流出" zh_tw="無碼流出" jp="无码流出" keyword=",無碼流出,无码流出,"/>
|
||||
<a zh_cn="无码破解" zh_tw="無碼破解" jp="無碼破解" keyword=",無碼破解,无码破解,"/>
|
||||
<a zh_cn="无毛" zh_tw="無毛" jp="無毛" keyword=",無毛,无毛,剃毛,白虎,パイパン,"/>
|
||||
<a zh_cn="剧情" zh_tw="劇情" jp="戲劇" keyword=",戲劇,戏剧,剧情,劇情,戲劇x,戏剧、连续剧,戲劇、連續劇,ドラマ,"/>
|
||||
<a zh_cn="性转换·男变女" zh_tw="性轉換·男變女" jp="性別轉型·女性化" keyword=",性转换・女体化,性別轉型·女性化,性转换·男变女,性轉換·男變女,"/>
|
||||
<a zh_cn="性奴" zh_tw="性奴" jp="性奴" keyword=",性奴,"/>
|
||||
<a zh_cn="性骚扰" zh_tw="性騷擾" jp="性騷擾" keyword=",性騷擾,性骚扰,"/>
|
||||
<a zh_cn="故意露胸" zh_tw="故意露胸" jp="胸チラ" keyword=",胸チラ,故意露胸,"/>
|
||||
<a zh_cn="羞耻" zh_tw="羞恥" jp="羞恥" keyword=",羞恥,羞耻,"/>
|
||||
<a zh_cn="学生" zh_tw="學生" jp="學生" keyword=",學生,其他學生,其他学生,學生(其他),学生,"/>
|
||||
<a zh_cn="学生妹" zh_tw="學生妹" jp="學生妹" keyword=",学生妹,學生妹,女子校生,"/>
|
||||
<a zh_cn="学生服" zh_tw="學生服" jp="學生服" keyword=",学生服,學生服,"/>
|
||||
<a zh_cn="学生泳装" zh_tw="學生泳裝" jp="學校泳裝" keyword=",學校泳裝,学校泳装,学生泳装,學生泳裝,校园泳装,校園泳裝,競泳・スクール水着,"/>
|
||||
<a zh_cn="泳装" zh_tw="泳裝" jp="水着" keyword=",泳裝,泳装,水着,"/>
|
||||
<a zh_cn="校园" zh_tw="校園" jp="學校作品" keyword=",學校作品,学校作品,校园,校園,校园物语,校園物語,学園もの,"/>
|
||||
<a zh_cn="肛检" zh_tw="肛檢" jp="鴨嘴" keyword=",鴨嘴,鸭嘴,肛检,肛檢,"/>
|
||||
<a zh_cn="骑脸" zh_tw="騎臉" jp="顏面騎乘" keyword=",騎乗位,颜面骑乘,顏面騎乘,骑脸,騎臉,"/>
|
||||
<a zh_cn="颜射" zh_tw="顏射" jp="顔射" keyword=",顏射,颜射,顏射x,顔射,"/>
|
||||
<a zh_cn="眼镜" zh_tw="眼鏡" jp="眼鏡" keyword=",眼鏡,眼镜,メガネ,"/>
|
||||
<a zh_cn="药物" zh_tw="藥物" jp="藥物" keyword=",藥物,药物,药物、迷姦,藥物、迷姦,ドラッグ,"/>
|
||||
<a zh_cn="野外露出" zh_tw="野外露出" jp="野外・露出" keyword=",野外・露出,野外露出,野外,"/>
|
||||
<a zh_cn="业余" zh_tw="業餘" jp="業餘" keyword=",業餘,业余,素人,"/>
|
||||
<a zh_cn="人妻" zh_tw="人妻" jp="已婚婦女" keyword=",已婚婦女,已婚妇女,人妻,"/>
|
||||
<a zh_cn="近亲相姦" zh_tw="近親相姦" jp="近親相姦" keyword=",近亲相姦,近親相姦,"/>
|
||||
<a zh_cn="自拍" zh_tw="自拍" jp="ハメ撮り" keyword=",自拍,ハメ撮り,個人撮影,个人撮影,"/>
|
||||
<a zh_cn="淫语" zh_tw="淫語" jp="淫語" keyword=",淫語,淫语,"/>
|
||||
<a zh_cn="酒会" zh_tw="酒會" jp="飲み会・合コン" keyword=",饮酒派对,飲み会・合コン,酒会,酒會,"/>
|
||||
<a zh_cn="饮尿" zh_tw="飲尿" jp="飲尿" keyword=",飲尿,饮尿,"/>
|
||||
<a zh_cn="游戏改" zh_tw="遊戲改" jp="遊戲的真人版" keyword=",遊戲的真人版,游戏改,遊戲改,"/>
|
||||
<a zh_cn="漫改" zh_tw="漫改" jp="原作コラボ" keyword=",原作改編,原作改编,原作コラボ,漫改,"/>
|
||||
<a zh_cn="受孕" zh_tw="受孕" jp="孕ませ" keyword=",受孕,孕ませ,"/>
|
||||
<a zh_cn="孕妇" zh_tw="孕婦" jp="孕婦" keyword=",孕婦,孕妇,"/>
|
||||
<a zh_cn="早泄" zh_tw="早泄" jp="早漏" keyword=",早洩,早漏,早泄,"/>
|
||||
<a zh_cn="Show Girl" zh_tw="Show Girl" jp="展場女孩" keyword=",展場女孩,展场女孩,Show Girl,"/>
|
||||
<a zh_cn="正太控" zh_tw="正太控" jp="正太控" keyword=",正太控,"/>
|
||||
<a zh_cn="制服" zh_tw="制服" jp="制服" keyword=",制服,"/>
|
||||
<a zh_cn="中出" zh_tw="中出" jp="中出" keyword=",中出,中出し,"/>
|
||||
<a zh_cn="子宫颈" zh_tw="子宮頸" jp="子宮頸" keyword=",子宮頸,子宫颈,"/>
|
||||
<a zh_cn="足交" zh_tw="足交" jp="足交" keyword=",足交,足コキ,"/>
|
||||
<a zh_cn="4小时+" zh_tw="4小時+" jp="4小時以上作品" keyword=",4小時以上作品,4小时以上作品,4小时+,4小時+,"/>
|
||||
<a zh_cn="69" zh_tw="69" jp="69" keyword=",69,"/>
|
||||
<a zh_cn="学生" zh_tw="學生" jp="學生" keyword=",C学生,學生,"/>
|
||||
<a zh_cn="M男" zh_tw="M男" jp="M男" keyword=",M男,"/>
|
||||
<a zh_cn="暗黑系" zh_tw="暗黑系" jp="暗黑系" keyword=",暗黑系,黑暗系統,"/>
|
||||
<a zh_cn="成人电影" zh_tw="成人電影" jp="成人電影" keyword=",成人電影,成人电影,"/>
|
||||
<a zh_cn="成人动漫" zh_tw="成人動漫" jp="成人動漫" keyword=",成人动漫,成人動漫,"/>
|
||||
<a zh_cn="导尿" zh_tw="導尿" jp="導尿" keyword=",導尿,导尿,"/>
|
||||
<a zh_cn="法国" zh_tw="法國" jp="法國" keyword=",法国,法國,"/>
|
||||
<a zh_cn="飞特族" zh_tw="飛特族" jp="飛特族" keyword=",飛特族,飞特族,"/>
|
||||
<a zh_cn="韩国" zh_tw="韓國" jp="韓國" keyword=",韓國,韩国,"/>
|
||||
<a zh_cn="户外" zh_tw="戶外" jp="戶外" keyword=",戶外,户外,"/>
|
||||
<a zh_cn="角色对换" zh_tw="角色對換" jp="角色對換" keyword=",角色对换,角色對換,"/>
|
||||
<a zh_cn="精选综合" zh_tw="精選綜合" jp="合集" keyword=",精選,綜合,精选、综合,合集,精选综合,精選綜合,"/>
|
||||
<a zh_cn="捆绑" zh_tw="捆綁" jp="捆綁" keyword=",捆綁,捆绑,折磨,"/>
|
||||
<a zh_cn="礼仪小姐" zh_tw="禮儀小姐" jp="禮儀小姐" keyword=",禮儀小姐,礼仪小姐,"/>
|
||||
<a zh_cn="历史剧" zh_tw="歷史劇" jp="歷史劇" keyword=",歷史劇,历史剧,"/>
|
||||
<a zh_cn="露出" zh_tw="露出" jp="露出" keyword=",露出,"/>
|
||||
<a zh_cn="母狗" zh_tw="母狗" jp="母狗" keyword=",母犬,母狗,"/>
|
||||
<a zh_cn="男优介绍" zh_tw="男優介紹" jp="男優介紹" keyword=",男性,男优介绍,男優介紹,"/>
|
||||
<a zh_cn="女儿" zh_tw="女兒" jp="女兒" keyword=",女兒,女儿,"/>
|
||||
<a zh_cn="全裸" zh_tw="全裸" jp="全裸" keyword=",全裸,"/>
|
||||
<a zh_cn="窥乳" zh_tw="窺乳" jp="窺乳" keyword=",乳房偷窺,窥乳,窺乳,"/>
|
||||
<a zh_cn="羞辱" zh_tw="羞辱" jp="辱め" keyword=",凌辱,羞辱,辱め,辱骂,辱罵,"/>
|
||||
<a zh_cn="脱衣" zh_tw="脫衣" jp="脫衣" keyword=",脫衣,脱衣,"/>
|
||||
<a zh_cn="西洋片" zh_tw="西洋片" jp="西洋片" keyword=",西洋片,"/>
|
||||
<a zh_cn="写真偶像" zh_tw="寫真偶像" jp="寫真偶像" keyword=",寫真偶像,写真偶像,"/>
|
||||
<a zh_cn="修女" zh_tw="修女" jp="修女" keyword=",修女,"/>
|
||||
<a zh_cn="偶像艺人" zh_tw="偶像藝人" jp="アイドル芸能人" keyword=",藝人,艺人,偶像,偶像藝人,偶像艺人,偶像‧藝人,偶像‧艺人,アイドル・芸能人,"/>
|
||||
<a zh_cn="淫乱真实" zh_tw="淫亂真實" jp="淫亂真實" keyword=",淫亂,真實,淫乱、真实,淫乱真实,淫亂真實,淫乱・ハード系,"/>
|
||||
<a zh_cn="瑜伽·健身" zh_tw="瑜伽·健身" jp="瑜伽·健身" keyword=",瑜伽,瑜伽·健身,ヨガ,講師,讲师"/>
|
||||
<a zh_cn="运动短裤" zh_tw="運動短褲" jp="運動短褲" keyword=",運動短褲,运动短裤,"/>
|
||||
<a zh_cn="JK制服" zh_tw="JK制服" jp="JK制服" keyword=",制服外套,JK制服,校服,"/>
|
||||
<a zh_cn="重制版" zh_tw="重製版" jp="複刻版" keyword=",重印版,複刻版,重制版,重製版,"/>
|
||||
<a zh_cn="综合短篇" zh_tw="綜合短篇" jp="綜合短篇" keyword=",綜合短篇,综合短篇,"/>
|
||||
<a zh_cn="被外国人干" zh_tw="被外國人乾" jp="被外國人乾" keyword=",被外國人幹,被外国人干,被外國人乾,"/>
|
||||
<a zh_cn="二穴同入" zh_tw="二穴同入" jp="二穴同入" keyword=",二穴同時挿入,二穴同入,"/>
|
||||
<a zh_cn="美脚" zh_tw="美腳" jp="美腳" keyword=",美腳,美脚,"/>
|
||||
<a zh_cn="过膝袜" zh_tw="過膝襪" jp="過膝襪" keyword=",絲襪、過膝襪,过膝袜,"/>
|
||||
<a zh_cn="名人" zh_tw="名人" jp="名人" keyword=",名人,"/>
|
||||
<a zh_cn="黑白配" zh_tw="黑白配" jp="黑白配" keyword=",黑白配,"/>
|
||||
<a zh_cn="欲女" zh_tw="欲女" jp="エマニエル" keyword=",エマニエル,欲女,"/>
|
||||
<a zh_cn="高筒靴" zh_tw="高筒靴" jp="高筒靴" keyword=",靴子,高筒靴,"/>
|
||||
<a zh_cn="双飞" zh_tw="雙飛" jp="雙飛" keyword=",兩女一男,双飞,雙飛,"/>
|
||||
<a zh_cn="两女两男" zh_tw="兩女兩男" jp="兩女兩男" keyword=",兩男兩女,两女两男,兩女兩男,"/>
|
||||
<a zh_cn="两男一女" zh_tw="兩男一女" jp="兩男一女" keyword=",兩男一女,两男一女,"/>
|
||||
<a zh_cn="3P" zh_tw="3P" jp="3P" keyword=",3P,3p,3P,3p,"/>
|
||||
<a zh_cn="唾液敷面" zh_tw="唾液敷面" jp="唾液敷面" keyword=",唾液敷面,"/>
|
||||
<a zh_cn="kira☆kira" zh_tw="kira☆kira" jp="kira☆kira" keyword=",kira☆kira,"/>
|
||||
<a zh_cn="S1 NO.1 STYLE" zh_tw="S1 NO.1 STYLE" jp="S1 NO.1 STYLE" keyword=",S1 Style,エスワン,エスワン ナンバーワンスタイル,エスワンナンバーワンスタイル,S1 NO.1 STYLE,S1NO.1STYLE,"/>
|
||||
<a zh_cn="一本道" zh_tw="一本道" jp="一本道" keyword=",一本道,"/>
|
||||
<a zh_cn="加勒比" zh_tw="加勒比" jp="加勒比" keyword=",加勒比,カリビアンコム,"/>
|
||||
<a zh_cn="东京热" zh_tw="東京熱" jp="TOKYO-HOT" keyword=",东京热,東京熱,東熱,TOKYO-HOT,"/>
|
||||
<a zh_cn="SOD" zh_tw="SOD" jp="SOD" keyword=",SOD,SODクリエイト,"/>
|
||||
<a zh_cn="PRESTIGE" zh_tw="PRESTIGE" jp="PRESTIGE" keyword=",PRESTIGE,プレステージ,"/>
|
||||
<a zh_cn="MOODYZ" zh_tw="MOODYZ" jp="MOODYZ" keyword=",MOODYZ,ムーディーズ,"/>
|
||||
<a zh_cn="ROCKET" zh_tw="ROCKET" jp="ROCKET" keyword=",ROCKET,"/>
|
||||
<a zh_cn="S级素人" zh_tw="S級素人" jp="S級素人" keyword=",S級素人,アイデアポケット,"/>
|
||||
<a zh_cn="HEYZO" zh_tw="HEYZO" jp="HEYZO" keyword=",HEYZO,"/>
|
||||
<a zh_cn="玛丹娜" zh_tw="瑪丹娜" jp="Madonna" keyword=",玛丹娜,瑪丹娜,マドンナ,Madonna,"/>
|
||||
<a zh_cn="MAXING" zh_tw="MAXING" jp="MAXING" keyword=",MAXING,マキシング,"/>
|
||||
<a zh_cn="JAPANKET" zh_tw="ALICE JAPAN" jp="ALICE JAPAN" keyword=",ALICE JAPAN,アリスJAPAN,"/>
|
||||
<a zh_cn="E-BODY" zh_tw="E-BODY" jp="E-BODY" keyword=",E-BODY,"/>
|
||||
<a zh_cn="Natural High" zh_tw="Natural High" jp="Natural High" keyword=",Natural High,ナチュラルハイ,"/>
|
||||
<a zh_cn="美" zh_tw="美" jp="美" keyword=",美,"/>
|
||||
<a zh_cn="K.M.P" zh_tw="K.M.P" jp="K.M.P" keyword=",K.M.P,ケイ・エム・プロデュース,"/>
|
||||
<a zh_cn="Hunter" zh_tw="Hunter" jp="Hunter" keyword=",Hunter,"/>
|
||||
<a zh_cn="OPPAI" zh_tw="OPPAI" jp="OPPAI" keyword=",OPPAI,"/>
|
||||
<a zh_cn="熘池五郎" zh_tw="溜池五郎" jp="溜池ゴロー" keyword=",熘池五郎,溜池五郎,溜池ゴロー,"/>
|
||||
<a zh_cn="kawaii" zh_tw="kawaii" jp="kawaii" keyword=",kawaii,"/>
|
||||
<a zh_cn="PREMIUM" zh_tw="PREMIUM" jp="PREMIUM" keyword=",PREMIUM,プレミアム,"/>
|
||||
<a zh_cn="ヤル男" zh_tw="ヤル男" jp="ヤル男" keyword=",ヤル男,"/>
|
||||
<a zh_cn="ラグジュTV" zh_tw="ラグジュTV" jp="ラグジュTV" keyword=",ラグジュTV,"/>
|
||||
<a zh_cn="シロウトTV" zh_tw="シロウトTV" jp="シロウトTV" keyword=",シロウトTV,"/>
|
||||
<a zh_cn="本中" zh_tw="本中" jp="本中" keyword=",本中,"/>
|
||||
<a zh_cn="WANZ" zh_tw="WANZ" jp="WANZ" keyword=",WANZ,ワンズファクトリー,"/>
|
||||
<a zh_cn="BeFree" zh_tw="BeFree" jp="BeFree" keyword=",BeFree,"/>
|
||||
<a zh_cn="MAX-A" zh_tw="MAX-A" jp="MAX-A" keyword=",MAX-A,マックスエー,"/>
|
||||
|
||||
</info>
|
||||
724
Movie_Data_Capture.py
Normal file
@@ -0,0 +1,724 @@
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import random
|
||||
import re
|
||||
import sys
|
||||
import time
|
||||
import shutil
|
||||
import typing
|
||||
import urllib3
|
||||
import signal
|
||||
import platform
|
||||
import config
|
||||
|
||||
from datetime import datetime, timedelta
|
||||
from lxml import etree
|
||||
from pathlib import Path
|
||||
from opencc import OpenCC
|
||||
|
||||
from scraper import get_data_from_json
|
||||
from ADC_function import file_modification_days, get_html, parallel_download_files
|
||||
from number_parser import get_number
|
||||
from core import core_main, core_main_no_net_op, moveFailedFolder, debug_print
|
||||
|
||||
|
||||
def check_update(local_version):
|
||||
htmlcode = get_html("https://api.github.com/repos/yoshiko2/Movie_Data_Capture/releases/latest")
|
||||
data = json.loads(htmlcode)
|
||||
remote = int(data["tag_name"].replace(".", ""))
|
||||
local_version = int(local_version.replace(".", ""))
|
||||
if local_version < remote:
|
||||
print("[*]" + ("* New update " + str(data["tag_name"]) + " *").center(54))
|
||||
print("[*]" + "↓ Download ↓".center(54))
|
||||
print("[*]https://github.com/yoshiko2/Movie_Data_Capture/releases")
|
||||
print("[*]======================================================")
|
||||
|
||||
|
||||
def argparse_function(ver: str) -> typing.Tuple[str, str, str, str, bool, bool, str, str]:
|
||||
conf = config.getInstance()
|
||||
parser = argparse.ArgumentParser(epilog=f"Load Config file '{conf.ini_path}'.")
|
||||
parser.add_argument("file", default='', nargs='?', help="Single Movie file path.")
|
||||
parser.add_argument("-p", "--path", default='', nargs='?', help="Analysis folder path.")
|
||||
parser.add_argument("-m", "--main-mode", default='', nargs='?',
|
||||
help="Main mode. 1:Scraping 2:Organizing 3:Scraping in analysis folder")
|
||||
parser.add_argument("-n", "--number", default='', nargs='?', help="Custom file number of single movie file.")
|
||||
# parser.add_argument("-C", "--config", default='config.ini', nargs='?', help="The config file Path.")
|
||||
parser.add_argument("-L", "--link-mode", default='', nargs='?',
|
||||
help="Create movie file link. 0:moving movie file, do not create link 1:soft link 2:try hard link first")
|
||||
default_logdir = str(Path.home() / '.mlogs')
|
||||
parser.add_argument("-o", "--log-dir", dest='logdir', default=default_logdir, nargs='?',
|
||||
help=f"""Duplicate stdout and stderr to logfiles in logging folder, default on.
|
||||
default folder for current user: '{default_logdir}'. Change default folder to an empty file,
|
||||
or use --log-dir= to turn log off.""")
|
||||
parser.add_argument("-q", "--regex-query", dest='regexstr', default='', nargs='?',
|
||||
help="python re module regex filepath filtering.")
|
||||
parser.add_argument("-d", "--nfo-skip-days", dest='days', default='', nargs='?',
|
||||
help="Override nfo_skip_days value in config.")
|
||||
parser.add_argument("-c", "--stop-counter", dest='cnt', default='', nargs='?',
|
||||
help="Override stop_counter value in config.")
|
||||
parser.add_argument("-R", "--rerun-delay", dest='delaytm', default='', nargs='?',
|
||||
help="Delay (eg. 1h10m30s or 60 (second)) time and rerun, until all movies proceed. Note: stop_counter value in config or -c must none zero.")
|
||||
parser.add_argument("-i", "--ignore-failed-list", action="store_true", help="Ignore failed list '{}'".format(
|
||||
os.path.join(os.path.abspath(conf.failed_folder()), 'failed_list.txt')))
|
||||
parser.add_argument("-a", "--auto-exit", action="store_true",
|
||||
help="Auto exit after program complete")
|
||||
parser.add_argument("-g", "--debug", action="store_true",
|
||||
help="Turn on debug mode to generate diagnostic log for issue report.")
|
||||
parser.add_argument("-N", "--no-network-operation", action="store_true",
|
||||
help="No network query, do not get metadata, for cover cropping purposes, only takes effect when main mode is 3.")
|
||||
parser.add_argument("-w", "--website", dest='site', default='', nargs='?',
|
||||
help="Override [priority]website= in config.")
|
||||
parser.add_argument("-D", "--download-images", dest='dnimg', action="store_true",
|
||||
help="Override [common]download_only_missing_images=0 force invoke image downloading.")
|
||||
parser.add_argument("-C", "--config-override", dest='cfgcmd', action='append', nargs=1,
|
||||
help="Common use config override. Grammar: section:key=value[;[section:]key=value] eg. 'de:s=1' or 'debug_mode:switch=1' override[debug_mode]switch=1 Note:this parameters can be used multiple times")
|
||||
parser.add_argument("-z", "--zero-operation", dest='zero_op', action="store_true",
|
||||
help="""Only show job list of files and numbers, and **NO** actual operation
|
||||
is performed. It may help you correct wrong numbers before real job.""")
|
||||
parser.add_argument("-v", "--version", action="version", version=ver)
|
||||
parser.add_argument("-s", "--search", default='', nargs='?', help="Search number")
|
||||
parser.add_argument("-ss", "--specified-source", default='', nargs='?', help="specified Source.")
|
||||
parser.add_argument("-su", "--specified-url", default='', nargs='?', help="specified Url.")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
def set_natural_number_or_none(sk, value):
|
||||
if isinstance(value, str) and value.isnumeric() and int(value) >= 0:
|
||||
conf.set_override(f'{sk}={value}')
|
||||
|
||||
def set_str_or_none(sk, value):
|
||||
if isinstance(value, str) and len(value):
|
||||
conf.set_override(f'{sk}={value}')
|
||||
|
||||
def set_bool_or_none(sk, value):
|
||||
if isinstance(value, bool) and value:
|
||||
conf.set_override(f'{sk}=1')
|
||||
|
||||
set_natural_number_or_none("common:main_mode", args.main_mode)
|
||||
set_natural_number_or_none("common:link_mode", args.link_mode)
|
||||
set_str_or_none("common:source_folder", args.path)
|
||||
set_bool_or_none("common:auto_exit", args.auto_exit)
|
||||
set_natural_number_or_none("common:nfo_skip_days", args.days)
|
||||
set_natural_number_or_none("advenced_sleep:stop_counter", args.cnt)
|
||||
set_bool_or_none("common:ignore_failed_list", args.ignore_failed_list)
|
||||
set_str_or_none("advenced_sleep:rerun_delay", args.delaytm)
|
||||
set_str_or_none("priority:website", args.site)
|
||||
if isinstance(args.dnimg, bool) and args.dnimg:
|
||||
conf.set_override("common:download_only_missing_images=0")
|
||||
set_bool_or_none("debug_mode:switch", args.debug)
|
||||
if isinstance(args.cfgcmd, list):
|
||||
for cmd in args.cfgcmd:
|
||||
conf.set_override(cmd[0])
|
||||
|
||||
no_net_op = False
|
||||
if conf.main_mode() == 3:
|
||||
no_net_op = args.no_network_operation
|
||||
if no_net_op:
|
||||
conf.set_override("advenced_sleep:stop_counter=0;advenced_sleep:rerun_delay=0s;face:aways_imagecut=1")
|
||||
|
||||
return args.file, args.number, args.logdir, args.regexstr, args.zero_op, no_net_op, args.search, args.specified_source, args.specified_url
|
||||
|
||||
|
||||
class OutLogger(object):
|
||||
def __init__(self, logfile) -> None:
|
||||
self.term = sys.stdout
|
||||
self.log = open(logfile, "w", encoding='utf-8', buffering=1)
|
||||
self.filepath = logfile
|
||||
|
||||
def __del__(self):
|
||||
self.close()
|
||||
|
||||
def __enter__(self):
|
||||
pass
|
||||
|
||||
def __exit__(self, *args):
|
||||
self.close()
|
||||
|
||||
def write(self, msg):
|
||||
self.term.write(msg)
|
||||
self.log.write(msg)
|
||||
|
||||
def flush(self):
|
||||
if 'flush' in dir(self.term):
|
||||
self.term.flush()
|
||||
if 'flush' in dir(self.log):
|
||||
self.log.flush()
|
||||
if 'fileno' in dir(self.log):
|
||||
os.fsync(self.log.fileno())
|
||||
|
||||
def close(self):
|
||||
if self.term is not None:
|
||||
sys.stdout = self.term
|
||||
self.term = None
|
||||
if self.log is not None:
|
||||
self.log.close()
|
||||
self.log = None
|
||||
|
||||
|
||||
class ErrLogger(OutLogger):
|
||||
|
||||
def __init__(self, logfile) -> None:
|
||||
self.term = sys.stderr
|
||||
self.log = open(logfile, "w", encoding='utf-8', buffering=1)
|
||||
self.filepath = logfile
|
||||
|
||||
def close(self):
|
||||
if self.term is not None:
|
||||
sys.stderr = self.term
|
||||
self.term = None
|
||||
|
||||
if self.log is not None:
|
||||
self.log.close()
|
||||
self.log = None
|
||||
|
||||
|
||||
def dupe_stdout_to_logfile(logdir: str):
|
||||
if not isinstance(logdir, str) or len(logdir) == 0:
|
||||
return
|
||||
log_dir = Path(logdir)
|
||||
if not log_dir.exists():
|
||||
try:
|
||||
log_dir.mkdir(parents=True, exist_ok=True)
|
||||
except:
|
||||
pass
|
||||
if not log_dir.is_dir():
|
||||
return # Tips for disabling logs by change directory to a same name empty regular file
|
||||
abslog_dir = log_dir.resolve()
|
||||
log_tmstr = datetime.now().strftime("%Y%m%dT%H%M%S")
|
||||
logfile = abslog_dir / f'mdc_{log_tmstr}.txt'
|
||||
errlog = abslog_dir / f'mdc_{log_tmstr}_err.txt'
|
||||
|
||||
sys.stdout = OutLogger(logfile)
|
||||
sys.stderr = ErrLogger(errlog)
|
||||
|
||||
|
||||
def close_logfile(logdir: str):
|
||||
if not isinstance(logdir, str) or len(logdir) == 0 or not os.path.isdir(logdir):
|
||||
return
|
||||
# 日志关闭前保存日志路径
|
||||
filepath = None
|
||||
try:
|
||||
filepath = sys.stdout.filepath
|
||||
except:
|
||||
pass
|
||||
sys.stdout.close()
|
||||
sys.stderr.close()
|
||||
log_dir = Path(logdir).resolve()
|
||||
if isinstance(filepath, Path):
|
||||
print(f"Log file '{filepath}' saved.")
|
||||
assert (filepath.parent.samefile(log_dir))
|
||||
# 清理空文件
|
||||
for f in log_dir.glob(r'*_err.txt'):
|
||||
if f.stat().st_size == 0:
|
||||
try:
|
||||
f.unlink(missing_ok=True)
|
||||
except:
|
||||
pass
|
||||
# 合并日志 只检测日志目录内的文本日志,忽略子目录。三天前的日志,按日合并为单个日志,三个月前的日志,
|
||||
# 按月合并为单个月志,去年及以前的月志,今年4月以后将之按年合并为年志
|
||||
# 测试步骤:
|
||||
"""
|
||||
LOGDIR=/tmp/mlog
|
||||
mkdir -p $LOGDIR
|
||||
for f in {2016..2020}{01..12}{01..28};do;echo $f>$LOGDIR/mdc_${f}T235959.txt;done
|
||||
for f in {01..09}{01..28};do;echo 2021$f>$LOGDIR/mdc_2021${f}T235959.txt;done
|
||||
for f in {00..23};do;echo 20211001T$f>$LOGDIR/mdc_20211001T${f}5959.txt;done
|
||||
echo "$(ls -1 $LOGDIR|wc -l) files in $LOGDIR"
|
||||
# 1932 files in /tmp/mlog
|
||||
mdc -zgic1 -d0 -m3 -o $LOGDIR
|
||||
# python3 ./Movie_Data_Capture.py -zgic1 -o $LOGDIR
|
||||
ls $LOGDIR
|
||||
# rm -rf $LOGDIR
|
||||
"""
|
||||
today = datetime.today()
|
||||
# 第一步,合并到日。3天前的日志,文件名是同一天的合并为一份日志
|
||||
for i in range(1):
|
||||
txts = [f for f in log_dir.glob(r'*.txt') if re.match(r'^mdc_\d{8}T\d{6}$', f.stem, re.A)]
|
||||
if not txts or not len(txts):
|
||||
break
|
||||
e = [f for f in txts if '_err' in f.stem]
|
||||
txts.sort()
|
||||
tmstr_3_days_ago = (today.replace(hour=0) - timedelta(days=3)).strftime("%Y%m%dT99")
|
||||
deadline_day = f'mdc_{tmstr_3_days_ago}'
|
||||
day_merge = [f for f in txts if f.stem < deadline_day]
|
||||
if not day_merge or not len(day_merge):
|
||||
break
|
||||
cutday = len('T235959.txt') # cut length mdc_20201201|T235959.txt
|
||||
for f in day_merge:
|
||||
try:
|
||||
day_file_name = str(f)[:-cutday] + '.txt' # mdc_20201201.txt
|
||||
with open(day_file_name, 'a', encoding='utf-8') as m:
|
||||
m.write(f.read_text(encoding='utf-8'))
|
||||
f.unlink(missing_ok=True)
|
||||
except:
|
||||
pass
|
||||
# 第二步,合并到月
|
||||
for i in range(1): # 利用1次循环的break跳到第二步,避免大块if缩进或者使用goto语法
|
||||
txts = [f for f in log_dir.glob(r'*.txt') if re.match(r'^mdc_\d{8}$', f.stem, re.A)]
|
||||
if not txts or not len(txts):
|
||||
break
|
||||
txts.sort()
|
||||
tmstr_3_month_ago = (today.replace(day=1) - timedelta(days=3 * 30)).strftime("%Y%m32")
|
||||
deadline_month = f'mdc_{tmstr_3_month_ago}'
|
||||
month_merge = [f for f in txts if f.stem < deadline_month]
|
||||
if not month_merge or not len(month_merge):
|
||||
break
|
||||
tomonth = len('01.txt') # cut length mdc_202012|01.txt
|
||||
for f in month_merge:
|
||||
try:
|
||||
month_file_name = str(f)[:-tomonth] + '.txt' # mdc_202012.txt
|
||||
with open(month_file_name, 'a', encoding='utf-8') as m:
|
||||
m.write(f.read_text(encoding='utf-8'))
|
||||
f.unlink(missing_ok=True)
|
||||
except:
|
||||
pass
|
||||
# 第三步,月合并到年
|
||||
for i in range(1):
|
||||
if today.month < 4:
|
||||
break
|
||||
mons = [f for f in log_dir.glob(r'*.txt') if re.match(r'^mdc_\d{6}$', f.stem, re.A)]
|
||||
if not mons or not len(mons):
|
||||
break
|
||||
mons.sort()
|
||||
deadline_year = f'mdc_{today.year - 1}13'
|
||||
year_merge = [f for f in mons if f.stem < deadline_year]
|
||||
if not year_merge or not len(year_merge):
|
||||
break
|
||||
toyear = len('12.txt') # cut length mdc_2020|12.txt
|
||||
for f in year_merge:
|
||||
try:
|
||||
year_file_name = str(f)[:-toyear] + '.txt' # mdc_2020.txt
|
||||
with open(year_file_name, 'a', encoding='utf-8') as y:
|
||||
y.write(f.read_text(encoding='utf-8'))
|
||||
f.unlink(missing_ok=True)
|
||||
except:
|
||||
pass
|
||||
# 第四步,压缩年志 如果有压缩需求,请自行手工压缩,或者使用外部脚本来定时完成。推荐nongnu的lzip,对于
|
||||
# 这种粒度的文本日志,压缩比是目前最好的。lzip -9的运行参数下,日志压缩比要高于xz -9,而且内存占用更少,
|
||||
# 多核利用率更高(plzip多线程版本),解压速度更快。压缩后的大小差不多是未压缩时的2.4%到3.7%左右,
|
||||
# 100MB的日志文件能缩小到3.7MB。
|
||||
return filepath
|
||||
|
||||
|
||||
def signal_handler(*args):
|
||||
print('[!]Ctrl+C detected, Exit.')
|
||||
os._exit(9)
|
||||
|
||||
|
||||
def sigdebug_handler(*args):
|
||||
conf = config.getInstance()
|
||||
conf.set_override(f"debug_mode:switch={int(not conf.debug())}")
|
||||
print(f"[!]Debug {('oFF', 'On')[int(conf.debug())]}")
|
||||
|
||||
|
||||
# 新增失败文件列表跳过处理,及.nfo修改天数跳过处理,提示跳过视频总数,调试模式(-g)下详细被跳过文件,跳过小广告
|
||||
def movie_lists(source_folder, regexstr: str) -> typing.List[str]:
|
||||
conf = config.getInstance()
|
||||
main_mode = conf.main_mode()
|
||||
debug = conf.debug()
|
||||
nfo_skip_days = conf.nfo_skip_days()
|
||||
link_mode = conf.link_mode()
|
||||
file_type = conf.media_type().lower().split(",")
|
||||
trailerRE = re.compile(r'-trailer\.', re.IGNORECASE)
|
||||
cliRE = None
|
||||
if isinstance(regexstr, str) and len(regexstr):
|
||||
try:
|
||||
cliRE = re.compile(regexstr, re.IGNORECASE)
|
||||
except:
|
||||
pass
|
||||
failed_list_txt_path = Path(conf.failed_folder()).resolve() / 'failed_list.txt'
|
||||
failed_set = set()
|
||||
if (main_mode == 3 or link_mode) and not conf.ignore_failed_list():
|
||||
try:
|
||||
flist = failed_list_txt_path.read_text(encoding='utf-8').splitlines()
|
||||
failed_set = set(flist)
|
||||
if len(flist) != len(failed_set): # 检查去重并写回,但是不改变failed_list.txt内条目的先后次序,重复的只保留最后的
|
||||
fset = failed_set.copy()
|
||||
for i in range(len(flist) - 1, -1, -1):
|
||||
fset.remove(flist[i]) if flist[i] in fset else flist.pop(i)
|
||||
failed_list_txt_path.write_text('\n'.join(flist) + '\n', encoding='utf-8')
|
||||
assert len(fset) == 0 and len(flist) == len(failed_set)
|
||||
except:
|
||||
pass
|
||||
if not Path(source_folder).is_dir():
|
||||
print('[-]Source folder not found!')
|
||||
return []
|
||||
total = []
|
||||
source = Path(source_folder).resolve()
|
||||
skip_failed_cnt, skip_nfo_days_cnt = 0, 0
|
||||
escape_folder_set = set(re.split("[,,]", conf.escape_folder()))
|
||||
for full_name in source.glob(r'**/*'):
|
||||
if main_mode != 3 and set(full_name.parent.parts) & escape_folder_set:
|
||||
continue
|
||||
if not full_name.is_file():
|
||||
continue
|
||||
if not full_name.suffix.lower() in file_type:
|
||||
continue
|
||||
absf = str(full_name)
|
||||
if absf in failed_set:
|
||||
skip_failed_cnt += 1
|
||||
if debug:
|
||||
print('[!]Skip failed movie:', absf)
|
||||
continue
|
||||
is_sym = full_name.is_symlink()
|
||||
if main_mode != 3 and (is_sym or (full_name.stat().st_nlink > 1 and not conf.scan_hardlink())): # 短路布尔 符号链接不取stat(),因为符号链接可能指向不存在目标
|
||||
continue # 模式不等于3下跳过软连接和未配置硬链接刮削
|
||||
# 调试用0字节样本允许通过,去除小于120MB的广告'苍老师强力推荐.mp4'(102.2MB)'黑道总裁.mp4'(98.4MB)'有趣的妹子激情表演.MP4'(95MB)'有趣的臺灣妹妹直播.mp4'(15.1MB)
|
||||
movie_size = 0 if is_sym else full_name.stat().st_size # 同上 符号链接不取stat()及st_size,直接赋0跳过小视频检测
|
||||
# if 0 < movie_size < 125829120: # 1024*1024*120=125829120
|
||||
# continue
|
||||
if cliRE and not cliRE.search(absf) or trailerRE.search(full_name.name):
|
||||
continue
|
||||
if main_mode == 3:
|
||||
nfo = full_name.with_suffix('.nfo')
|
||||
if not nfo.is_file():
|
||||
if debug:
|
||||
print(f"[!]Metadata {nfo.name} not found for '{absf}'")
|
||||
elif nfo_skip_days > 0 and file_modification_days(nfo) <= nfo_skip_days:
|
||||
skip_nfo_days_cnt += 1
|
||||
if debug:
|
||||
print(f"[!]Skip movie by it's .nfo which modified within {nfo_skip_days} days: '{absf}'")
|
||||
continue
|
||||
total.append(absf)
|
||||
|
||||
if skip_failed_cnt:
|
||||
print(f"[!]Skip {skip_failed_cnt} movies in failed list '{failed_list_txt_path}'.")
|
||||
if skip_nfo_days_cnt:
|
||||
print(
|
||||
f"[!]Skip {skip_nfo_days_cnt} movies in source folder '{source}' who's .nfo modified within {nfo_skip_days} days.")
|
||||
if nfo_skip_days <= 0 or not link_mode or main_mode == 3:
|
||||
return total
|
||||
# 软连接方式,已经成功削刮的也需要从成功目录中检查.nfo更新天数,跳过N天内更新过的
|
||||
skip_numbers = set()
|
||||
success_folder = Path(conf.success_folder()).resolve()
|
||||
for f in success_folder.glob(r'**/*'):
|
||||
if not re.match(r'\.nfo$', f.suffix, re.IGNORECASE):
|
||||
continue
|
||||
if file_modification_days(f) > nfo_skip_days:
|
||||
continue
|
||||
number = get_number(False, f.stem)
|
||||
if not number:
|
||||
continue
|
||||
skip_numbers.add(number.lower())
|
||||
|
||||
rm_list = []
|
||||
for f in total:
|
||||
n_number = get_number(False, os.path.basename(f))
|
||||
if n_number and n_number.lower() in skip_numbers:
|
||||
rm_list.append(f)
|
||||
for f in rm_list:
|
||||
total.remove(f)
|
||||
if debug:
|
||||
print(f"[!]Skip file successfully processed within {nfo_skip_days} days: '{f}'")
|
||||
if len(rm_list):
|
||||
print(
|
||||
f"[!]Skip {len(rm_list)} movies in success folder '{success_folder}' who's .nfo modified within {nfo_skip_days} days.")
|
||||
|
||||
return total
|
||||
|
||||
|
||||
def create_failed_folder(failed_folder: str):
|
||||
"""
|
||||
新建failed文件夹
|
||||
"""
|
||||
if not os.path.exists(failed_folder):
|
||||
try:
|
||||
os.makedirs(failed_folder)
|
||||
except:
|
||||
print(f"[-]Fatal error! Can not make folder '{failed_folder}'")
|
||||
os._exit(0)
|
||||
|
||||
|
||||
def rm_empty_folder(path):
|
||||
abspath = os.path.abspath(path)
|
||||
deleted = set()
|
||||
for current_dir, subdirs, files in os.walk(abspath, topdown=False):
|
||||
try:
|
||||
still_has_subdirs = any(_ for subdir in subdirs if os.path.join(current_dir, subdir) not in deleted)
|
||||
if not any(files) and not still_has_subdirs and not os.path.samefile(path, current_dir):
|
||||
os.rmdir(current_dir)
|
||||
deleted.add(current_dir)
|
||||
print('[+]Deleting empty folder', current_dir)
|
||||
except:
|
||||
pass
|
||||
|
||||
|
||||
def create_data_and_move(movie_path: str, zero_op: bool, no_net_op: bool, oCC):
|
||||
# Normalized number, eg: 111xxx-222.mp4 -> xxx-222.mp4
|
||||
debug = config.getInstance().debug()
|
||||
n_number = get_number(debug, os.path.basename(movie_path))
|
||||
movie_path = os.path.abspath(movie_path)
|
||||
|
||||
if debug is True:
|
||||
print(f"[!] [{n_number}] As Number Processing for '{movie_path}'")
|
||||
if zero_op:
|
||||
return
|
||||
if n_number:
|
||||
if no_net_op:
|
||||
core_main_no_net_op(movie_path, n_number)
|
||||
else:
|
||||
core_main(movie_path, n_number, oCC)
|
||||
else:
|
||||
print("[-] number empty ERROR")
|
||||
moveFailedFolder(movie_path)
|
||||
print("[*]======================================================")
|
||||
else:
|
||||
try:
|
||||
print(f"[!] [{n_number}] As Number Processing for '{movie_path}'")
|
||||
if zero_op:
|
||||
return
|
||||
if n_number:
|
||||
if no_net_op:
|
||||
core_main_no_net_op(movie_path, n_number)
|
||||
else:
|
||||
core_main(movie_path, n_number, oCC)
|
||||
else:
|
||||
raise ValueError("number empty")
|
||||
print("[*]======================================================")
|
||||
except Exception as err:
|
||||
print(f"[-] [{movie_path}] ERROR:")
|
||||
print('[-]', err)
|
||||
|
||||
try:
|
||||
moveFailedFolder(movie_path)
|
||||
except Exception as err:
|
||||
print('[!]', err)
|
||||
|
||||
|
||||
def create_data_and_move_with_custom_number(file_path: str, custom_number, oCC, specified_source, specified_url):
|
||||
conf = config.getInstance()
|
||||
file_name = os.path.basename(file_path)
|
||||
try:
|
||||
print("[!] [{1}] As Number Processing for '{0}'".format(file_path, custom_number))
|
||||
if custom_number:
|
||||
core_main(file_path, custom_number, oCC, specified_source, specified_url)
|
||||
else:
|
||||
print("[-] number empty ERROR")
|
||||
print("[*]======================================================")
|
||||
except Exception as err:
|
||||
print("[-] [{}] ERROR:".format(file_path))
|
||||
print('[-]', err)
|
||||
|
||||
if conf.link_mode():
|
||||
print("[-]Link {} to failed folder".format(file_path))
|
||||
os.symlink(file_path, os.path.join(conf.failed_folder(), file_name))
|
||||
else:
|
||||
try:
|
||||
print("[-]Move [{}] to failed folder".format(file_path))
|
||||
shutil.move(file_path, os.path.join(conf.failed_folder(), file_name))
|
||||
except Exception as err:
|
||||
print('[!]', err)
|
||||
|
||||
|
||||
def main(args: tuple) -> Path:
|
||||
(single_file_path, custom_number, logdir, regexstr, zero_op, no_net_op, search, specified_source,
|
||||
specified_url) = args
|
||||
conf = config.getInstance()
|
||||
main_mode = conf.main_mode()
|
||||
folder_path = ""
|
||||
if main_mode not in (1, 2, 3):
|
||||
print(f"[-]Main mode must be 1 or 2 or 3! You can run '{os.path.basename(sys.argv[0])} --help' for more help.")
|
||||
os._exit(4)
|
||||
|
||||
signal.signal(signal.SIGINT, signal_handler)
|
||||
if sys.platform == 'win32':
|
||||
signal.signal(signal.SIGBREAK, sigdebug_handler)
|
||||
else:
|
||||
signal.signal(signal.SIGWINCH, sigdebug_handler)
|
||||
dupe_stdout_to_logfile(logdir)
|
||||
|
||||
platform_total = str(
|
||||
' - ' + platform.platform() + ' \n[*] - ' + platform.machine() + ' - Python-' + platform.python_version())
|
||||
|
||||
print('[*]================= Movie Data Capture =================')
|
||||
print('[*]' + version.center(54))
|
||||
print('[*]======================================================')
|
||||
print('[*]' + platform_total)
|
||||
print('[*]======================================================')
|
||||
print('[*] - 严禁在墙内宣传本项目 - ')
|
||||
print('[*]======================================================')
|
||||
|
||||
start_time = time.time()
|
||||
print('[+]Start at', time.strftime("%Y-%m-%d %H:%M:%S"))
|
||||
|
||||
print(f"[+]Load Config file '{conf.ini_path}'.")
|
||||
if conf.debug():
|
||||
print('[+]Enable debug')
|
||||
if conf.link_mode() in (1, 2):
|
||||
print('[!]Enable {} link'.format(('soft', 'hard')[conf.link_mode() - 1]))
|
||||
if len(sys.argv) > 1:
|
||||
print('[!]CmdLine:', " ".join(sys.argv[1:]))
|
||||
print('[+]Main Working mode ## {}: {} ## {}{}{}'
|
||||
.format(*(main_mode, ['Scraping', 'Organizing', 'Scraping in analysis folder'][main_mode - 1],
|
||||
"" if not conf.multi_threading() else ", multi_threading on",
|
||||
"" if conf.nfo_skip_days() == 0 else f", nfo_skip_days={conf.nfo_skip_days()}",
|
||||
"" if conf.stop_counter() == 0 else f", stop_counter={conf.stop_counter()}"
|
||||
) if not single_file_path else ('-', 'Single File', '', '', ''))
|
||||
)
|
||||
|
||||
if conf.update_check():
|
||||
try:
|
||||
check_update(version)
|
||||
# Download Mapping Table, parallel version
|
||||
def fmd(f) -> typing.Tuple[str, Path]:
|
||||
return ('https://raw.githubusercontent.com/yoshiko2/Movie_Data_Capture/master/MappingTable/' + f,
|
||||
Path.home() / '.local' / 'share' / 'mdc' / f)
|
||||
|
||||
map_tab = (fmd('mapping_actor.xml'), fmd('mapping_info.xml'), fmd('c_number.json'))
|
||||
for k, v in map_tab:
|
||||
if v.exists():
|
||||
if file_modification_days(str(v)) >= conf.mapping_table_validity():
|
||||
print("[+]Mapping Table Out of date! Remove", str(v))
|
||||
os.remove(str(v))
|
||||
res = parallel_download_files(((k, v) for k, v in map_tab if not v.exists()))
|
||||
for i, fp in enumerate(res, start=1):
|
||||
if fp and len(fp):
|
||||
print(f"[+] [{i}/{len(res)}] Mapping Table Downloaded to {fp}")
|
||||
else:
|
||||
print(f"[-] [{i}/{len(res)}] Mapping Table Download failed")
|
||||
except:
|
||||
print("[!]" + " WARNING ".center(54, "="))
|
||||
print('[!]' + '-- GITHUB CONNECTION FAILED --'.center(54))
|
||||
print('[!]' + 'Failed to check for updates'.center(54))
|
||||
print('[!]' + '& update the mapping table'.center(54))
|
||||
print("[!]" + "".center(54, "="))
|
||||
try:
|
||||
etree.parse(str(Path.home() / '.local' / 'share' / 'mdc' / 'mapping_actor.xml'))
|
||||
except:
|
||||
print('[!]' + "Failed to load mapping table".center(54))
|
||||
print('[!]' + "".center(54, "="))
|
||||
|
||||
create_failed_folder(conf.failed_folder())
|
||||
|
||||
# create OpenCC converter
|
||||
ccm = conf.cc_convert_mode()
|
||||
try:
|
||||
oCC = None if ccm == 0 else OpenCC('t2s.json' if ccm == 1 else 's2t.json')
|
||||
except:
|
||||
# some OS no OpenCC cpython, try opencc-python-reimplemented.
|
||||
# pip uninstall opencc && pip install opencc-python-reimplemented
|
||||
oCC = None if ccm == 0 else OpenCC('t2s' if ccm == 1 else 's2t')
|
||||
|
||||
if not search == '':
|
||||
search_list = search.split(",")
|
||||
for i in search_list:
|
||||
json_data = get_data_from_json(i, oCC, None, None)
|
||||
debug_print(json_data)
|
||||
time.sleep(int(config.getInstance().sleep()))
|
||||
os._exit(0)
|
||||
|
||||
if not single_file_path == '': # Single File
|
||||
print('[+]==================== Single File =====================')
|
||||
if custom_number == '':
|
||||
create_data_and_move_with_custom_number(single_file_path,
|
||||
get_number(conf.debug(), os.path.basename(single_file_path)), oCC,
|
||||
specified_source, specified_url)
|
||||
else:
|
||||
create_data_and_move_with_custom_number(single_file_path, custom_number, oCC,
|
||||
specified_source, specified_url)
|
||||
else:
|
||||
folder_path = conf.source_folder()
|
||||
if not isinstance(folder_path, str) or folder_path == '':
|
||||
folder_path = os.path.abspath(".")
|
||||
|
||||
movie_list = movie_lists(folder_path, regexstr)
|
||||
|
||||
count = 0
|
||||
count_all = str(len(movie_list))
|
||||
print('[+]Find', count_all, 'movies.')
|
||||
print('[*]======================================================')
|
||||
stop_count = conf.stop_counter()
|
||||
if stop_count < 1:
|
||||
stop_count = 999999
|
||||
else:
|
||||
count_all = str(min(len(movie_list), stop_count))
|
||||
|
||||
for movie_path in movie_list: # 遍历电影列表 交给core处理
|
||||
count = count + 1
|
||||
percentage = str(count / int(count_all) * 100)[:4] + '%'
|
||||
print('[!] {:>30}{:>21}'.format('- ' + percentage + ' [' + str(count) + '/' + count_all + '] -',
|
||||
time.strftime("%H:%M:%S")))
|
||||
create_data_and_move(movie_path, zero_op, no_net_op, oCC)
|
||||
if count >= stop_count:
|
||||
print("[!]Stop counter triggered!")
|
||||
break
|
||||
sleep_seconds = random.randint(conf.sleep(), conf.sleep() + 2)
|
||||
time.sleep(sleep_seconds)
|
||||
|
||||
if conf.del_empty_folder() and not zero_op:
|
||||
rm_empty_folder(conf.success_folder())
|
||||
rm_empty_folder(conf.failed_folder())
|
||||
if len(folder_path):
|
||||
rm_empty_folder(folder_path)
|
||||
|
||||
end_time = time.time()
|
||||
total_time = str(timedelta(seconds=end_time - start_time))
|
||||
print("[+]Running time", total_time[:len(total_time) if total_time.rfind('.') < 0 else -3],
|
||||
" End at", time.strftime("%Y-%m-%d %H:%M:%S"))
|
||||
|
||||
print("[+]All finished!!!")
|
||||
|
||||
return close_logfile(logdir)
|
||||
|
||||
|
||||
def 分析日志文件(logfile):
|
||||
try:
|
||||
if not (isinstance(logfile, Path) and logfile.is_file()):
|
||||
raise FileNotFoundError('log file not found')
|
||||
logtxt = logfile.read_text(encoding='utf-8')
|
||||
扫描电影数 = int(re.findall(r'\[\+]Find (.*) movies\.', logtxt)[0])
|
||||
已处理 = int(re.findall(r'\[1/(.*?)] -', logtxt)[0])
|
||||
完成数 = logtxt.count(r'[+]Wrote!')
|
||||
return 扫描电影数, 已处理, 完成数
|
||||
except:
|
||||
return None, None, None
|
||||
|
||||
|
||||
def period(delta, pattern):
|
||||
d = {'d': delta.days}
|
||||
d['h'], rem = divmod(delta.seconds, 3600)
|
||||
d['m'], d['s'] = divmod(rem, 60)
|
||||
return pattern.format(**d)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
version = '6.6.7'
|
||||
urllib3.disable_warnings() # Ignore http proxy warning
|
||||
app_start = time.time()
|
||||
|
||||
# Read config.ini first, in argparse_function() need conf.failed_folder()
|
||||
conf = config.getInstance()
|
||||
|
||||
# Parse command line args
|
||||
args = tuple(argparse_function(version))
|
||||
|
||||
再运行延迟 = conf.rerun_delay()
|
||||
if 再运行延迟 > 0 and conf.stop_counter() > 0:
|
||||
while True:
|
||||
try:
|
||||
logfile = main(args)
|
||||
(扫描电影数, 已处理, 完成数) = 分析结果元组 = tuple(分析日志文件(logfile))
|
||||
if all(isinstance(v, int) for v in 分析结果元组):
|
||||
剩余个数 = 扫描电影数 - 已处理
|
||||
总用时 = timedelta(seconds = time.time() - app_start)
|
||||
print(f'All movies:{扫描电影数} processed:{已处理} successes:{完成数} remain:{剩余个数}' +
|
||||
' Elapsed time {}'.format(
|
||||
period(总用时, "{d} day {h}:{m:02}:{s:02}") if 总用时.days == 1
|
||||
else period(总用时, "{d} days {h}:{m:02}:{s:02}") if 总用时.days > 1
|
||||
else period(总用时, "{h}:{m:02}:{s:02}")))
|
||||
if 剩余个数 == 0:
|
||||
break
|
||||
下次运行 = datetime.now() + timedelta(seconds=再运行延迟)
|
||||
print(f'Next run time: {下次运行.strftime("%H:%M:%S")}, rerun_delay={再运行延迟}, press Ctrl+C stop run.')
|
||||
time.sleep(再运行延迟)
|
||||
else:
|
||||
break
|
||||
except:
|
||||
break
|
||||
else:
|
||||
main(args)
|
||||
|
||||
if not conf.auto_exit():
|
||||
if sys.platform == 'win32':
|
||||
input("Press enter key exit, you can check the error message before you exit...")
|
||||
295
README.md
@@ -1,268 +1,49 @@
|
||||
# AV Data Capture
|
||||
<h1 align="center">Movie Data Capture</h1>
|
||||
|
||||
[English](https://github.com/yoshiko2/Movie_Data_Capture/blob/master/README_EN.md)
|
||||
|
||||
<a title="Hits" target="_blank" href="https://github.com/yoshiko2/AV_Data_Capture"><img src="https://hits.b3log.org/yoshiko2/AV_Data_Capture.svg"></a>
|
||||

|
||||
<br>
|
||||

|
||||

|
||||
<br>
|
||||

|
||||

|
||||

|
||||
<br>
|
||||
[Docker 版本](https://github.com/vergilgao/docker-mdc)
|
||||

|
||||

|
||||

|
||||
<br>
|
||||
|
||||
**本地电影元数据 抓取工具 | 刮削器**,配合本地影片管理软件 Emby, Jellyfin, Kodi 等管理本地影片,该软件起到分类与元数据(metadata)抓取作用,利用元数据信息来分类,仅供本地影片分类整理使用。
|
||||
|
||||
**日本电影元数据 抓取工具 | 刮削器**,配合本地影片管理软件EMBY,KODI管理本地影片,该软件起到分类与元数据抓取作用,利用元数据信息来分类,供本地影片分类整理使用。
|
||||
**严禁在墙内的社交平台上宣传此项目**
|
||||
|
||||
# 目录
|
||||
* [免责声明](#免责声明)
|
||||
* [注意](#注意)
|
||||
* [你问我答 FAQ](#你问我答-faq)
|
||||
* [效果图](#效果图)
|
||||
* [如何使用](#如何使用)
|
||||
* [下载](#下载)
|
||||
* [简明教程](#简要教程)
|
||||
* [模块安装](#1请安装模块在cmd终端逐条输入以下命令安装)
|
||||
* [配置](#2配置configini)
|
||||
* [(可选)设置自定义目录和影片重命名规则](#3可选设置自定义目录和影片重命名规则)
|
||||
* [运行软件](#5运行-av_data_capturepyexe)
|
||||
* [影片原路径处理](#4建议把软件拷贝和电影的统一目录下)
|
||||
* [异常处理(重要)](#51异常处理重要)
|
||||
* [导入至媒体库](#7把jav_output文件夹导入到embykodi中等待元数据刷新完成)
|
||||
* [关于群晖NAS](#8关于群晖NAS)
|
||||
* [写在后面](#9写在后面)
|
||||
* [官方Twitter](https://twitter.com/mdac_official)
|
||||
|
||||
# 免责声明
|
||||
* 本软件仅供**技术交流,学术交流**使用,本项目旨在学习 Python3<br>
|
||||
* 本软件禁止用于任何非法用途<br>
|
||||
* 使用者使用该软件产生的一切法律后果由使用者承担<br>
|
||||
* 不可使用于商业和个人其他意图<br>
|
||||
* 使用该软件前,请自觉遵守当地法律法规
|
||||
# 文档
|
||||
* [官方教程WIKI](https://github.com/yoshiko2/Movie_Data_Capture/wiki)
|
||||
* [VergilGao's Docker部署](https://github.com/VergilGao/docker-mdc)
|
||||
|
||||
# 注意
|
||||
**推荐用法: 使用该软件后,对于不能正常获取元数据的电影可以用 Everaver 来补救**<br>
|
||||
暂不支持多P电影<br>
|
||||
# 申明
|
||||
当你查阅、下载了本项目源代码或二进制程序,即代表你接受了以下条款
|
||||
* 本项目和项目成果仅供技术,学术交流和Python3性能测试使用
|
||||
* 用户必须确保获取影片的途径在用户当地是合法的
|
||||
* 运行时和运行后所获取的元数据和封面图片等数据的版权,归版权持有人持有
|
||||
* 本项目贡献者编写该项目旨在学习Python3 ,提高编程水平
|
||||
* 本项目不提供任何影片下载的线索
|
||||
* 请勿提供运行时和运行后获取的数据提供给可能有非法目的的第三方,例如用于非法交易、侵犯未成年人的权利等
|
||||
* 用户仅能在自己的私人计算机或者测试环境中使用该工具,禁止将获取到的数据用于商业目的或其他目的,如销售、传播等
|
||||
* 用户在使用本项目和项目成果前,请用户了解并遵守当地法律法规,如果本项目及项目成果使用过程中存在违反当地法律法规的行为,请勿使用该项目及项目成果
|
||||
* 法律后果及使用后果由使用者承担
|
||||
* [GPL LICENSE](https://github.com/yoshiko2/Movie_Data_Capture/blob/master/LICENSE)
|
||||
* 若用户不同意上述条款任意一条,请勿使用本项目和项目成果
|
||||
|
||||
# 你问我答 FAQ
|
||||
### F:这软件能下片吗?
|
||||
**Q**:该软件不提供任何影片下载地址,仅供本地影片分类整理使用。
|
||||
### F:什么是元数据?
|
||||
**Q**:元数据包括了影片的:封面,导演,演员,简介,类型......
|
||||
### F:软件收费吗?
|
||||
**Q**:软件永久免费。除了 **作者** 钦点以外,给那些 **利用本软件牟利** 的人送上 **骨灰盒-全家族 | 崭新出厂**
|
||||
### F:软件运行异常怎么办?
|
||||
**Q**:认真看 [异常处理(重要)](#5异常处理重要)
|
||||
# 下载
|
||||
* [Releases](https://github.com/yoshiko2/Movie_Data_Capture/releases/latest)
|
||||
|
||||
# 效果图
|
||||
**图片来自网络**,由于相关法律法规,具体效果请自行联想
|
||||
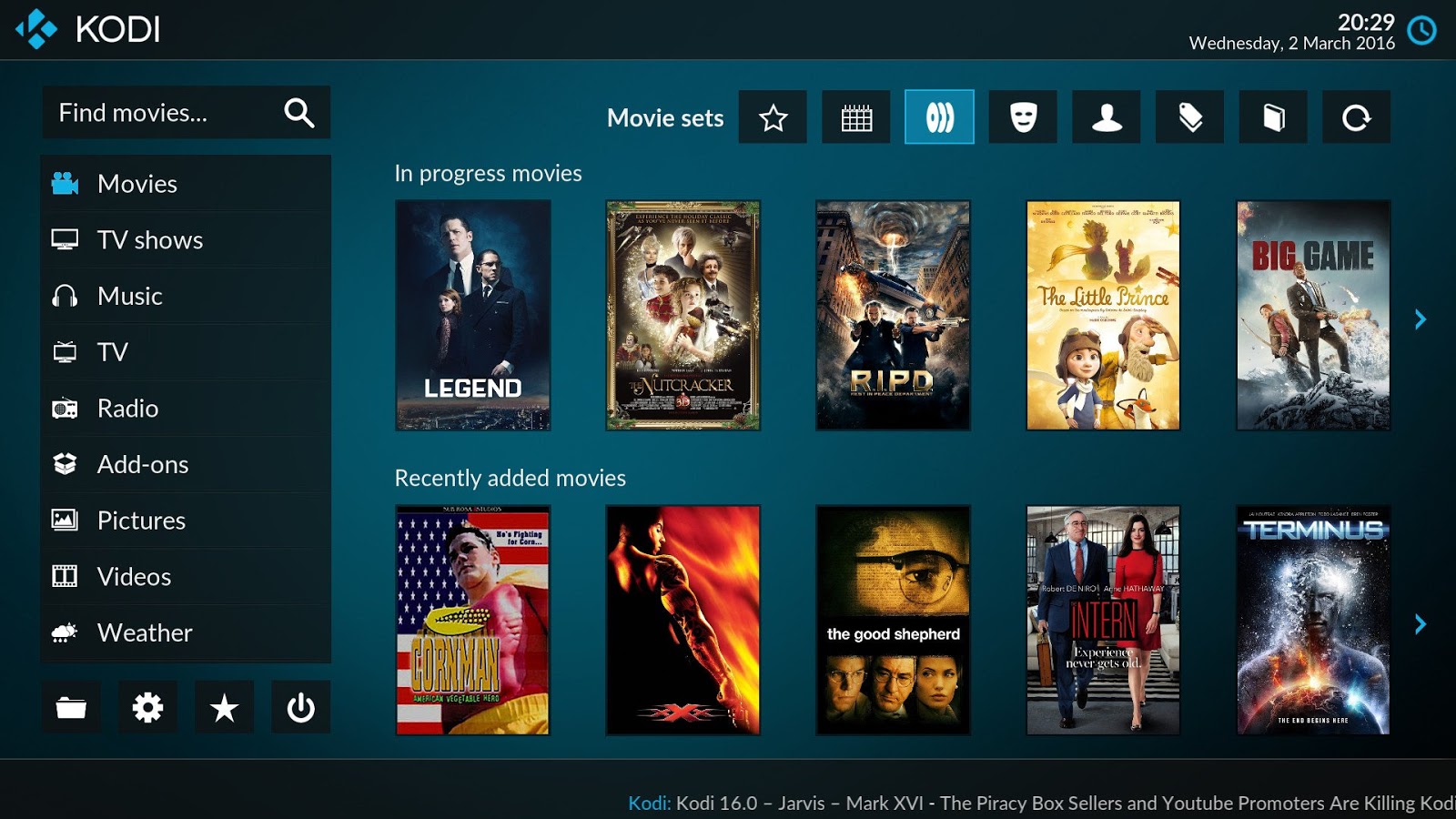
|
||||
<br>
|
||||
|
||||
# 如何使用
|
||||
### 下载
|
||||
* release的程序可脱离**python环境**运行,可跳过 [模块安装](#1请安装模块在cmd终端逐条输入以下命令安装)<br>Release 下载地址(**仅限Windows**):<br>[](https://github.com/yoshiko2/AV_Data_Capture/releases)<br>
|
||||
* Linux,MacOS请下载源码包运行
|
||||
|
||||
* Windows Python环境:[点击前往](https://www.python.org/downloads/windows/) 选中executable installer下载
|
||||
* MacOS Python环境:[点击前往](https://www.python.org/downloads/mac-osx/)
|
||||
* Linux Python环境:Linux用户懂的吧,不解释下载地址
|
||||
### 简要教程:<br>
|
||||
**1.把软件拉到和电影的同一目录<br>2.设置ini文件的代理(路由器拥有自动代理功能的可以把proxy=后面内容去掉)<br>3.运行软件等待完成<br>4.把JAV_output导入至KODI,EMBY中。<br>详细请看以下教程**<br>
|
||||
|
||||
## 1.请安装模块,在CMD/终端逐条输入以下命令安装
|
||||
```python
|
||||
pip install requests
|
||||
```
|
||||
###
|
||||
```python
|
||||
pip install pyquery
|
||||
```
|
||||
###
|
||||
```python
|
||||
pip install lxml
|
||||
```
|
||||
###
|
||||
```python
|
||||
pip install Beautifulsoup4
|
||||
```
|
||||
###
|
||||
```python
|
||||
pip install pillow
|
||||
```
|
||||
###
|
||||
|
||||
## 2.配置config.ini
|
||||
config.ini
|
||||
>[common]<br>
|
||||
>main_mode=1<br>
|
||||
>failed_output_folder=failed<br>
|
||||
>success_output_folder=JAV_output<br>
|
||||
>
|
||||
>[proxy]<br>
|
||||
>proxy=127.0.0.1:1080<br>
|
||||
>timeout=10<br>
|
||||
>retry=3<br>
|
||||
>
|
||||
>[Name_Rule]<br>
|
||||
>location_rule=actor+'/'+number<br>
|
||||
>naming_rule=number+'-'+title<br>
|
||||
>
|
||||
>[update]<br>
|
||||
>update_check=1<br>
|
||||
>
|
||||
>[media]<br>
|
||||
>media_warehouse=emby<br>
|
||||
>#emby or plex<br>
|
||||
>
|
||||
>[directory_capture]<br>
|
||||
>directory=<br>
|
||||
|
||||
### 全局设置
|
||||
---
|
||||
#### 软件模式
|
||||
>[common]<br>
|
||||
>main_mode=1<br>
|
||||
|
||||
1为普通模式,2为整理模式:仅根据女优把电影命名为番号并分类到女优名称的文件夹下
|
||||
|
||||
>failed_output_folder=failed<br>
|
||||
>success_output_folder=JAV_outputd<br>
|
||||
|
||||
设置成功输出目录和失败输出目录
|
||||
|
||||
---
|
||||
### 网络设置
|
||||
#### * 针对“某些地区”的代理设置
|
||||
打开```config.ini```,在```[proxy]```下的```proxy```行设置本地代理地址和端口,支持Shadowxxxx/X,V2XXX本地代理端口:<br>
|
||||
例子:```proxy=127.0.0.1:1080```<br>素人系列抓取建议使用日本代理<br>
|
||||
**路由器拥有自动代理功能的可以把proxy=后面内容去掉**<br>
|
||||
**本地代理软件开全局模式的同志同上**<br>
|
||||
**如果遇到tineout错误,可以把文件的proxy=后面的地址和端口删除,并开启vpn全局模式,或者重启电脑,vpn,网卡**<br>
|
||||
#### 连接超时重试设置
|
||||
>[proxy]<br>
|
||||
>timeout=10<br>
|
||||
|
||||
10为超时重试时间 单位:秒
|
||||
|
||||
---
|
||||
#### 连接重试次数设置
|
||||
>[proxy]<br>
|
||||
>retry=3<br>
|
||||
|
||||
3即为重试次数
|
||||
|
||||
---
|
||||
#### 检查更新开关
|
||||
>[update]<br>
|
||||
>update_check=1<br>
|
||||
|
||||
0为关闭,1为开启,不建议关闭
|
||||
|
||||
---
|
||||
##### 媒体库选择
|
||||
>[media]<br>
|
||||
>media_warehouse=emby<br>
|
||||
>#emby or plex<br>
|
||||
|
||||
可选择emby, plex<br>
|
||||
如果是PLEX,请安装插件:```XBMCnfoMoviesImporter```
|
||||
|
||||
---
|
||||
#### 调试模式
|
||||
>[debug_mode]<br>switch=1<br>
|
||||
|
||||
如要开启调试模式,请手动输入以上代码到```config.ini```中,开启后可在抓取中显示影片元数据
|
||||
|
||||
---
|
||||
#### 抓取目录选择
|
||||
>[directory_capture]<br>
|
||||
>directory=<br>
|
||||
如果directory后面为空,则抓取和程序同一目录下的影片,设置为``` * ```可抓取软件所在目录下的所有子目录中的影片
|
||||
### 3.(可选)设置自定义目录和影片重命名规则
|
||||
>[Name_Rule]<br>
|
||||
>location_rule=actor+'/'+number<br>
|
||||
>naming_rule=number+'-'+title<br>
|
||||
|
||||
已有默认配置
|
||||
|
||||
---
|
||||
#### 命名参数
|
||||
>title = 片名<br>
|
||||
>actor = 演员<br>
|
||||
>studio = 公司<br>
|
||||
>director = 导演<br>
|
||||
>release = 发售日<br>
|
||||
>year = 发行年份<br>
|
||||
>number = 番号<br>
|
||||
>cover = 封面链接<br>
|
||||
>tag = 类型<br>
|
||||
>outline = 简介<br>
|
||||
>runtime = 时长<br>
|
||||
|
||||
上面的参数以下都称之为**变量**
|
||||
|
||||
#### 例子:
|
||||
自定义规则方法:有两种元素,变量和字符,无论是任何一种元素之间连接必须要用加号 **+** ,比如:```'naming_rule=['+number+']-'+title```,其中冒号 ' ' 内的文字是字符,没有冒号包含的文字是变量,元素之间连接必须要用加号 **+** <br>
|
||||
目录结构规则:默认 ```location_rule=actor+'/'+number```<br> **不推荐修改时在这里添加title**,有时title过长,因为Windows API问题,抓取数据时新建文件夹容易出错。<br>
|
||||
影片命名规则:默认 ```naming_rule=number+'-'+title```<br> **在EMBY,KODI等本地媒体库显示的标题,不影响目录结构下影片文件的命名**,依旧是 番号+后缀。
|
||||
|
||||
### 更新开关
|
||||
>[update]<br>update_check=1<br>
|
||||
1为开,0为关
|
||||
|
||||
## 4.建议把软件拷贝和电影的统一目录下
|
||||
如果```config.ini```中```directory=```后面为空的情况下
|
||||
## 5.运行 ```AV_Data_capture.py/.exe```
|
||||
当文件名包含:<br>
|
||||
中文,字幕,-c., -C., 处理元数据时会加上**中文字幕**标签
|
||||
## 5.1 异常处理(重要)
|
||||
### 请确保软件是完整地!确保ini文件内容是和下载提供ini文件内容的一致的!
|
||||
---
|
||||
### 关于软件打开就闪退
|
||||
可以打开cmd命令提示符,把 ```AV_Data_capture.py/.exe```拖进cmd窗口回车运行,查看错误,出现的错误信息**依据以下条目解决**
|
||||
|
||||
---
|
||||
### 关于 ```Updata_check``` 和 ```JSON``` 相关的错误
|
||||
跳转 [网络设置](#网络设置)
|
||||
|
||||
---
|
||||
### 关于```FileNotFoundError: [WinError 3] 系统找不到指定的路径。: 'JAV_output''```
|
||||
在软件所在文件夹下新建 JAV_output 文件夹,可能是你没有把软件拉到和电影的同一目录
|
||||
|
||||
---
|
||||
### 关于连接拒绝的错误
|
||||
请设置好[代理](#针对某些地区的代理设置)<br>
|
||||
|
||||
---
|
||||
### 关于Nonetype,xpath报错
|
||||
同上<br>
|
||||
|
||||
---
|
||||
### 关于番号提取失败或者异常
|
||||
**目前可以提取元素的影片:JAVBUS上有元数据的电影,素人系列:300Maan,259luxu,siro等,FC2系列**<br>
|
||||
>下一张图片来自Pockies的blog 原作者已授权<br>
|
||||
|
||||
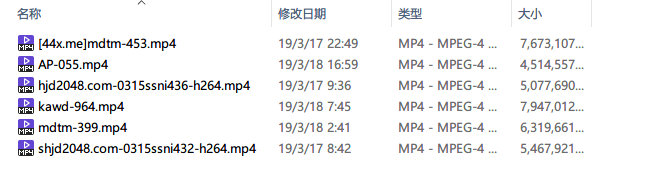
|
||||
|
||||
目前作者已经完善了番号提取机制,功能较为强大,可提取上述文件名的的番号,如果出现提取失败或者异常的情况,请用以下规则命名<br>
|
||||
**妈蛋不要喂软件那么多野鸡片子,不让软件好好活了,操**
|
||||
```
|
||||
COSQ-004.mp4
|
||||
```
|
||||
|
||||
针对 **野鸡番号** ,你需要把文件名命名为与抓取网站提供的番号一致(文件拓展名除外),然后把文件拖拽至core.exe/.py<br>
|
||||
**野鸡番号**:比如 ```XXX-XXX-1```, ```1301XX-MINA_YUKA``` 这种**野鸡**番号,在javbus等资料库存在的作品。<br>**重要**:除了 **影片文件名** ```XXXX-XXX-C```,后面这种-C的是指电影有中文字幕!<br>
|
||||
条件:文件名中间要有下划线或者减号"_","-",没有多余的内容只有番号为最佳,可以让软件更好获取元数据
|
||||
对于多影片重命名,可以用[ReNamer](http://www.den4b.com/products/renamer)来批量重命名<br>
|
||||
|
||||
---
|
||||
### 关于PIL/image.py
|
||||
暂时无解,可能是网络问题或者pillow模块打包问题,你可以用源码运行(要安装好第一步的模块)
|
||||
|
||||
|
||||
## 6.软件会自动把元数据获取成功的电影移动到JAV_output文件夹中,根据演员分类,失败的电影移动到failed文件夹中。
|
||||
## 7.把JAV_output文件夹导入到EMBY,KODI中,等待元数据刷新,完成
|
||||
## 8.关于群晖NAS
|
||||
开启SMB在Windows上挂载为网络磁盘即可使用本软件,也适用于其他NAS
|
||||
## 9.写在后面
|
||||
怎么样,看着自己的日本电影被这样完美地管理,是不是感觉成就感爆棚呢?<br>
|
||||
**tg官方电报群:[ 点击进群](https://t.me/AV_Data_Capture_Official)**<br>
|
||||
# 贡献者
|
||||
[](https://github.com/yoshiko2/movie_data_Capture/graphs/contributors)
|
||||
|
||||
# 友情链接
|
||||
* [CloudDrive](https://www.clouddrive2.com/)
|
||||
|
||||
# Star History
|
||||
[](https://star-history.com/#yoshiko2/Movie_Data_Capture&Date)
|
||||
|
||||
49
README_EN.md
Normal file
@@ -0,0 +1,49 @@
|
||||
<h1 align="center">Movie Data Capture</h1>
|
||||
|
||||

|
||||

|
||||

|
||||
<br>
|
||||
[Docker Edition](https://github.com/VergilGao/docker-mdc)
|
||||

|
||||

|
||||

|
||||
<br>
|
||||
|
||||
**Movie Metadata Scraper**, with local JAV management software Emby, Jellyfin, Kodi, etc. to manage local movies,
|
||||
the project plays the role of classification and metadata (metadata) grabbing, using metadata information to classify, only for local movie classification and organization.
|
||||
|
||||
[中文 | Chinese](https://github.com/yoshiko2/Movie_Data_Capture/blob/master/README.md)
|
||||
|
||||
# Documents
|
||||
* [Official WIKI](https://github.com/yoshiko2/Movie_Data_Capture/wiki/English)
|
||||
* [VergilGao's Docker Edition](https://github.com/VergilGao/docker-mdc)
|
||||
|
||||
# NOTICE
|
||||
When you view and download the source code or binary program of this project, it means that you have accepted the following terms:
|
||||
* **You must be over 18 years old, or leave the page immediately.**
|
||||
* This project and its results are for technical, academic exchange and Python3 performance testing purposes only.
|
||||
* The contributors to this project have written this project to learn Python3 and improve programming.
|
||||
* This project does not provide any movie download trail.
|
||||
* Legal consequences and the consequences of use are borne by the user.
|
||||
* [GPL LICENSE](https://github.com/yoshiko2/Movie_Data_Capture/blob/master/LICENSE)
|
||||
* If you do not agree to any of the above terms, please do not use the project and project results.
|
||||
|
||||
# Download
|
||||
* [Releases](https://github.com/yoshiko2/Movie_Data_Capture/releases/latest)
|
||||
|
||||
# Contributors
|
||||
[](https://github.com/yoshiko2/movie_data_Capture/graphs/contributors)
|
||||
|
||||
# Sponsor
|
||||
I am a college student and currently have high living and tuition costs and I want to reduce my financial dependence on my family.
|
||||
|
||||
If the program helps you, you can sponsor by:
|
||||
|
||||
## Crypto
|
||||
* USDT TRC-20: `TCVvFxeMuHFaECVMiHrxWD9b5QGX8DVQNV`
|
||||
* BTC: `3MyXrRyKbCG6mrB3KiWoYnifsPWNCiprwe`
|
||||
|
||||
For new functions and new feature requirements, all can be customized for a fee by communicating in the above way. And you can give me work to do.
|
||||
|
||||
Thanks!
|
||||
38
README_ZH.md
Normal file
@@ -0,0 +1,38 @@
|
||||
<h1 align="center">Movie Data Capture</h1>
|
||||
|
||||

|
||||

|
||||

|
||||
<br>
|
||||
[Docker 版本](https://github.com/yoshiko2/docker-mdc)
|
||||

|
||||

|
||||

|
||||
<br>
|
||||
|
||||
**本地电影元数据 抓取工具 | 刮削器**,配合本地影片管理软件 Emby, Jellyfin, Kodi 等管理本地影片,该软件起到分类与元数据(metadata)抓取作用,利用元数据信息来分类,仅供本地影片分类整理使用。
|
||||
### 请勿在墙内的社交平台上宣传此项目
|
||||
|
||||
# 文档
|
||||
* [官方教程WIKI](https://github.com/yoshiko2/Movie_Data_Capture/wiki)
|
||||
* [VergilGao's Docker部署](https://github.com/VergilGao/docker-mdc)
|
||||
|
||||
# 申明
|
||||
当你查阅、下载了本项目源代码或二进制程序,即代表你接受了以下条款
|
||||
* 本项目和项目成果仅供技术,学术交流和Python3性能测试使用
|
||||
* 本项目贡献者编写该项目旨在学习Python3 ,提高编程水平
|
||||
* 本项目不提供任何影片下载的线索
|
||||
* 用户在使用本项目和项目成果前,请用户了解并遵守当地法律法规,如果本项目及项目成果使用过程中存在违反当地法律法规的行为,请勿使用该项目及项目成果
|
||||
* 法律后果及使用后果由使用者承担
|
||||
* [GPL LICENSE](https://github.com/yoshiko2/Movie_Data_Capture/blob/master/LICENSE)
|
||||
* 若用户不同意上述条款任意一条,请勿使用本项目和项目成果
|
||||
|
||||
# 下载
|
||||
* [Releases](https://github.com/yoshiko2/Movie_Data_Capture/releases/latest)
|
||||
|
||||
# 贡献者
|
||||
[](https://github.com/yoshiko2/movie_data_Capture/graphs/contributors)
|
||||
|
||||
# Star History
|
||||
|
||||
[](https://star-history.com/#yoshiko2/Movie_Data_Capture&Date)
|
||||
112
avsox.py
@@ -1,112 +0,0 @@
|
||||
import re
|
||||
from lxml import etree
|
||||
import json
|
||||
from bs4 import BeautifulSoup
|
||||
from ADC_function import *
|
||||
|
||||
def getActorPhoto(htmlcode): #//*[@id="star_qdt"]/li/a/img
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find_all(attrs={'class': 'avatar-box'})
|
||||
d = {}
|
||||
for i in a:
|
||||
l = i.img['src']
|
||||
t = i.span.get_text()
|
||||
p2 = {t: l}
|
||||
d.update(p2)
|
||||
return d
|
||||
def getTitle(a):
|
||||
try:
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/h3/text()')).strip(" ['']") #[0]
|
||||
return result.replace('/', '')
|
||||
except:
|
||||
return ''
|
||||
def getActor(a): #//*[@id="center_column"]/div[2]/div[1]/div/table/tbody/tr[1]/td/text()
|
||||
soup = BeautifulSoup(a, 'lxml')
|
||||
a = soup.find_all(attrs={'class': 'avatar-box'})
|
||||
d = []
|
||||
for i in a:
|
||||
d.append(i.span.get_text())
|
||||
return d
|
||||
def getStudio(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//p[contains(text(),"制作商: ")]/following-sibling::p[1]/a/text()')).strip(" ['']").replace("', '",' ')
|
||||
return result1
|
||||
def getRuntime(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//span[contains(text(),"长度:")]/../text()')).strip(" ['分钟']")
|
||||
return result1
|
||||
def getLabel(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//p[contains(text(),"系列:")]/following-sibling::p[1]/a/text()')).strip(" ['']")
|
||||
return result1
|
||||
def getNum(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//span[contains(text(),"识别码:")]/../span[2]/text()')).strip(" ['']")
|
||||
return result1
|
||||
def getYear(release):
|
||||
try:
|
||||
result = str(re.search('\d{4}',release).group())
|
||||
return result
|
||||
except:
|
||||
return release
|
||||
def getRelease(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//span[contains(text(),"发行时间:")]/../text()')).strip(" ['']")
|
||||
return result1
|
||||
def getCover(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[2]/div[1]/div[1]/a/img/@src')).strip(" ['']")
|
||||
return result
|
||||
def getCover_small(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="waterfall"]/div/a/div[1]/img/@src')).strip(" ['']")
|
||||
return result
|
||||
def getTag(a): # 获取演员
|
||||
soup = BeautifulSoup(a, 'lxml')
|
||||
a = soup.find_all(attrs={'class': 'genre'})
|
||||
d = []
|
||||
for i in a:
|
||||
d.append(i.get_text())
|
||||
return d
|
||||
|
||||
def main(number):
|
||||
a = get_html('https://avsox.asia/cn/search/' + number)
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="waterfall"]/div/a/@href')).strip(" ['']")
|
||||
if result1 == '' or result1 == 'null' or result1 == 'None':
|
||||
a = get_html('https://avsox.asia/cn/search/' + number.replace('-', '_'))
|
||||
print(a)
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="waterfall"]/div/a/@href')).strip(" ['']")
|
||||
if result1 == '' or result1 == 'null' or result1 == 'None':
|
||||
a = get_html('https://avsox.asia/cn/search/' + number.replace('_', ''))
|
||||
print(a)
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="waterfall"]/div/a/@href')).strip(" ['']")
|
||||
web = get_html(result1)
|
||||
soup = BeautifulSoup(web, 'lxml')
|
||||
info = str(soup.find(attrs={'class': 'row movie'}))
|
||||
dic = {
|
||||
'actor': getActor(web),
|
||||
'title': getTitle(web).strip(getNum(web)),
|
||||
'studio': getStudio(info),
|
||||
'outline': '',#
|
||||
'runtime': getRuntime(info),
|
||||
'director': '', #
|
||||
'release': getRelease(info),
|
||||
'number': getNum(info),
|
||||
'cover': getCover(web),
|
||||
'cover_small': getCover_small(a),
|
||||
'imagecut': 3,
|
||||
'tag': getTag(web),
|
||||
'label': getLabel(info),
|
||||
'year': getYear(getRelease(info)), # str(re.search('\d{4}',getRelease(a)).group()),
|
||||
'actor_photo': getActorPhoto(web),
|
||||
'website': result1,
|
||||
'source': 'avsox.py',
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js
|
||||
|
||||
#print(main('041516_541'))
|
||||
159
config.ini
Normal file → Executable file
@@ -1,23 +1,156 @@
|
||||
# 详细教程请看
|
||||
# - https://github.com/yoshiko2/Movie_Data_Capture/wiki/%E9%85%8D%E7%BD%AE%E6%96%87%E4%BB%B6
|
||||
[common]
|
||||
main_mode=1
|
||||
failed_output_folder=failed
|
||||
success_output_folder=JAV_output
|
||||
main_mode = 1
|
||||
source_folder = ./
|
||||
failed_output_folder = failed
|
||||
success_output_folder = JAV_output
|
||||
link_mode = 0
|
||||
; 0: 不刮削硬链接文件 1: 刮削硬链接文件
|
||||
scan_hardlink = 0
|
||||
failed_move = 0
|
||||
auto_exit = 0
|
||||
translate_to_sc = 0
|
||||
multi_threading = 0
|
||||
;actor_gender value: female(♀) or male(♂) or both(♀ ♂) or all(♂ ♀ ⚧)
|
||||
actor_gender = female
|
||||
del_empty_folder = 1
|
||||
; 跳过最近(默认:30)天新修改过的.NFO,可避免整理模式(main_mode=3)和软连接(soft_link=0)时
|
||||
; 反复刮削靠前的视频文件,0为处理所有视频文件
|
||||
nfo_skip_days = 30
|
||||
ignore_failed_list = 0
|
||||
download_only_missing_images = 1
|
||||
mapping_table_validity = 7
|
||||
; 一些jellyfin中特有的设置 (0:不开启, 1:开启) 比如
|
||||
; 在jellyfin中tags和genres重复,因此可以只需保存genres到nfo中
|
||||
; jellyfin中只需要保存thumb,不需要保存fanart
|
||||
jellyfin = 0
|
||||
; 开启后tag和genere只显示演员
|
||||
actor_only_tag = 0
|
||||
sleep = 3
|
||||
anonymous_fill = 1
|
||||
|
||||
[advenced_sleep]
|
||||
; 处理完多少个视频文件后停止,0为处理所有视频文件
|
||||
stop_counter = 0
|
||||
; 再运行延迟时间,单位:h时m分s秒 举例: 1h30m45s(1小时30分45秒) 45(45秒)
|
||||
; stop_counter不为零的条件下才有效,每处理stop_counter部影片后延迟rerun_delay秒再次运行
|
||||
rerun_delay = 0
|
||||
; 以上参数配合使用可以以多次少量的方式刮削或整理数千个文件而不触发翻译或元数据站封禁
|
||||
|
||||
[proxy]
|
||||
proxy=127.0.0.1:1080
|
||||
timeout=10
|
||||
retry=3
|
||||
;proxytype: http or socks5 or socks5h switch: 0 1
|
||||
switch = 0
|
||||
type = socks5h
|
||||
proxy = 127.0.0.1:1080
|
||||
timeout = 20
|
||||
retry = 3
|
||||
cacert_file =
|
||||
|
||||
[Name_Rule]
|
||||
location_rule=actor+'/'+number
|
||||
naming_rule=number+'-'+title
|
||||
location_rule = actor+"/"+number
|
||||
naming_rule = number+"-"+title
|
||||
max_title_len = 50
|
||||
; 刮削后图片是否命名为番号
|
||||
image_naming_with_number = 0
|
||||
; 番号大写 1 | 0, 仅在写入数据时会进行大写转换, 搜索刮削流程则不影响
|
||||
number_uppercase = 0
|
||||
; 自定义正则表达式, 多个正则使用空格隔开, 第一个分组为提取的番号, 若自定义正则未能匹配到番号则使用默认规则
|
||||
; example: ([A-Za-z]{2,4}\-\d{3}) ([A-Za-z]{2,4}00\d{3})
|
||||
number_regexs =
|
||||
|
||||
[update]
|
||||
update_check=1
|
||||
update_check = 1
|
||||
|
||||
[priority]
|
||||
website = javbus,airav,fanza,xcity,mgstage,avsox,jav321,madou,javday,javmenu,javdb
|
||||
|
||||
[escape]
|
||||
literals = \()/
|
||||
folders = failed,JAV_output
|
||||
|
||||
[debug_mode]
|
||||
switch = 0
|
||||
|
||||
[translate]
|
||||
switch = 0
|
||||
; engine: google-free,azure,deeplx
|
||||
engine = google-free
|
||||
; en_us fr_fr de_de... (only google-free now)
|
||||
target_language = zh_cn
|
||||
; Azure translate API key
|
||||
key =
|
||||
; Translate delay, Bigger Better
|
||||
delay = 3
|
||||
; title,outline,actor,tag
|
||||
values = title,outline
|
||||
; Google translate site, or Deeplx site
|
||||
service_site = translate.google.com
|
||||
|
||||
; 预告片
|
||||
[trailer]
|
||||
switch = 0
|
||||
|
||||
[uncensored]
|
||||
uncensored_prefix = PT-,S2M,BT,LAF,SMD,SMBD,SM3D2DBD,SKY-,SKYHD,CWP,CWDV,CWBD,CW3D2DBD,MKD,MKBD,MXBD,MK3D2DBD,MCB3DBD,MCBD,RHJ,MMDV
|
||||
|
||||
[media]
|
||||
media_warehouse=emby
|
||||
#emby or plex
|
||||
media_type = .mp4,.avi,.rmvb,.wmv,.mov,.mkv,.flv,.ts,.webm,.iso,.mpg,.m4v
|
||||
sub_type = .smi,.srt,.idx,.sub,.sup,.psb,.ssa,.ass,.usf,.xss,.ssf,.rt,.lrc,.sbv,.vtt,.ttml
|
||||
|
||||
[directory_capture]
|
||||
directory=
|
||||
; 水印
|
||||
[watermark]
|
||||
switch = 1
|
||||
water = 2
|
||||
; 左上 0, 右上 1, 右下 2, 左下 3
|
||||
|
||||
; 剧照
|
||||
[extrafanart]
|
||||
switch = 1
|
||||
parallel_download = 5
|
||||
extrafanart_folder = extrafanart
|
||||
|
||||
; 剧情简介
|
||||
[storyline]
|
||||
switch = 1
|
||||
; website为javbus javdb avsox xcity carib时,site censored_site uncensored_site 为获取剧情简介信息的
|
||||
; 可选数据源站点列表。列表内站点同时并发查询,取值优先级由冒号前的序号决定,从小到大,数字小的站点没数据才会采用后面站点获得的。
|
||||
; 其中airavwiki airav avno1 58avgo是中文剧情简介,区别是airav只能查有码,avno1 airavwiki 有码无码都能查,
|
||||
; 58avgo只能查无码或者流出破解马赛克的影片(此功能没使用)。
|
||||
; xcity和amazon是日语的,由于amazon商城没有番号信息,选中对应DVD的准确率仅99.6%。如果三个列表全部为空则不查询,
|
||||
; 设置成不查询可大幅提高刮削速度。
|
||||
; site=
|
||||
site = airav,avno1,airavwiki
|
||||
censored_site = airav,avno1,xcity,amazon
|
||||
uncensored_site = 58avgo
|
||||
; 运行模式:0:顺序执行(最慢) 1:线程池(默认值) 2:进程池(启动开销比线程池大,并发站点越多越快)
|
||||
run_mode = 1
|
||||
; show_result剧情简介调试信息 0关闭 1简略 2详细(详细部分不记入日志),剧情简介失效时可打开2查看原因
|
||||
show_result = 0
|
||||
|
||||
; 繁简转换 繁简转换模式mode=0:不转换 1:繁转简 2:简转繁
|
||||
[cc_convert]
|
||||
mode = 1
|
||||
vars = outline,series,studio,tag,title
|
||||
|
||||
[javdb]
|
||||
sites = 521
|
||||
|
||||
; 人脸识别 locations_model=hog:方向梯度直方图(不太准确,速度快) cnn:深度学习模型(准确,需要GPU/CUDA,速度慢)
|
||||
; uncensored_only=0:对全部封面进行人脸识别 1:只识别无码封面,有码封面直接切右半部分
|
||||
; aways_imagecut=0:按各网站默认行为 1:总是裁剪封面,开启此项将无视[common]download_only_missing_images=1总是覆盖封面
|
||||
; 封面裁剪的宽高比可配置,公式为aspect_ratio/3。默认aspect_ratio=2.12: 适配大部分有码影片封面,前一版本默认为2/3即aspect_ratio=2
|
||||
[face]
|
||||
locations_model = hog
|
||||
uncensored_only = 1
|
||||
aways_imagecut = 0
|
||||
aspect_ratio = 2.12
|
||||
|
||||
[jellyfin]
|
||||
multi_part_fanart = 0
|
||||
|
||||
[actor_photo]
|
||||
download_for_kodi = 0
|
||||
|
||||
[direct]
|
||||
switch = 1
|
||||
|
||||
648
config.py
Normal file
@@ -0,0 +1,648 @@
|
||||
import os
|
||||
import re
|
||||
import sys
|
||||
import configparser
|
||||
import time
|
||||
import typing
|
||||
from pathlib import Path
|
||||
|
||||
G_conf_override = {
|
||||
# index 0 save Config() first instance for quick access by using getInstance()
|
||||
0: None,
|
||||
# register override config items
|
||||
# no need anymore
|
||||
}
|
||||
|
||||
|
||||
def getInstance():
|
||||
if isinstance(G_conf_override[0], Config):
|
||||
return G_conf_override[0]
|
||||
return Config()
|
||||
|
||||
|
||||
class Config:
|
||||
def __init__(self, path: str = "config.ini"):
|
||||
path_search_order = (
|
||||
Path(path),
|
||||
Path.cwd() / "config.ini",
|
||||
Path.home() / "mdc.ini",
|
||||
Path.home() / ".mdc.ini",
|
||||
Path.home() / ".mdc/config.ini",
|
||||
Path.home() / ".config/mdc/config.ini"
|
||||
)
|
||||
ini_path = None
|
||||
for p in path_search_order:
|
||||
if p.is_file():
|
||||
ini_path = p.resolve()
|
||||
break
|
||||
if ini_path:
|
||||
self.conf = configparser.ConfigParser()
|
||||
self.ini_path = ini_path
|
||||
try:
|
||||
if self.conf.read(ini_path, encoding="utf-8-sig"):
|
||||
if G_conf_override[0] is None:
|
||||
G_conf_override[0] = self
|
||||
except UnicodeDecodeError:
|
||||
if self.conf.read(ini_path, encoding="utf-8"):
|
||||
if G_conf_override[0] is None:
|
||||
G_conf_override[0] = self
|
||||
except Exception as e:
|
||||
print("ERROR: Config file can not read!")
|
||||
print("读取配置文件出错!")
|
||||
print('=================================')
|
||||
print(e)
|
||||
print("======= Auto exit in 60s ======== ")
|
||||
time.sleep(60)
|
||||
os._exit(-1)
|
||||
else:
|
||||
print("ERROR: Config file not found!")
|
||||
print("Please put config file into one of the following path:")
|
||||
print('\n'.join([str(p.resolve()) for p in path_search_order[2:]]))
|
||||
# 对于找不到配置文件的情况,还是在打包时附上对应版本的默认配置文件,有需要时为其在搜索路径中生成,
|
||||
# 要比用户乱找一个版本不对应的配置文件会可靠些。这样一来,单个执行文件就是功能完整的了,放在任何
|
||||
# 执行路径下都可以放心使用。
|
||||
res_path = None
|
||||
# pyinstaller打包的在打包中找config.ini
|
||||
if hasattr(sys, '_MEIPASS') and (Path(getattr(sys, '_MEIPASS')) / 'config.ini').is_file():
|
||||
res_path = Path(getattr(sys, '_MEIPASS')) / 'config.ini'
|
||||
# 脚本运行的所在位置找
|
||||
elif (Path(__file__).resolve().parent / 'config.ini').is_file():
|
||||
res_path = Path(__file__).resolve().parent / 'config.ini'
|
||||
if res_path is None:
|
||||
os._exit(2)
|
||||
ins = input("Or, Do you want me create a config file for you? (Yes/No)[Y]:")
|
||||
if re.search('n', ins, re.I):
|
||||
os._exit(2)
|
||||
# 用户目录才确定具有写权限,因此选择 ~/mdc.ini 作为配置文件生成路径,而不是有可能并没有写权限的
|
||||
# 当前目录。目前版本也不再鼓励使用当前路径放置配置文件了,只是作为多配置文件的切换技巧保留。
|
||||
write_path = path_search_order[2] # Path.home() / "mdc.ini"
|
||||
write_path.write_text(res_path.read_text(encoding='utf-8'), encoding='utf-8')
|
||||
print("Config file '{}' created.".format(write_path.resolve()))
|
||||
input("Press Enter key exit...")
|
||||
os._exit(0)
|
||||
# self.conf = self._default_config()
|
||||
# try:
|
||||
# self.conf = configparser.ConfigParser()
|
||||
# try: # From single crawler debug use only
|
||||
# self.conf.read('../' + path, encoding="utf-8-sig")
|
||||
# except:
|
||||
# self.conf.read('../' + path, encoding="utf-8")
|
||||
# except Exception as e:
|
||||
# print("[-]Config file not found! Use the default settings")
|
||||
# print("[-]",e)
|
||||
# os._exit(3)
|
||||
# #self.conf = self._default_config()
|
||||
|
||||
def set_override(self, option_cmd: str):
|
||||
"""
|
||||
通用的参数覆盖选项 -C 配置覆盖串
|
||||
配置覆盖串语法:小节名:键名=值[;[小节名:]键名=值][;[小节名:]键名+=值] 多个键用分号分隔 名称可省略部分尾部字符
|
||||
或 小节名:键名+=值[;[小节名:]键名=值][;[小节名:]键名+=值] 在已有值的末尾追加内容,多个键的=和+=可以交叉出现
|
||||
例子: face:aspect_ratio=2;aways_imagecut=1;priority:website=javdb
|
||||
小节名必须出现在开头至少一次,分号后可只出现键名=值,不再出现小节名,如果后续全部键名都属于同一个小节
|
||||
例如配置文件存在两个小节[proxy][priority],那么pro可指代proxy,pri可指代priority
|
||||
[face] ;face小节下方有4个键名locations_model= uncensored_only= aways_imagecut= aspect_ratio=
|
||||
l,lo,loc,loca,locat,locati...直到locations_model完整名称都可以用来指代locations_model=键名
|
||||
u,un,unc...直到uncensored_only完整名称都可以用来指代uncensored_only=键名
|
||||
aw,awa...直到aways_imagecut完整名称都可以用来指代aways_imagecut=键名
|
||||
as,asp...aspect_ratio完整名称都可以用来指代aspect_ratio=键名
|
||||
a则因为二义性,不是合法的省略键名
|
||||
"""
|
||||
def err_exit(str):
|
||||
print(str)
|
||||
os._exit(2)
|
||||
|
||||
sections = self.conf.sections()
|
||||
sec_name = None
|
||||
for cmd in option_cmd.split(';'):
|
||||
syntax_err = True
|
||||
rex = re.findall(r'^(.*?):(.*?)(=|\+=)(.*)$', cmd, re.U)
|
||||
if len(rex) and len(rex[0]) == 4:
|
||||
(sec, key, assign, val) = rex[0]
|
||||
sec_lo = sec.lower().strip()
|
||||
key_lo = key.lower().strip()
|
||||
syntax_err = False
|
||||
elif sec_name: # 已经出现过一次小节名,属于同一个小节的后续键名可以省略小节名
|
||||
rex = re.findall(r'^(.*?)(=|\+=)(.*)$', cmd, re.U)
|
||||
if len(rex) and len(rex[0]) == 3:
|
||||
(key, assign, val) = rex[0]
|
||||
sec_lo = sec_name.lower()
|
||||
key_lo = key.lower().strip()
|
||||
syntax_err = False
|
||||
if syntax_err:
|
||||
err_exit(f"[-]Config override syntax incorrect. example: 'd:s=1' or 'debug_mode:switch=1'. cmd='{cmd}' all='{option_cmd}'")
|
||||
if not len(sec_lo):
|
||||
err_exit(f"[-]Config override Section name '{sec}' is empty! cmd='{cmd}'")
|
||||
if not len(key_lo):
|
||||
err_exit(f"[-]Config override Key name '{key}' is empty! cmd='{cmd}'")
|
||||
if not len(val.strip()):
|
||||
print(f"[!]Conig overide value '{val}' is empty! cmd='{cmd}'")
|
||||
sec_name = None
|
||||
for s in sections:
|
||||
if not s.lower().startswith(sec_lo):
|
||||
continue
|
||||
if sec_name:
|
||||
err_exit(f"[-]Conig overide Section short name '{sec_lo}' is not unique! dup1='{sec_name}' dup2='{s}' cmd='{cmd}'")
|
||||
sec_name = s
|
||||
if sec_name is None:
|
||||
err_exit(f"[-]Conig overide Section name '{sec}' not found! cmd='{cmd}'")
|
||||
key_name = None
|
||||
keys = self.conf[sec_name]
|
||||
for k in keys:
|
||||
if not k.lower().startswith(key_lo):
|
||||
continue
|
||||
if key_name:
|
||||
err_exit(f"[-]Conig overide Key short name '{key_lo}' is not unique! dup1='{key_name}' dup2='{k}' cmd='{cmd}'")
|
||||
key_name = k
|
||||
if key_name is None:
|
||||
err_exit(f"[-]Conig overide Key name '{key}' not found! cmd='{cmd}'")
|
||||
if assign == "+=":
|
||||
val = keys[key_name] + val
|
||||
if self.debug():
|
||||
print(f"[!]Set config override [{sec_name}]{key_name}={val} by cmd='{cmd}'")
|
||||
self.conf.set(sec_name, key_name, val)
|
||||
|
||||
def main_mode(self) -> int:
|
||||
try:
|
||||
return self.conf.getint("common", "main_mode")
|
||||
except ValueError:
|
||||
self._exit("common:main_mode")
|
||||
|
||||
def source_folder(self) -> str:
|
||||
return self.conf.get("common", "source_folder").replace("\\\\", "/").replace("\\", "/")
|
||||
|
||||
def failed_folder(self) -> str:
|
||||
return self.conf.get("common", "failed_output_folder").replace("\\\\", "/").replace("\\", "/")
|
||||
|
||||
def success_folder(self) -> str:
|
||||
return self.conf.get("common", "success_output_folder").replace("\\\\", "/").replace("\\", "/")
|
||||
|
||||
def actor_gender(self) -> str:
|
||||
return self.conf.get("common", "actor_gender")
|
||||
|
||||
def link_mode(self) -> int:
|
||||
return self.conf.getint("common", "link_mode")
|
||||
|
||||
def scan_hardlink(self) -> bool:
|
||||
return self.conf.getboolean("common", "scan_hardlink", fallback=False)#未找到配置选项,默认不刮削
|
||||
|
||||
def failed_move(self) -> bool:
|
||||
return self.conf.getboolean("common", "failed_move")
|
||||
|
||||
def auto_exit(self) -> bool:
|
||||
return self.conf.getboolean("common", "auto_exit")
|
||||
|
||||
def translate_to_sc(self) -> bool:
|
||||
return self.conf.getboolean("common", "translate_to_sc")
|
||||
|
||||
def multi_threading(self) -> bool:
|
||||
return self.conf.getboolean("common", "multi_threading")
|
||||
|
||||
def del_empty_folder(self) -> bool:
|
||||
return self.conf.getboolean("common", "del_empty_folder")
|
||||
|
||||
def nfo_skip_days(self) -> int:
|
||||
return self.conf.getint("common", "nfo_skip_days", fallback=30)
|
||||
|
||||
def ignore_failed_list(self) -> bool:
|
||||
return self.conf.getboolean("common", "ignore_failed_list")
|
||||
|
||||
def download_only_missing_images(self) -> bool:
|
||||
return self.conf.getboolean("common", "download_only_missing_images")
|
||||
|
||||
def mapping_table_validity(self) -> int:
|
||||
return self.conf.getint("common", "mapping_table_validity")
|
||||
|
||||
def jellyfin(self) -> int:
|
||||
return self.conf.getint("common", "jellyfin")
|
||||
|
||||
def actor_only_tag(self) -> bool:
|
||||
return self.conf.getboolean("common", "actor_only_tag")
|
||||
|
||||
def sleep(self) -> int:
|
||||
return self.conf.getint("common", "sleep")
|
||||
|
||||
def anonymous_fill(self) -> bool:
|
||||
return self.conf.getint("common", "anonymous_fill")
|
||||
|
||||
def stop_counter(self) -> int:
|
||||
return self.conf.getint("advenced_sleep", "stop_counter", fallback=0)
|
||||
|
||||
def rerun_delay(self) -> int:
|
||||
value = self.conf.get("advenced_sleep", "rerun_delay")
|
||||
if not (isinstance(value, str) and re.match(r'^[\dsmh]+$', value, re.I)):
|
||||
return 0 # not match '1h30m45s' or '30' or '1s2m1h4s5m'
|
||||
if value.isnumeric() and int(value) >= 0:
|
||||
return int(value)
|
||||
sec = 0
|
||||
sec += sum(int(v) for v in re.findall(r'(\d+)s', value, re.I))
|
||||
sec += sum(int(v) for v in re.findall(r'(\d+)m', value, re.I)) * 60
|
||||
sec += sum(int(v) for v in re.findall(r'(\d+)h', value, re.I)) * 3600
|
||||
return sec
|
||||
|
||||
def is_translate(self) -> bool:
|
||||
return self.conf.getboolean("translate", "switch")
|
||||
|
||||
def is_trailer(self) -> bool:
|
||||
return self.conf.getboolean("trailer", "switch")
|
||||
|
||||
def is_watermark(self) -> bool:
|
||||
return self.conf.getboolean("watermark", "switch")
|
||||
|
||||
def is_extrafanart(self) -> bool:
|
||||
return self.conf.getboolean("extrafanart", "switch")
|
||||
|
||||
def extrafanart_thread_pool_download(self) -> int:
|
||||
try:
|
||||
v = self.conf.getint("extrafanart", "parallel_download")
|
||||
return v if v >= 0 else 5
|
||||
except:
|
||||
return 5
|
||||
|
||||
def watermark_type(self) -> int:
|
||||
return int(self.conf.get("watermark", "water"))
|
||||
|
||||
def get_uncensored(self):
|
||||
try:
|
||||
sec = "uncensored"
|
||||
uncensored_prefix = self.conf.get(sec, "uncensored_prefix")
|
||||
# uncensored_poster = self.conf.get(sec, "uncensored_poster")
|
||||
return uncensored_prefix
|
||||
|
||||
except ValueError:
|
||||
self._exit("uncensored")
|
||||
|
||||
def get_extrafanart(self):
|
||||
try:
|
||||
extrafanart_download = self.conf.get("extrafanart", "extrafanart_folder")
|
||||
return extrafanart_download
|
||||
except ValueError:
|
||||
self._exit("extrafanart_folder")
|
||||
|
||||
def get_translate_engine(self) -> str:
|
||||
return self.conf.get("translate", "engine")
|
||||
|
||||
def get_target_language(self) -> str:
|
||||
return self.conf.get("translate", "target_language")
|
||||
|
||||
# def get_translate_appId(self) ->str:
|
||||
# return self.conf.get("translate","appid")
|
||||
|
||||
def get_translate_key(self) -> str:
|
||||
return self.conf.get("translate", "key")
|
||||
|
||||
def get_translate_delay(self) -> int:
|
||||
return self.conf.getint("translate", "delay")
|
||||
|
||||
def translate_values(self) -> str:
|
||||
return self.conf.get("translate", "values")
|
||||
|
||||
def get_translate_service_site(self) -> str:
|
||||
return self.conf.get("translate", "service_site")
|
||||
|
||||
def proxy(self):
|
||||
try:
|
||||
sec = "proxy"
|
||||
switch = self.conf.get(sec, "switch")
|
||||
proxy = self.conf.get(sec, "proxy")
|
||||
timeout = self.conf.getint(sec, "timeout")
|
||||
retry = self.conf.getint(sec, "retry")
|
||||
proxytype = self.conf.get(sec, "type")
|
||||
iniProxy = IniProxy(switch, proxy, timeout, retry, proxytype)
|
||||
return iniProxy
|
||||
except ValueError:
|
||||
self._exit("common")
|
||||
|
||||
def cacert_file(self) -> str:
|
||||
return self.conf.get('proxy', 'cacert_file')
|
||||
|
||||
def media_type(self) -> str:
|
||||
return self.conf.get('media', 'media_type')
|
||||
|
||||
def sub_rule(self) -> typing.Set[str]:
|
||||
return set(self.conf.get('media', 'sub_type').lower().split(','))
|
||||
|
||||
def naming_rule(self) -> str:
|
||||
return self.conf.get("Name_Rule", "naming_rule")
|
||||
|
||||
def location_rule(self) -> str:
|
||||
return self.conf.get("Name_Rule", "location_rule")
|
||||
|
||||
def max_title_len(self) -> int:
|
||||
"""
|
||||
Maximum title length
|
||||
"""
|
||||
try:
|
||||
return self.conf.getint("Name_Rule", "max_title_len")
|
||||
except:
|
||||
return 50
|
||||
|
||||
def image_naming_with_number(self) -> bool:
|
||||
try:
|
||||
return self.conf.getboolean("Name_Rule", "image_naming_with_number")
|
||||
except:
|
||||
return False
|
||||
|
||||
def number_uppercase(self) -> bool:
|
||||
try:
|
||||
return self.conf.getboolean("Name_Rule", "number_uppercase")
|
||||
except:
|
||||
return False
|
||||
|
||||
def number_regexs(self) -> str:
|
||||
try:
|
||||
return self.conf.get("Name_Rule", "number_regexs")
|
||||
except:
|
||||
return ""
|
||||
|
||||
def update_check(self) -> bool:
|
||||
try:
|
||||
return self.conf.getboolean("update", "update_check")
|
||||
except ValueError:
|
||||
self._exit("update:update_check")
|
||||
|
||||
def sources(self) -> str:
|
||||
return self.conf.get("priority", "website")
|
||||
|
||||
def escape_literals(self) -> str:
|
||||
return self.conf.get("escape", "literals")
|
||||
|
||||
def escape_folder(self) -> str:
|
||||
return self.conf.get("escape", "folders")
|
||||
|
||||
def debug(self) -> bool:
|
||||
return self.conf.getboolean("debug_mode", "switch")
|
||||
|
||||
def get_direct(self) -> bool:
|
||||
return self.conf.getboolean("direct", "switch")
|
||||
|
||||
def is_storyline(self) -> bool:
|
||||
try:
|
||||
return self.conf.getboolean("storyline", "switch")
|
||||
except:
|
||||
return True
|
||||
|
||||
def storyline_site(self) -> str:
|
||||
try:
|
||||
return self.conf.get("storyline", "site")
|
||||
except:
|
||||
return "1:avno1,4:airavwiki"
|
||||
|
||||
def storyline_censored_site(self) -> str:
|
||||
try:
|
||||
return self.conf.get("storyline", "censored_site")
|
||||
except:
|
||||
return "2:airav,5:xcity,6:amazon"
|
||||
|
||||
def storyline_uncensored_site(self) -> str:
|
||||
try:
|
||||
return self.conf.get("storyline", "uncensored_site")
|
||||
except:
|
||||
return "3:58avgo"
|
||||
|
||||
def storyline_show(self) -> int:
|
||||
v = self.conf.getint("storyline", "show_result", fallback=0)
|
||||
return v if v in (0, 1, 2) else 2 if v > 2 else 0
|
||||
|
||||
def storyline_mode(self) -> int:
|
||||
return 1 if self.conf.getint("storyline", "run_mode", fallback=1) > 0 else 0
|
||||
|
||||
def cc_convert_mode(self) -> int:
|
||||
v = self.conf.getint("cc_convert", "mode", fallback=1)
|
||||
return v if v in (0, 1, 2) else 2 if v > 2 else 0
|
||||
|
||||
def cc_convert_vars(self) -> str:
|
||||
return self.conf.get("cc_convert", "vars",
|
||||
fallback="actor,director,label,outline,series,studio,tag,title")
|
||||
|
||||
def javdb_sites(self) -> str:
|
||||
return self.conf.get("javdb", "sites", fallback="38,39")
|
||||
|
||||
def face_locations_model(self) -> str:
|
||||
return self.conf.get("face", "locations_model", fallback="hog")
|
||||
|
||||
def face_uncensored_only(self) -> bool:
|
||||
return self.conf.getboolean("face", "uncensored_only", fallback=True)
|
||||
|
||||
def face_aways_imagecut(self) -> bool:
|
||||
return self.conf.getboolean("face", "aways_imagecut", fallback=False)
|
||||
|
||||
def face_aspect_ratio(self) -> float:
|
||||
return self.conf.getfloat("face", "aspect_ratio", fallback=2.12)
|
||||
|
||||
def jellyfin_multi_part_fanart(self) -> bool:
|
||||
return self.conf.getboolean("jellyfin", "multi_part_fanart", fallback=False)
|
||||
|
||||
def download_actor_photo_for_kodi(self) -> bool:
|
||||
return self.conf.getboolean("actor_photo", "download_for_kodi", fallback=False)
|
||||
|
||||
@staticmethod
|
||||
def _exit(sec: str) -> None:
|
||||
print("[-] Read config error! Please check the {} section in config.ini", sec)
|
||||
input("[-] Press ENTER key to exit.")
|
||||
exit()
|
||||
|
||||
@staticmethod
|
||||
def _default_config() -> configparser.ConfigParser:
|
||||
conf = configparser.ConfigParser()
|
||||
|
||||
sec1 = "common"
|
||||
conf.add_section(sec1)
|
||||
conf.set(sec1, "main_mode", "1")
|
||||
conf.set(sec1, "source_folder", "./")
|
||||
conf.set(sec1, "failed_output_folder", "failed")
|
||||
conf.set(sec1, "success_output_folder", "JAV_output")
|
||||
conf.set(sec1, "link_mode", "0")
|
||||
conf.set(sec1, "scan_hardlink", "0")
|
||||
conf.set(sec1, "failed_move", "1")
|
||||
conf.set(sec1, "auto_exit", "0")
|
||||
conf.set(sec1, "translate_to_sc", "1")
|
||||
# actor_gender value: female or male or both or all(含人妖)
|
||||
conf.set(sec1, "actor_gender", "female")
|
||||
conf.set(sec1, "del_empty_folder", "1")
|
||||
conf.set(sec1, "nfo_skip_days", "30")
|
||||
conf.set(sec1, "ignore_failed_list", "0")
|
||||
conf.set(sec1, "download_only_missing_images", "1")
|
||||
conf.set(sec1, "mapping_table_validity", "7")
|
||||
conf.set(sec1, "jellyfin", "0")
|
||||
conf.set(sec1, "actor_only_tag", "0")
|
||||
conf.set(sec1, "sleep", "3")
|
||||
conf.set(sec1, "anonymous_fill", "0")
|
||||
|
||||
sec2 = "advenced_sleep"
|
||||
conf.add_section(sec2)
|
||||
conf.set(sec2, "stop_counter", "0")
|
||||
conf.set(sec2, "rerun_delay", "0")
|
||||
|
||||
sec3 = "proxy"
|
||||
conf.add_section(sec3)
|
||||
conf.set(sec3, "proxy", "")
|
||||
conf.set(sec3, "timeout", "5")
|
||||
conf.set(sec3, "retry", "3")
|
||||
conf.set(sec3, "type", "socks5")
|
||||
conf.set(sec3, "cacert_file", "")
|
||||
|
||||
sec4 = "Name_Rule"
|
||||
conf.add_section(sec4)
|
||||
conf.set(sec4, "location_rule", "actor + '/' + number")
|
||||
conf.set(sec4, "naming_rule", "number + '-' + title")
|
||||
conf.set(sec4, "max_title_len", "50")
|
||||
conf.set(sec4, "image_naming_with_number", "0")
|
||||
conf.set(sec4, "number_uppercase", "0")
|
||||
conf.set(sec4, "number_regexs", "")
|
||||
|
||||
sec5 = "update"
|
||||
conf.add_section(sec5)
|
||||
conf.set(sec5, "update_check", "1")
|
||||
|
||||
sec6 = "priority"
|
||||
conf.add_section(sec6)
|
||||
conf.set(sec6, "website", "airav,javbus,javdb,fanza,xcity,mgstage,fc2,fc2club,avsox,jav321,xcity")
|
||||
|
||||
sec7 = "escape"
|
||||
conf.add_section(sec7)
|
||||
conf.set(sec7, "literals", "\()/") # noqa
|
||||
conf.set(sec7, "folders", "failed, JAV_output")
|
||||
|
||||
sec8 = "debug_mode"
|
||||
conf.add_section(sec8)
|
||||
conf.set(sec8, "switch", "0")
|
||||
|
||||
sec9 = "translate"
|
||||
conf.add_section(sec9)
|
||||
conf.set(sec9, "switch", "0")
|
||||
conf.set(sec9, "engine", "google-free")
|
||||
conf.set(sec9, "target_language", "zh_cn")
|
||||
# conf.set(sec8, "appid", "")
|
||||
conf.set(sec9, "key", "")
|
||||
conf.set(sec9, "delay", "1")
|
||||
conf.set(sec9, "values", "title,outline")
|
||||
conf.set(sec9, "service_site", "translate.google.cn")
|
||||
|
||||
sec10 = "trailer"
|
||||
conf.add_section(sec10)
|
||||
conf.set(sec10, "switch", "0")
|
||||
|
||||
sec11 = "uncensored"
|
||||
conf.add_section(sec11)
|
||||
conf.set(sec11, "uncensored_prefix", "S2M,BT,LAF,SMD")
|
||||
|
||||
sec12 = "media"
|
||||
conf.add_section(sec12)
|
||||
conf.set(sec12, "media_type",
|
||||
".mp4,.avi,.rmvb,.wmv,.mov,.mkv,.flv,.ts,.webm,iso")
|
||||
conf.set(sec12, "sub_type",
|
||||
".smi,.srt,.idx,.sub,.sup,.psb,.ssa,.ass,.usf,.xss,.ssf,.rt,.lrc,.sbv,.vtt,.ttml")
|
||||
|
||||
sec13 = "watermark"
|
||||
conf.add_section(sec13)
|
||||
conf.set(sec13, "switch", "1")
|
||||
conf.set(sec13, "water", "2")
|
||||
|
||||
sec14 = "extrafanart"
|
||||
conf.add_section(sec14)
|
||||
conf.set(sec14, "switch", "1")
|
||||
conf.set(sec14, "extrafanart_folder", "extrafanart")
|
||||
conf.set(sec14, "parallel_download", "1")
|
||||
|
||||
sec15 = "storyline"
|
||||
conf.add_section(sec15)
|
||||
conf.set(sec15, "switch", "1")
|
||||
conf.set(sec15, "site", "1:avno1,4:airavwiki")
|
||||
conf.set(sec15, "censored_site", "2:airav,5:xcity,6:amazon")
|
||||
conf.set(sec15, "uncensored_site", "3:58avgo")
|
||||
conf.set(sec15, "show_result", "0")
|
||||
conf.set(sec15, "run_mode", "1")
|
||||
conf.set(sec15, "cc_convert", "1")
|
||||
|
||||
sec16 = "cc_convert"
|
||||
conf.add_section(sec16)
|
||||
conf.set(sec16, "mode", "1")
|
||||
conf.set(sec16, "vars", "actor,director,label,outline,series,studio,tag,title")
|
||||
|
||||
sec17 = "javdb"
|
||||
conf.add_section(sec17)
|
||||
conf.set(sec17, "sites", "33,34")
|
||||
|
||||
sec18 = "face"
|
||||
conf.add_section(sec18)
|
||||
conf.set(sec18, "locations_model", "hog")
|
||||
conf.set(sec18, "uncensored_only", "1")
|
||||
conf.set(sec18, "aways_imagecut", "0")
|
||||
conf.set(sec18, "aspect_ratio", "2.12")
|
||||
|
||||
sec19 = "jellyfin"
|
||||
conf.add_section(sec19)
|
||||
conf.set(sec19, "multi_part_fanart", "0")
|
||||
|
||||
sec20 = "actor_photo"
|
||||
conf.add_section(sec20)
|
||||
conf.set(sec20, "download_for_kodi", "0")
|
||||
|
||||
return conf
|
||||
|
||||
|
||||
class IniProxy():
|
||||
""" Proxy Config from .ini
|
||||
"""
|
||||
SUPPORT_PROXY_TYPE = ("http", "socks5", "socks5h")
|
||||
|
||||
enable = False
|
||||
address = ""
|
||||
timeout = 5
|
||||
retry = 3
|
||||
proxytype = "socks5"
|
||||
|
||||
def __init__(self, switch, address, timeout, retry, proxytype) -> None:
|
||||
""" Initial Proxy from .ini
|
||||
"""
|
||||
if switch == '1' or switch == 1:
|
||||
self.enable = True
|
||||
self.address = address
|
||||
self.timeout = timeout
|
||||
self.retry = retry
|
||||
self.proxytype = proxytype
|
||||
|
||||
def proxies(self):
|
||||
"""
|
||||
获得代理参数,默认http代理
|
||||
get proxy params, use http proxy for default
|
||||
"""
|
||||
if self.address:
|
||||
if self.proxytype in self.SUPPORT_PROXY_TYPE:
|
||||
proxies = {"http": self.proxytype + "://" + self.address,
|
||||
"https": self.proxytype + "://" + self.address}
|
||||
else:
|
||||
proxies = {"http": "http://" + self.address, "https": "https://" + self.address}
|
||||
else:
|
||||
proxies = {}
|
||||
|
||||
return proxies
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
def evprint(evstr):
|
||||
code = compile(evstr, "<string>", "eval")
|
||||
print('{}: "{}"'.format(evstr, eval(code)))
|
||||
|
||||
|
||||
config = Config()
|
||||
mfilter = {'conf', 'proxy', '_exit', '_default_config', 'ini_path', 'set_override'}
|
||||
for _m in [m for m in dir(config) if not m.startswith('__') and m not in mfilter]:
|
||||
evprint(f'config.{_m}()')
|
||||
pfilter = {'proxies', 'SUPPORT_PROXY_TYPE'}
|
||||
# test getInstance()
|
||||
assert (getInstance() == config)
|
||||
for _p in [p for p in dir(getInstance().proxy()) if not p.startswith('__') and p not in pfilter]:
|
||||
evprint(f'getInstance().proxy().{_p}')
|
||||
|
||||
# Create new instance
|
||||
conf2 = Config()
|
||||
assert getInstance() != conf2
|
||||
assert getInstance() == config
|
||||
|
||||
conf2.set_override("d:s=1;face:asp=2;f:aw=0;pri:w=javdb;f:l=")
|
||||
assert conf2.face_aspect_ratio() == 2
|
||||
assert conf2.face_aways_imagecut() == False
|
||||
assert conf2.sources() == "javdb"
|
||||
print(f"Load Config file '{conf2.ini_path}'.")
|
||||
16
docker/Dockerfile
Normal file
@@ -0,0 +1,16 @@
|
||||
FROM python:slim
|
||||
RUN sed -i 's/deb.debian.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list \
|
||||
&& sed -i 's/security.debian.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list
|
||||
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pip -U \
|
||||
&& pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
|
||||
|
||||
RUN apt-get update \
|
||||
&& apt-get install -y wget ca-certificates \
|
||||
&& wget -O - 'https://github.com/yoshiko2/AV_Data_Capture/archive/master.tar.gz' | tar xz \
|
||||
&& mv AV_Data_Capture-master /jav \
|
||||
&& cd /jav \
|
||||
&& ( pip install --no-cache-dir -r requirements.txt || true ) \
|
||||
&& pip install --no-cache-dir requests lxml Beautifulsoup4 pillow \
|
||||
&& apt-get purge -y wget
|
||||
|
||||
WORKDIR /jav
|
||||
27
docker/config.ini
Normal file
@@ -0,0 +1,27 @@
|
||||
[common]
|
||||
main_mode=1
|
||||
failed_output_folder=data/failure_output
|
||||
success_output_folder=data/organized
|
||||
link_mode=0
|
||||
|
||||
[proxy]
|
||||
proxy=
|
||||
timeout=10
|
||||
retry=3
|
||||
|
||||
[Name_Rule]
|
||||
location_rule=actor+'/'+number
|
||||
naming_rule=number+'-'+title
|
||||
|
||||
[update]
|
||||
update_check=0
|
||||
|
||||
[escape]
|
||||
literals=\()/
|
||||
folders=data/failure_output,data/organized
|
||||
|
||||
[debug_mode]
|
||||
switch=0
|
||||
|
||||
[media]
|
||||
media_warehouse=plex
|
||||
13
docker/docker-compose.yaml
Normal file
@@ -0,0 +1,13 @@
|
||||
version: "2.2"
|
||||
services:
|
||||
jav:
|
||||
user: "${JAVUID}:${JAVGID}"
|
||||
image: jav:local
|
||||
build: .
|
||||
volumes:
|
||||
- ./config.ini:/jav/config.ini
|
||||
- ${JAV_PATH}:/jav/data
|
||||
command:
|
||||
- python
|
||||
- /jav/AV_Data_Capture.py
|
||||
- -a
|
||||
BIN
donate.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 163 KiB |
@@ -1,75 +0,0 @@
|
||||
import re
|
||||
from lxml import etree#need install
|
||||
import json
|
||||
import ADC_function
|
||||
|
||||
def getTitle(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/h2/text()')).strip(" ['']")
|
||||
return result
|
||||
def getActor(htmlcode):
|
||||
try:
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[2]/dl/dd[5]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
except:
|
||||
return ''
|
||||
def getStudio(htmlcode): #获取厂商
|
||||
try:
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[2]/dl/dd[5]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
except:
|
||||
return ''
|
||||
def getNum(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getRelease(htmlcode2): #
|
||||
html=etree.fromstring(htmlcode2,etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[2]/dl/dd[4]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getCover(htmlcode2): #获取厂商 #
|
||||
html = etree.fromstring(htmlcode2, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[1]/div/div[1]/a/img/@src')).strip(" ['']")
|
||||
return 'http:' + result
|
||||
def getOutline(htmlcode2): #获取番号 #
|
||||
html = etree.fromstring(htmlcode2, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="container"]/div[1]/div/article/section[4]/p/text()')).strip(" ['']").replace("\\n",'',10000).replace("'",'',10000).replace(', ,','').strip(' ').replace('。,',',')
|
||||
return result
|
||||
def getTag(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = html.xpath('//*[@id="container"]/div[1]/div/article/section[6]/ul/li/a/text()')
|
||||
return result
|
||||
def getYear(release):
|
||||
try:
|
||||
result = re.search('\d{4}',release).group()
|
||||
return result
|
||||
except:
|
||||
return ''
|
||||
|
||||
def main(number):
|
||||
number=number.replace('PPV','').replace('ppv','').strip('fc2_').strip('fc2-').strip('ppv-').strip('PPV-').strip('FC2_').strip('FC2-').strip('ppv-').strip('PPV-').replace('fc2ppv-','').replace('FC2PPV-','')
|
||||
htmlcode2 = ADC_function.get_html('http://adult.contents.fc2.com/article_search.php?id='+str(number).lstrip("FC2-").lstrip("fc2-").lstrip("fc2_").lstrip("fc2-")+'')
|
||||
#htmlcode = ADC_function.get_html('http://fc2fans.club/html/FC2-' + number + '.html')
|
||||
dic = {
|
||||
'title': getTitle(htmlcode2),
|
||||
'studio': getStudio(htmlcode2),
|
||||
'year': getYear(getRelease(htmlcode2)),
|
||||
'outline': getOutline(htmlcode2),
|
||||
'runtime': getYear(getRelease(htmlcode2)),
|
||||
'director': getStudio(htmlcode2),
|
||||
'actor': getStudio(htmlcode2),
|
||||
'release': getRelease(htmlcode2),
|
||||
'number': 'FC2-'+number,
|
||||
'cover': getCover(htmlcode2),
|
||||
'imagecut': 0,
|
||||
'tag': getTag(htmlcode2),
|
||||
'actor_photo':'',
|
||||
'website': 'http://adult.contents.fc2.com/article_search.php?id=' + number,
|
||||
'source': 'fc2fans_club.py',
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
|
||||
#print(main('1145465'))
|
||||
137
javbus.py
@@ -1,137 +0,0 @@
|
||||
import re
|
||||
from pyquery import PyQuery as pq#need install
|
||||
from lxml import etree#need install
|
||||
from bs4 import BeautifulSoup#need install
|
||||
import json
|
||||
from ADC_function import *
|
||||
|
||||
def getActorPhoto(htmlcode): #//*[@id="star_qdt"]/li/a/img
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find_all(attrs={'class': 'star-name'})
|
||||
d={}
|
||||
for i in a:
|
||||
l=i.a['href']
|
||||
t=i.get_text()
|
||||
html = etree.fromstring(get_html(l), etree.HTMLParser())
|
||||
p=str(html.xpath('//*[@id="waterfall"]/div[1]/div/div[1]/img/@src')).strip(" ['']")
|
||||
p2={t:p}
|
||||
d.update(p2)
|
||||
return d
|
||||
def getTitle(htmlcode): #获取标题
|
||||
doc = pq(htmlcode)
|
||||
title=str(doc('div.container h3').text()).replace(' ','-')
|
||||
try:
|
||||
title2 = re.sub('n\d+-','',title)
|
||||
return title2
|
||||
except:
|
||||
return title
|
||||
def getStudio(htmlcode): #获取厂商
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[5]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getYear(htmlcode): #获取年份
|
||||
html = etree.fromstring(htmlcode,etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getCover(htmlcode): #获取封面链接
|
||||
doc = pq(htmlcode)
|
||||
image = doc('a.bigImage')
|
||||
return image.attr('href')
|
||||
def getRelease(htmlcode): #获取出版日期
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getRuntime(htmlcode): #获取分钟
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find(text=re.compile('分鐘'))
|
||||
return a
|
||||
def getActor(htmlcode): #获取女优
|
||||
b=[]
|
||||
soup=BeautifulSoup(htmlcode,'lxml')
|
||||
a=soup.find_all(attrs={'class':'star-name'})
|
||||
for i in a:
|
||||
b.append(i.get_text())
|
||||
return b
|
||||
def getNum(htmlcode): #获取番号
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[1]/span[2]/text()')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(htmlcode): #获取导演
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[4]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getOutline(htmlcode): #获取演员
|
||||
doc = pq(htmlcode)
|
||||
result = str(doc('tr td div.mg-b20.lh4 p.mg-b20').text())
|
||||
return result
|
||||
def getSerise(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/div[5]/div[1]/div[2]/p[7]/a/text()')).strip(" ['']")
|
||||
return result
|
||||
def getTag(htmlcode): # 获取演员
|
||||
tag = []
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = soup.find_all(attrs={'class': 'genre'})
|
||||
for i in a:
|
||||
if 'onmouseout' in str(i):
|
||||
continue
|
||||
tag.append(i.get_text())
|
||||
return tag
|
||||
|
||||
|
||||
def main(number):
|
||||
try:
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
try:
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
except:
|
||||
dww_htmlcode = ''
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-', '', getTitle(htmlcode))),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': str(re.search('\d{4}', getYear(htmlcode)).group()),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 1,
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
'actor_photo': getActorPhoto(htmlcode),
|
||||
'website': 'https://www.javbus.com/' + number,
|
||||
'source' : 'javbus.py',
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js
|
||||
except:
|
||||
return main_uncensored(number)
|
||||
|
||||
def main_uncensored(number):
|
||||
htmlcode = get_html('https://www.javbus.com/' + number)
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
if getTitle(htmlcode) == '':
|
||||
htmlcode = get_html('https://www.javbus.com/' + number.replace('-','_'))
|
||||
dww_htmlcode = get_html("https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=" + number.replace("-", ''))
|
||||
dic = {
|
||||
'title': str(re.sub('\w+-\d+-','',getTitle(htmlcode))).replace(getNum(htmlcode)+'-',''),
|
||||
'studio': getStudio(htmlcode),
|
||||
'year': getYear(htmlcode),
|
||||
'outline': getOutline(dww_htmlcode),
|
||||
'runtime': getRuntime(htmlcode),
|
||||
'director': getDirector(htmlcode),
|
||||
'actor': getActor(htmlcode),
|
||||
'release': getRelease(htmlcode),
|
||||
'number': getNum(htmlcode),
|
||||
'cover': getCover(htmlcode),
|
||||
'tag': getTag(htmlcode),
|
||||
'label': getSerise(htmlcode),
|
||||
'imagecut': 0,
|
||||
'actor_photo': '',
|
||||
'website': 'https://www.javbus.com/' + number,
|
||||
'source': 'javbus.py',
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js
|
||||
139
javdb.py
@@ -1,139 +0,0 @@
|
||||
import re
|
||||
from lxml import etree
|
||||
import json
|
||||
from bs4 import BeautifulSoup
|
||||
from ADC_function import *
|
||||
|
||||
def getTitle(a):
|
||||
try:
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/section/div/h2/strong/text()')).strip(" ['']")
|
||||
return re.sub('.*\] ','',result.replace('/', ',').replace('\\xa0','').replace(' : ',''))
|
||||
except:
|
||||
return re.sub('.*\] ','',result.replace('/', ',').replace('\\xa0',''))
|
||||
def getActor(a): #//*[@id="center_column"]/div[2]/div[1]/div/table/tbody/tr[1]/td/text()
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"演員")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"演員")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').replace(",\\xa0","").replace("'","").replace(' ','').replace(',,','').lstrip(',').replace(',',', ')
|
||||
def getStudio(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"製作")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"製作")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1+result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getRuntime(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"時長")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"時長")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').rstrip('mi')
|
||||
def getLabel(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"系列")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"系列")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getNum(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result1 = str(html.xpath('//strong[contains(text(),"番號")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"番號")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+')
|
||||
def getYear(getRelease):
|
||||
try:
|
||||
result = str(re.search('\d{4}',getRelease).group())
|
||||
return result
|
||||
except:
|
||||
return getRelease
|
||||
def getRelease(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"時間")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"時間")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+')
|
||||
def getTag(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"类别")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"类别")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').replace(",\\xa0","").replace("'","").replace(' ','').replace(',,','').lstrip(',')
|
||||
def getCover(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('/html/body/section/div/div[2]/div[1]/a/img/@src')).strip(" ['']")
|
||||
if result == '':
|
||||
result = str(html.xpath('/html/body/section/div/div[3]/div[1]/a/img/@src')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//strong[contains(text(),"導演")]/../following-sibling::span/text()')).strip(" ['']")
|
||||
result2 = str(html.xpath('//strong[contains(text(),"導演")]/../following-sibling::span/a/text()')).strip(" ['']")
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getOutline(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="introduction"]/dd/p[1]/text()')).strip(" ['']")
|
||||
return result
|
||||
def main(number):
|
||||
try:
|
||||
a = get_html('https://javdb.com/search?q=' + number + '&f=all')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="videos"]/div/div/a/@href')).strip(" ['']")
|
||||
if result1 == '':
|
||||
a = get_html('https://javdb.com/search?q=' + number.replace('-', '_') + '&f=all')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="videos"]/div/div/a/@href')).strip(" ['']")
|
||||
b = get_html('https://javdb1.com' + result1)
|
||||
soup = BeautifulSoup(b, 'lxml')
|
||||
a = str(soup.find(attrs={'class': 'panel'}))
|
||||
dic = {
|
||||
'actor': getActor(a),
|
||||
'title': getTitle(b).replace("\\n", '').replace(' ', '').replace(getActor(a), '').replace(getNum(a),
|
||||
'').replace(
|
||||
'无码', '').replace('有码', '').lstrip(' '),
|
||||
'studio': getStudio(a),
|
||||
'outline': getOutline(a),
|
||||
'runtime': getRuntime(a),
|
||||
'director': getDirector(a),
|
||||
'release': getRelease(a),
|
||||
'number': getNum(a),
|
||||
'cover': getCover(b),
|
||||
'imagecut': 0,
|
||||
'tag': getTag(a),
|
||||
'label': getLabel(a),
|
||||
'year': getYear(getRelease(a)), # str(re.search('\d{4}',getRelease(a)).group()),
|
||||
'actor_photo': '',
|
||||
'website': 'https://javdb1.com' + result1,
|
||||
'source': 'javdb.py',
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js
|
||||
except:
|
||||
a = get_html('https://javdb.com/search?q=' + number + '&f=all')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="videos"]/div/div/a/@href')).strip(" ['']")
|
||||
if result1 == '' or result1 == 'null':
|
||||
a = get_html('https://javdb.com/search?q=' + number.replace('-', '_') + '&f=all')
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//*[@id="videos"]/div/div/a/@href')).strip(" ['']")
|
||||
b = get_html('https://javdb.com' + result1)
|
||||
soup = BeautifulSoup(b, 'lxml')
|
||||
a = str(soup.find(attrs={'class': 'panel'}))
|
||||
dic = {
|
||||
'actor': getActor(a),
|
||||
'title': getTitle(b).replace("\\n", '').replace(' ', '').replace(getActor(a), '').replace(
|
||||
getNum(a),
|
||||
'').replace(
|
||||
'无码', '').replace('有码', '').lstrip(' '),
|
||||
'studio': getStudio(a),
|
||||
'outline': getOutline(a),
|
||||
'runtime': getRuntime(a),
|
||||
'director': getDirector(a),
|
||||
'release': getRelease(a),
|
||||
'number': getNum(a),
|
||||
'cover': getCover(b),
|
||||
'imagecut': 0,
|
||||
'tag': getTag(a),
|
||||
'label': getLabel(a),
|
||||
'year': getYear(getRelease(a)), # str(re.search('\d{4}',getRelease(a)).group()),
|
||||
'actor_photo': '',
|
||||
'website': 'https://javdb.com' + result1,
|
||||
'source': 'javdb.py',
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4,separators=(',', ':'), ) # .encode('UTF-8')
|
||||
return js
|
||||
|
||||
#print(main('061519-861'))
|
||||
287
number_parser.py
Executable file
@@ -0,0 +1,287 @@
|
||||
import os
|
||||
import re
|
||||
import sys
|
||||
import config
|
||||
import typing
|
||||
|
||||
G_spat = re.compile(
|
||||
"^\w+\.(cc|com|net|me|club|jp|tv|xyz|biz|wiki|info|tw|us|de)@|^22-sht\.me|"
|
||||
"^(fhd|hd|sd|1080p|720p|4K)(-|_)|"
|
||||
"(-|_)(fhd|hd|sd|1080p|720p|4K|x264|x265|uncensored|hack|leak)",
|
||||
re.IGNORECASE)
|
||||
|
||||
|
||||
def get_number(debug: bool, file_path: str) -> str:
|
||||
"""
|
||||
从文件路径中提取番号 from number_parser import get_number
|
||||
>>> get_number(False, "/Users/Guest/AV_Data_Capture/snis-829.mp4")
|
||||
'snis-829'
|
||||
>>> get_number(False, "/Users/Guest/AV_Data_Capture/snis-829-C.mp4")
|
||||
'snis-829'
|
||||
>>> get_number(False, "/Users/Guest/AV_Data_Capture/[脸肿字幕组][PoRO]牝教師4~穢された教壇~ 「生意気ドジっ娘女教師・美結~高飛車ハメ堕ち2濁金」[720p][x264_aac].mp4")
|
||||
'牝教師4~穢された教壇~ 「生意気ドジっ娘女教師・美結~高飛車ハメ堕ち2濁金」'
|
||||
>>> get_number(False, "C:¥Users¥Guest¥snis-829.mp4")
|
||||
'snis-829'
|
||||
>>> get_number(False, "C:¥Users¥Guest¥snis-829-C.mp4")
|
||||
'snis-829'
|
||||
>>> get_number(False, "./snis-829.mp4")
|
||||
'snis-829'
|
||||
>>> get_number(False, "./snis-829-C.mp4")
|
||||
'snis-829'
|
||||
>>> get_number(False, ".¥snis-829.mp4")
|
||||
'snis-829'
|
||||
>>> get_number(False, ".¥snis-829-C.mp4")
|
||||
'snis-829'
|
||||
>>> get_number(False, "snis-829.mp4")
|
||||
'snis-829'
|
||||
>>> get_number(False, "snis-829-C.mp4")
|
||||
'snis-829'
|
||||
"""
|
||||
filepath = os.path.basename(file_path)
|
||||
# debug True 和 False 两块代码块合并,原因是此模块及函数只涉及字符串计算,没有IO操作,debug on时输出导致异常信息即可
|
||||
try:
|
||||
# 先对自定义正则进行匹配
|
||||
if config.getInstance().number_regexs().split().__len__() > 0:
|
||||
for regex in config.getInstance().number_regexs().split():
|
||||
try:
|
||||
if re.search(regex, filepath):
|
||||
return re.search(regex, filepath).group()
|
||||
except Exception as e:
|
||||
print(f'[-]custom regex exception: {e} [{regex}]')
|
||||
|
||||
file_number = get_number_by_dict(filepath)
|
||||
if file_number:
|
||||
return file_number
|
||||
elif '字幕组' in filepath or 'SUB' in filepath.upper() or re.match(r'[\u30a0-\u30ff]+', filepath):
|
||||
filepath = G_spat.sub("", filepath)
|
||||
filepath = re.sub("\[.*?\]","",filepath)
|
||||
filepath = filepath.replace(".chs", "").replace(".cht", "")
|
||||
file_number = str(re.findall(r'(.+?)\.', filepath)).strip(" [']")
|
||||
return file_number
|
||||
elif '-' in filepath or '_' in filepath: # 普通提取番号 主要处理包含减号-和_的番号
|
||||
filepath = G_spat.sub("", filepath)
|
||||
filename = str(re.sub("\[\d{4}-\d{1,2}-\d{1,2}\] - ", "", filepath)) # 去除文件名中时间
|
||||
lower_check = filename.lower()
|
||||
if 'fc2' in lower_check:
|
||||
filename = lower_check.replace('--', '-').replace('_', '-').upper()
|
||||
filename = re.sub("[-_]cd\d{1,2}", "", filename, flags=re.IGNORECASE)
|
||||
if not re.search("-|_", filename): # 去掉-CD1之后再无-的情况,例如n1012-CD1.wmv
|
||||
return str(re.search(r'\w+', filename[:filename.find('.')], re.A).group())
|
||||
file_number = os.path.splitext(filename)
|
||||
filename = re.search(r'[\w\-_]+', filename, re.A)
|
||||
if filename:
|
||||
file_number = str(filename.group())
|
||||
else:
|
||||
file_number = file_number[0]
|
||||
|
||||
new_file_number = file_number
|
||||
if re.search("-c", file_number, flags=re.IGNORECASE):
|
||||
new_file_number = re.sub("(-|_)c$", "", file_number, flags=re.IGNORECASE)
|
||||
elif re.search("-u$", file_number, flags=re.IGNORECASE):
|
||||
new_file_number = re.sub("(-|_)u$", "", file_number, flags=re.IGNORECASE)
|
||||
elif re.search("-uc$", file_number, flags=re.IGNORECASE):
|
||||
new_file_number = re.sub("(-|_)uc$", "", file_number, flags=re.IGNORECASE)
|
||||
elif re.search("\d+ch$", file_number, flags=re.I):
|
||||
new_file_number = file_number[:-2]
|
||||
|
||||
return new_file_number.upper()
|
||||
else: # 提取不含减号-的番号,FANZA CID
|
||||
# 欧美番号匹配规则
|
||||
oumei = re.search(r'[a-zA-Z]+\.\d{2}\.\d{2}\.\d{2}', filepath)
|
||||
if oumei:
|
||||
return oumei.group()
|
||||
try:
|
||||
return str(
|
||||
re.findall(r'(.+?)\.',
|
||||
str(re.search('([^<>/\\\\|:""\\*\\?]+)\\.\\w+$', filepath).group()))).strip(
|
||||
"['']").replace('_', '-')
|
||||
except:
|
||||
return str(re.search(r'(.+?)\.', filepath)[0])
|
||||
except Exception as e:
|
||||
if debug:
|
||||
print(f'[-]Number Parser exception: {e} [{file_path}]')
|
||||
return None
|
||||
|
||||
|
||||
|
||||
# 按javdb数据源的命名规范提取number
|
||||
G_TAKE_NUM_RULES = {
|
||||
'tokyo.*hot': lambda x: str(re.search(r'(cz|gedo|k|n|red-|se)\d{2,4}', x, re.I).group()),
|
||||
'carib': lambda x: str(re.search(r'\d{6}(-|_)\d{3}', x, re.I).group()).replace('_', '-'),
|
||||
'1pon|mura|paco': lambda x: str(re.search(r'\d{6}(-|_)\d{3}', x, re.I).group()).replace('-', '_'),
|
||||
'10mu': lambda x: str(re.search(r'\d{6}(-|_)\d{2}', x, re.I).group()).replace('-', '_'),
|
||||
'x-art': lambda x: str(re.search(r'x-art\.\d{2}\.\d{2}\.\d{2}', x, re.I).group()),
|
||||
'xxx-av': lambda x: ''.join(['xxx-av-', re.findall(r'xxx-av[^\d]*(\d{3,5})[^\d]*', x, re.I)[0]]),
|
||||
'heydouga': lambda x: 'heydouga-' + '-'.join(re.findall(r'(\d{4})[\-_](\d{3,4})[^\d]*', x, re.I)[0]),
|
||||
'heyzo': lambda x: 'HEYZO-' + re.findall(r'heyzo[^\d]*(\d{4})', x, re.I)[0],
|
||||
'mdbk': lambda x: str(re.search(r'mdbk(-|_)(\d{4})', x, re.I).group()),
|
||||
'mdtm': lambda x: str(re.search(r'mdtm(-|_)(\d{4})', x, re.I).group()),
|
||||
'caribpr': lambda x: str(re.search(r'\d{6}(-|_)\d{3}', x, re.I).group()).replace('_', '-'),
|
||||
}
|
||||
|
||||
|
||||
def get_number_by_dict(filename: str) -> typing.Optional[str]:
|
||||
try:
|
||||
for k, v in G_TAKE_NUM_RULES.items():
|
||||
if re.search(k, filename, re.I):
|
||||
return v(filename)
|
||||
except:
|
||||
pass
|
||||
return None
|
||||
|
||||
|
||||
class Cache_uncensored_conf:
|
||||
prefix = None
|
||||
|
||||
def is_empty(self):
|
||||
return bool(self.prefix is None)
|
||||
|
||||
def set(self, v: list):
|
||||
if not v or not len(v) or not len(v[0]):
|
||||
raise ValueError('input prefix list empty or None')
|
||||
s = v[0]
|
||||
if len(v) > 1:
|
||||
for i in v[1:]:
|
||||
s += f"|{i}.+"
|
||||
self.prefix = re.compile(s, re.I)
|
||||
|
||||
def check(self, number):
|
||||
if self.prefix is None:
|
||||
raise ValueError('No init re compile')
|
||||
return self.prefix.match(number)
|
||||
|
||||
|
||||
G_cache_uncensored_conf = Cache_uncensored_conf()
|
||||
|
||||
|
||||
# ========================================================================是否为无码
|
||||
def is_uncensored(number) -> bool:
|
||||
if re.match(
|
||||
r'[\d-]{4,}|\d{6}_\d{2,3}|(cz|gedo|k|n|red-|se)\d{2,4}|heyzo.+|xxx-av-.+|heydouga-.+|x-art\.\d{2}\.\d{2}\.\d{2}',
|
||||
number,
|
||||
re.I
|
||||
):
|
||||
return True
|
||||
if G_cache_uncensored_conf.is_empty():
|
||||
G_cache_uncensored_conf.set(config.getInstance().get_uncensored().split(','))
|
||||
return bool(G_cache_uncensored_conf.check(number))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# import doctest
|
||||
# doctest.testmod(raise_on_error=True)
|
||||
test_use_cases = (
|
||||
"MEYD-594-C.mp4",
|
||||
"SSIS-001_C.mp4",
|
||||
"SSIS100-C.mp4",
|
||||
"SSIS101_C.mp4",
|
||||
"ssni984.mp4",
|
||||
"ssni666.mp4",
|
||||
"SDDE-625_uncensored_C.mp4",
|
||||
"SDDE-625_uncensored_leak_C.mp4",
|
||||
"SDDE-625_uncensored_leak_C_cd1.mp4",
|
||||
"Tokyo Hot n9001 FHD.mp4", # 无-号,以前无法正确提取
|
||||
"TokyoHot-n1287-HD SP2006 .mp4",
|
||||
"caribean-020317_001.nfo", # -号误命名为_号的
|
||||
"257138_3xplanet_1Pondo_080521_001.mp4",
|
||||
"ADV-R0624-CD3.wmv", # 多碟影片
|
||||
"XXX-AV 22061-CD5.iso", # 支持片商格式 xxx-av-22061 命名规则来自javdb数据源
|
||||
"xxx-av 20589.mp4",
|
||||
"Muramura-102114_145-HD.wmv", # 支持片商格式 102114_145 命名规则来自javdb数据源
|
||||
"heydouga-4102-023-CD2.iso", # 支持片商格式 heydouga-4102-023 命名规则来自javdb数据源
|
||||
"HeyDOuGa4236-1048 Ai Qiu - .mp4", # heydouga-4236-1048 命名规则来自javdb数据源
|
||||
"pacopacomama-093021_539-FHD.mkv", # 支持片商格式 093021_539 命名规则来自javdb数据源
|
||||
"sbw99.cc@heyzo_hd_2636_full.mp4",
|
||||
"hhd800.com@STARS-566-HD.mp4",
|
||||
"jav20s8.com@GIGL-677_4K.mp4",
|
||||
"sbw99.cc@iesp-653-4K.mp4",
|
||||
"4K-ABP-358_C.mkv",
|
||||
"n1012-CD1.wmv",
|
||||
"[]n1012-CD2.wmv",
|
||||
"rctd-460ch.mp4", # 除支持-C硬字幕外,新支持ch硬字幕
|
||||
"rctd-461CH-CD2.mp4", # ch后可加CDn
|
||||
"rctd-461-Cd3-C.mp4", # CDn后可加-C
|
||||
"rctd-461-C-cD4.mp4", # cD1 Cd1 cd1 CD1 最终生成.nfo时统一为大写CD1
|
||||
"MD-123.ts",
|
||||
"MDSR-0001-ep2.ts",
|
||||
"MKY-NS-001.mp4"
|
||||
)
|
||||
|
||||
|
||||
def evprint(evstr):
|
||||
code = compile(evstr, "<string>", "eval")
|
||||
print("{1:>20} # '{0}'".format(evstr[18:-2], eval(code)))
|
||||
|
||||
|
||||
for t in test_use_cases:
|
||||
evprint(f'get_number(True, "{t}")')
|
||||
|
||||
if len(sys.argv) <= 1 or not re.search('^[A-Z]:?', sys.argv[1], re.IGNORECASE):
|
||||
sys.exit(0)
|
||||
|
||||
# 使用Everything的ES命令行工具搜集全盘视频文件名作为用例测试number数据,参数为盘符 A .. Z 或带盘符路径
|
||||
# https://www.voidtools.com/support/everything/command_line_interface/
|
||||
# ES命令行工具需要Everything文件搜索引擎处于运行状态,es.exe单个执行文件需放入PATH路径中。
|
||||
# Everything是免费软件
|
||||
# 示例:
|
||||
# python.exe .\number_parser.py ALL # 从所有磁盘搜索视频
|
||||
# python.exe .\number_parser.py D # 从D盘搜索
|
||||
# python.exe .\number_parser.py D: # 同上
|
||||
# python.exe .\number_parser.py D:\download\JAVs # 搜索D盘的\download\JAVs目录,路径必须带盘符
|
||||
# ==================
|
||||
# Linux/WSL1|2 使用mlocate(Ubuntu/Debian)或plocate(Debian sid)搜集全盘视频文件名作为测试用例number数据
|
||||
# 需安装'sudo apt install mlocate或plocate'并首次运行sudo updatedb建立全盘索引
|
||||
# MAC OS X 使用findutils的glocate,需安装'sudo brew install findutils'并首次运行sudo gupdatedb建立全盘索引
|
||||
# 示例:
|
||||
# python3 ./number_parser.py ALL
|
||||
import subprocess
|
||||
|
||||
ES_search_path = "ALL disks"
|
||||
if sys.argv[1] == "ALL":
|
||||
if sys.platform == "win32":
|
||||
# ES_prog_path = 'C:/greensoft/es/es.exe'
|
||||
ES_prog_path = 'es.exe' # es.exe需要放在PATH环境变量的路径之内
|
||||
ES_cmdline = f'{ES_prog_path} -name size:gigantic ext:mp4;avi;rmvb;wmv;mov;mkv;flv;ts;webm;iso;mpg;m4v'
|
||||
out_bytes = subprocess.check_output(ES_cmdline.split(' '))
|
||||
out_text = out_bytes.decode('gb18030') # 中文版windows 10 x64默认输出GB18030,此编码为UNICODE方言与UTF-8系全射关系无转码损失
|
||||
out_list = out_text.splitlines()
|
||||
elif sys.platform in ("linux", "darwin"):
|
||||
ES_prog_path = 'locate' if sys.platform == 'linux' else 'glocate'
|
||||
ES_cmdline = r"{} -b -i --regex '\.mp4$|\.avi$|\.rmvb$|\.wmv$|\.mov$|\.mkv$|\.webm$|\.iso$|\.mpg$|\.m4v$'".format(
|
||||
ES_prog_path)
|
||||
out_bytes = subprocess.check_output(ES_cmdline.split(' '))
|
||||
out_text = out_bytes.decode('utf-8')
|
||||
out_list = [os.path.basename(line) for line in out_text.splitlines()]
|
||||
else:
|
||||
print('[-]Unsupported platform! Please run on OS Windows/Linux/MacOSX. Exit.')
|
||||
sys.exit(1)
|
||||
else: # Windows single disk
|
||||
if sys.platform != "win32":
|
||||
print('[!]Usage: python3 ./number_parser.py ALL')
|
||||
sys.exit(0)
|
||||
# ES_prog_path = 'C:/greensoft/es/es.exe'
|
||||
ES_prog_path = 'es.exe' # es.exe需要放在PATH环境变量的路径之内
|
||||
if os.path.isdir(sys.argv[1]):
|
||||
ES_search_path = sys.argv[1]
|
||||
else:
|
||||
ES_search_path = sys.argv[1][0] + ':/'
|
||||
if not os.path.isdir(ES_search_path):
|
||||
ES_search_path = 'C:/'
|
||||
ES_search_path = os.path.normcase(ES_search_path)
|
||||
ES_cmdline = f'{ES_prog_path} -path {ES_search_path} -name size:gigantic ext:mp4;avi;rmvb;wmv;mov;mkv;webm;iso;mpg;m4v'
|
||||
out_bytes = subprocess.check_output(ES_cmdline.split(' '))
|
||||
out_text = out_bytes.decode('gb18030') # 中文版windows 10 x64默认输出GB18030,此编码为UNICODE方言与UTF-8系全射关系无转码损失
|
||||
out_list = out_text.splitlines()
|
||||
print(f'\n[!]{ES_prog_path} is searching {ES_search_path} for movies as number parser test cases...')
|
||||
print(f'[+]Find {len(out_list)} Movies.')
|
||||
for filename in out_list:
|
||||
try:
|
||||
n = get_number(True, filename)
|
||||
if n:
|
||||
print(' [{0}] {2}# {1}'.format(n, filename, '#无码' if is_uncensored(n) else ''))
|
||||
else:
|
||||
print(f'[-]Number return None. # {filename}')
|
||||
except Exception as e:
|
||||
print(f'[-]Number Parser exception: {e} [{filename}]')
|
||||
|
||||
sys.exit(0)
|
||||
26
py_to_exe.ps1
Normal file
@@ -0,0 +1,26 @@
|
||||
# If you can't run this script, please execute the following command in PowerShell.
|
||||
# Set-ExecutionPolicy RemoteSigned -Scope CurrentUser -Force
|
||||
|
||||
$CLOUDSCRAPER_PATH = $( python -c 'import cloudscraper as _; print(_.__path__[0])' | select -Last 1 )
|
||||
$OPENCC_PATH = $( python -c 'import opencc as _; print(_.__path__[0])' | select -Last 1 )
|
||||
$FACE_RECOGNITION_MODELS = $( python -c 'import face_recognition_models as _; print(_.__path__[0])' | select -Last 1 )
|
||||
|
||||
mkdir build
|
||||
mkdir __pycache__
|
||||
|
||||
pyinstaller --onefile Movie_Data_Capture.py `
|
||||
--hidden-import "ImageProcessing.cnn" `
|
||||
--python-option u `
|
||||
--add-data "$FACE_RECOGNITION_MODELS;face_recognition_models" `
|
||||
--add-data "$CLOUDSCRAPER_PATH;cloudscraper" `
|
||||
--add-data "$OPENCC_PATH;opencc" `
|
||||
--add-data "Img;Img" `
|
||||
--add-data "config.ini;." `
|
||||
--add-data "scrapinglib;scrapinglib" `
|
||||
|
||||
rmdir -Recurse -Force build
|
||||
rmdir -Recurse -Force __pycache__
|
||||
rmdir -Recurse -Force Movie_Data_Capture.spec
|
||||
|
||||
echo "[Make]Finish"
|
||||
pause
|
||||
{kind=link}
|
Before Width: | Height: | Size: 457 KiB |
14
requirements.txt
Normal file
@@ -0,0 +1,14 @@
|
||||
requests
|
||||
dlib-bin
|
||||
Click
|
||||
numpy
|
||||
face-recognition-models
|
||||
lxml
|
||||
beautifulsoup4
|
||||
pillow==10.0.1
|
||||
cloudscraper
|
||||
pysocks==1.7.1
|
||||
urllib3==1.26.18
|
||||
certifi
|
||||
MechanicalSoup
|
||||
opencc-python-reimplemented
|
||||
322
scraper.py
Normal file
@@ -0,0 +1,322 @@
|
||||
# build-in lib
|
||||
import json
|
||||
import secrets
|
||||
import typing
|
||||
from pathlib import Path
|
||||
|
||||
# third party lib
|
||||
import opencc
|
||||
from lxml import etree
|
||||
# project wide definitions
|
||||
import config
|
||||
from ADC_function import (translate,
|
||||
load_cookies,
|
||||
file_modification_days,
|
||||
delete_all_elements_in_str,
|
||||
delete_all_elements_in_list
|
||||
)
|
||||
from scrapinglib.api import search
|
||||
|
||||
|
||||
def get_data_from_json(
|
||||
file_number: str,
|
||||
open_cc: opencc.OpenCC,
|
||||
specified_source: str, specified_url: str) -> typing.Optional[dict]:
|
||||
"""
|
||||
iterate through all services and fetch the data 从网站上查询片名解析JSON返回元数据
|
||||
:param file_number: 影片名称
|
||||
:param open_cc: 简繁转换器
|
||||
:param specified_source: 指定的媒体数据源
|
||||
:param specified_url: 指定的数据查询地址, 目前未使用
|
||||
:return 给定影片名称的具体信息
|
||||
"""
|
||||
try:
|
||||
actor_mapping_data = etree.parse(str(Path.home() / '.local' / 'share' / 'mdc' / 'mapping_actor.xml'))
|
||||
info_mapping_data = etree.parse(str(Path.home() / '.local' / 'share' / 'mdc' / 'mapping_info.xml'))
|
||||
except:
|
||||
actor_mapping_data = etree.fromstring("<html></html>", etree.HTMLParser())
|
||||
info_mapping_data = etree.fromstring("<html></html>", etree.HTMLParser())
|
||||
|
||||
conf = config.getInstance()
|
||||
# default fetch order list, from the beginning to the end
|
||||
sources = conf.sources()
|
||||
|
||||
# TODO 准备参数
|
||||
# - 清理 ADC_function, webcrawler
|
||||
proxies: dict = None
|
||||
config_proxy = conf.proxy()
|
||||
if config_proxy.enable:
|
||||
proxies = config_proxy.proxies()
|
||||
|
||||
# javdb website logic
|
||||
# javdb have suffix
|
||||
javdb_sites = conf.javdb_sites().split(',')
|
||||
for i in javdb_sites:
|
||||
javdb_sites[javdb_sites.index(i)] = "javdb" + i
|
||||
javdb_sites.append("javdb")
|
||||
# 不加载过期的cookie,javdb登录界面显示为7天免登录,故假定cookie有效期为7天
|
||||
has_valid_cookie = False
|
||||
for cj in javdb_sites:
|
||||
javdb_site = cj
|
||||
cookie_json = javdb_site + '.json'
|
||||
cookies_dict, cookies_filepath = load_cookies(cookie_json)
|
||||
if isinstance(cookies_dict, dict) and isinstance(cookies_filepath, str):
|
||||
cdays = file_modification_days(cookies_filepath)
|
||||
if cdays < 7:
|
||||
javdb_cookies = cookies_dict
|
||||
has_valid_cookie = True
|
||||
break
|
||||
elif cdays != 9999:
|
||||
print(
|
||||
f'[!]Cookies file {cookies_filepath} was updated {cdays} days ago, it will not be used for HTTP requests.')
|
||||
if not has_valid_cookie:
|
||||
# get real random site from javdb_sites, because random is not really random when the seed value is known
|
||||
javdb_site = secrets.choice(javdb_sites)
|
||||
javdb_cookies = None
|
||||
|
||||
ca_cert = None
|
||||
if conf.cacert_file():
|
||||
ca_cert = conf.cacert_file()
|
||||
|
||||
json_data = search(file_number, sources, proxies=proxies, verify=ca_cert,
|
||||
dbsite=javdb_site, dbcookies=javdb_cookies,
|
||||
morestoryline=conf.is_storyline(),
|
||||
specifiedSource=specified_source, specifiedUrl=specified_url,
|
||||
debug = conf.debug())
|
||||
# Return if data not found in all sources
|
||||
if not json_data:
|
||||
print('[-]Movie Number not found!')
|
||||
return None
|
||||
|
||||
# 增加number严格判断,避免提交任何number,总是返回"本橋実来 ADZ335",这种返回number不一致的数据源故障
|
||||
# 目前选用number命名规则是javdb.com Domain Creation Date: 2013-06-19T18:34:27Z
|
||||
# 然而也可以跟进关注其它命名规则例如airav.wiki Domain Creation Date: 2019-08-28T07:18:42.0Z
|
||||
# 如果将来javdb.com命名规则下不同Studio出现同名碰撞导致无法区分,可考虑更换规则,更新相应的number分析和抓取代码。
|
||||
if str(json_data.get('number')).upper() != file_number.upper():
|
||||
try:
|
||||
if json_data.get('allow_number_change'):
|
||||
pass
|
||||
except:
|
||||
print('[-]Movie number has changed! [{}]->[{}]'.format(file_number, str(json_data.get('number'))))
|
||||
return None
|
||||
|
||||
# ================================================网站规则添加结束================================================
|
||||
|
||||
if json_data.get('title') == '':
|
||||
print('[-]Movie Number or Title not found!')
|
||||
return None
|
||||
|
||||
title = json_data.get('title')
|
||||
actor_list = str(json_data.get('actor')).strip("[ ]").replace("'", '').split(',') # 字符串转列表
|
||||
actor_list = [actor.strip() for actor in actor_list] # 去除空白
|
||||
director = json_data.get('director')
|
||||
release = json_data.get('release')
|
||||
number = json_data.get('number')
|
||||
studio = json_data.get('studio')
|
||||
source = json_data.get('source')
|
||||
runtime = json_data.get('runtime')
|
||||
outline = json_data.get('outline')
|
||||
label = json_data.get('label')
|
||||
series = json_data.get('series')
|
||||
year = json_data.get('year')
|
||||
|
||||
if json_data.get('cover_small'):
|
||||
cover_small = json_data.get('cover_small')
|
||||
else:
|
||||
cover_small = ''
|
||||
|
||||
if json_data.get('trailer'):
|
||||
trailer = json_data.get('trailer')
|
||||
else:
|
||||
trailer = ''
|
||||
|
||||
if json_data.get('extrafanart'):
|
||||
extrafanart = json_data.get('extrafanart')
|
||||
else:
|
||||
extrafanart = ''
|
||||
|
||||
imagecut = json_data.get('imagecut')
|
||||
tag = str(json_data.get('tag')).strip("[ ]").replace("'", '').replace(" ", '').split(',') # 字符串转列表 @
|
||||
while 'XXXX' in tag:
|
||||
tag.remove('XXXX')
|
||||
while 'xxx' in tag:
|
||||
tag.remove('xxx')
|
||||
if json_data['source'] =='pissplay': # pissplay actor为英文名,不用去除空格
|
||||
actor = str(actor_list).strip("[ ]").replace("'", '')
|
||||
else:
|
||||
actor = str(actor_list).strip("[ ]").replace("'", '').replace(" ", '')
|
||||
|
||||
# if imagecut == '3':
|
||||
# DownloadFileWithFilename()
|
||||
|
||||
# ====================处理异常字符====================== #\/:*?"<>|
|
||||
actor = special_characters_replacement(actor)
|
||||
actor_list = [special_characters_replacement(a) for a in actor_list]
|
||||
title = special_characters_replacement(title)
|
||||
label = special_characters_replacement(label)
|
||||
outline = special_characters_replacement(outline)
|
||||
series = special_characters_replacement(series)
|
||||
studio = special_characters_replacement(studio)
|
||||
director = special_characters_replacement(director)
|
||||
tag = [special_characters_replacement(t) for t in tag]
|
||||
release = release.replace('/', '-')
|
||||
tmpArr = cover_small.split(',')
|
||||
if len(tmpArr) > 0:
|
||||
cover_small = tmpArr[0].strip('\"').strip('\'')
|
||||
# ====================处理异常字符 END================== #\/:*?"<>|
|
||||
|
||||
# 处理大写
|
||||
if conf.number_uppercase():
|
||||
json_data['number'] = number.upper()
|
||||
|
||||
# 返回处理后的json_data
|
||||
json_data['title'] = title
|
||||
json_data['original_title'] = title
|
||||
json_data['actor'] = actor
|
||||
json_data['release'] = release
|
||||
json_data['cover_small'] = cover_small
|
||||
json_data['tag'] = tag
|
||||
json_data['year'] = year
|
||||
json_data['actor_list'] = actor_list
|
||||
json_data['trailer'] = trailer
|
||||
json_data['extrafanart'] = extrafanart
|
||||
json_data['label'] = label
|
||||
json_data['outline'] = outline
|
||||
json_data['series'] = series
|
||||
json_data['studio'] = studio
|
||||
json_data['director'] = director
|
||||
|
||||
if conf.is_translate():
|
||||
translate_values = conf.translate_values().split(",")
|
||||
for translate_value in translate_values:
|
||||
if json_data[translate_value] == "":
|
||||
continue
|
||||
if translate_value == "title":
|
||||
title_dict = json.loads(
|
||||
(Path.home() / '.local' / 'share' / 'mdc' / 'c_number.json').read_text(encoding="utf-8"))
|
||||
try:
|
||||
json_data[translate_value] = title_dict[number]
|
||||
continue
|
||||
except:
|
||||
pass
|
||||
if conf.get_translate_engine() == "azure":
|
||||
t = translate(
|
||||
json_data[translate_value],
|
||||
target_language="zh-Hans",
|
||||
engine=conf.get_translate_engine(),
|
||||
key=conf.get_translate_key(),
|
||||
)
|
||||
else:
|
||||
if len(json_data[translate_value]):
|
||||
if type(json_data[translate_value]) == str:
|
||||
json_data[translate_value] = special_characters_replacement(json_data[translate_value])
|
||||
json_data[translate_value] = translate(json_data[translate_value])
|
||||
else:
|
||||
for i in range(len(json_data[translate_value])):
|
||||
json_data[translate_value][i] = special_characters_replacement(
|
||||
json_data[translate_value][i])
|
||||
list_in_str = ",".join(json_data[translate_value])
|
||||
json_data[translate_value] = translate(list_in_str).split(',')
|
||||
|
||||
if open_cc:
|
||||
cc_vars = conf.cc_convert_vars().split(",")
|
||||
ccm = conf.cc_convert_mode()
|
||||
|
||||
def convert_list(mapping_data, language, vars):
|
||||
total = []
|
||||
for i in vars:
|
||||
if len(mapping_data.xpath('a[contains(@keyword, $name)]/@' + language, name=f",{i},")) != 0:
|
||||
i = mapping_data.xpath('a[contains(@keyword, $name)]/@' + language, name=f",{i},")[0]
|
||||
total.append(i)
|
||||
return total
|
||||
|
||||
def convert(mapping_data, language, vars):
|
||||
if len(mapping_data.xpath('a[contains(@keyword, $name)]/@' + language, name=vars)) != 0:
|
||||
return mapping_data.xpath('a[contains(@keyword, $name)]/@' + language, name=vars)[0]
|
||||
else:
|
||||
raise IndexError('keyword not found')
|
||||
|
||||
for cc in cc_vars:
|
||||
if json_data[cc] == "" or len(json_data[cc]) == 0:
|
||||
continue
|
||||
if cc == "actor":
|
||||
try:
|
||||
if ccm == 1:
|
||||
json_data['actor_list'] = convert_list(actor_mapping_data, "zh_cn", json_data['actor_list'])
|
||||
json_data['actor'] = convert(actor_mapping_data, "zh_cn", json_data['actor'])
|
||||
elif ccm == 2:
|
||||
json_data['actor_list'] = convert_list(actor_mapping_data, "zh_tw", json_data['actor_list'])
|
||||
json_data['actor'] = convert(actor_mapping_data, "zh_tw", json_data['actor'])
|
||||
elif ccm == 3:
|
||||
json_data['actor_list'] = convert_list(actor_mapping_data, "jp", json_data['actor_list'])
|
||||
json_data['actor'] = convert(actor_mapping_data, "jp", json_data['actor'])
|
||||
except:
|
||||
json_data['actor_list'] = [open_cc.convert(aa) for aa in json_data['actor_list']]
|
||||
json_data['actor'] = open_cc.convert(json_data['actor'])
|
||||
elif cc == "tag":
|
||||
try:
|
||||
if ccm == 1:
|
||||
json_data[cc] = convert_list(info_mapping_data, "zh_cn", json_data[cc])
|
||||
json_data[cc] = delete_all_elements_in_list("删除", json_data[cc])
|
||||
elif ccm == 2:
|
||||
json_data[cc] = convert_list(info_mapping_data, "zh_tw", json_data[cc])
|
||||
json_data[cc] = delete_all_elements_in_list("删除", json_data[cc])
|
||||
elif ccm == 3:
|
||||
json_data[cc] = convert_list(info_mapping_data, "jp", json_data[cc])
|
||||
json_data[cc] = delete_all_elements_in_list("删除", json_data[cc])
|
||||
except:
|
||||
json_data[cc] = [open_cc.convert(t) for t in json_data[cc]]
|
||||
else:
|
||||
try:
|
||||
if ccm == 1:
|
||||
json_data[cc] = convert(info_mapping_data, "zh_cn", json_data[cc])
|
||||
json_data[cc] = delete_all_elements_in_str("删除", json_data[cc])
|
||||
elif ccm == 2:
|
||||
json_data[cc] = convert(info_mapping_data, "zh_tw", json_data[cc])
|
||||
json_data[cc] = delete_all_elements_in_str("删除", json_data[cc])
|
||||
elif ccm == 3:
|
||||
json_data[cc] = convert(info_mapping_data, "jp", json_data[cc])
|
||||
json_data[cc] = delete_all_elements_in_str("删除", json_data[cc])
|
||||
except IndexError:
|
||||
json_data[cc] = open_cc.convert(json_data[cc])
|
||||
except:
|
||||
pass
|
||||
|
||||
naming_rule = ""
|
||||
original_naming_rule = ""
|
||||
for i in conf.naming_rule().split("+"):
|
||||
if i not in json_data:
|
||||
naming_rule += i.strip("'").strip('"')
|
||||
original_naming_rule += i.strip("'").strip('"')
|
||||
else:
|
||||
item = json_data.get(i)
|
||||
naming_rule += item if type(item) is not list else "&".join(item)
|
||||
# PATCH:处理[title]存在翻译的情况,后续NFO文件的original_name只会直接沿用naming_rule,这导致original_name非原始名
|
||||
# 理应在翻译处处理 naming_rule和original_naming_rule
|
||||
if i == 'title':
|
||||
item = json_data.get('original_title')
|
||||
original_naming_rule += item if type(item) is not list else "&".join(item)
|
||||
|
||||
json_data['naming_rule'] = naming_rule
|
||||
json_data['original_naming_rule'] = original_naming_rule
|
||||
return json_data
|
||||
|
||||
|
||||
def special_characters_replacement(text) -> str:
|
||||
if not isinstance(text, str):
|
||||
return text
|
||||
return (text.replace('\\', '∖'). # U+2216 SET MINUS @ Basic Multilingual Plane
|
||||
replace('/', '∕'). # U+2215 DIVISION SLASH @ Basic Multilingual Plane
|
||||
replace(':', '꞉'). # U+A789 MODIFIER LETTER COLON @ Latin Extended-D
|
||||
replace('*', '∗'). # U+2217 ASTERISK OPERATOR @ Basic Multilingual Plane
|
||||
replace('?', '?'). # U+FF1F FULLWIDTH QUESTION MARK @ Basic Multilingual Plane
|
||||
replace('"', '"'). # U+FF02 FULLWIDTH QUOTATION MARK @ Basic Multilingual Plane
|
||||
replace('<', 'ᐸ'). # U+1438 CANADIAN SYLLABICS PA @ Basic Multilingual Plane
|
||||
replace('>', 'ᐳ'). # U+1433 CANADIAN SYLLABICS PO @ Basic Multilingual Plane
|
||||
replace('|', 'ǀ'). # U+01C0 LATIN LETTER DENTAL CLICK @ Basic Multilingual Plane
|
||||
replace('‘', '‘'). # U+02018 LEFT SINGLE QUOTATION MARK
|
||||
replace('’', '’'). # U+02019 RIGHT SINGLE QUOTATION MARK
|
||||
replace('…', '…').
|
||||
replace('&', '&').
|
||||
replace("&", '&')
|
||||
)
|
||||
2
scrapinglib/__init__.py
Normal file
@@ -0,0 +1,2 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
from .api import search, getSupportedSources
|
||||
171
scrapinglib/airav.py
Normal file
@@ -0,0 +1,171 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import json
|
||||
import re
|
||||
from .parser import Parser
|
||||
from .javbus import Javbus
|
||||
|
||||
class Airav(Parser):
|
||||
source = 'airav'
|
||||
|
||||
expr_title = '/html/head/title/text()'
|
||||
expr_number = '/html/head/title/text()'
|
||||
expr_studio = '//a[contains(@href,"?video_factory=")]/text()'
|
||||
expr_release = '//li[contains(text(),"發片日期")]/text()'
|
||||
expr_outline = "string(//div[@class='d-flex videoDataBlock']/div[@class='synopsis']/p)"
|
||||
expr_actor = '//ul[@class="videoAvstarList"]/li/a[starts-with(@href,"/idol/")]/text()'
|
||||
expr_cover = '//img[contains(@src,"/storage/big_pic/")]/@src'
|
||||
expr_tags = '//div[@class="tagBtnMargin"]/a/text()'
|
||||
expr_extrafanart = '//div[@class="mobileImgThumbnail"]/a/@href'
|
||||
|
||||
def extraInit(self):
|
||||
# for javbus
|
||||
self.specifiedSource = None
|
||||
self.addtion_Javbus = True
|
||||
|
||||
def search(self, number):
|
||||
self.number = number
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = "https://www.airav.wiki/api/video/barcode/" + self.number.upper() + "?lng=zh-CN"
|
||||
if self.addtion_Javbus:
|
||||
engine = Javbus()
|
||||
javbusinfo = engine.scrape(self.number, self)
|
||||
if javbusinfo == 404:
|
||||
self.javbus = {"title": ""}
|
||||
else:
|
||||
self.javbus = json.loads(javbusinfo)
|
||||
self.htmlcode = self.getHtml(self.detailurl)
|
||||
# htmltree = etree.fromstring(self.htmlcode, etree.HTMLParser())
|
||||
#result = self.dictformat(htmltree)
|
||||
htmltree = json.loads(self.htmlcode)["result"]
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
# def queryNumberUrl(self, number):
|
||||
# queryUrl = "https://cn.airav.wiki/?search=" + number
|
||||
# queryTree = self.getHtmlTree(queryUrl)
|
||||
# results = self.getTreeAll(queryTree, '//div[contains(@class,"videoList")]/div/a')
|
||||
# for i in results:
|
||||
# num = self.getTreeElement(i, '//div/div[contains(@class,"videoNumber")]/p[1]/text()')
|
||||
# if num.replace('-','') == number.replace('-','').upper():
|
||||
# self.number = num
|
||||
# return "https://cn.airav.wiki" + i.attrib['href']
|
||||
# return 'https://cn.airav.wiki/video/' + number
|
||||
|
||||
def getNum(self, htmltree):
|
||||
# if self.addtion_Javbus:
|
||||
# result = self.javbus.get('number')
|
||||
# if isinstance(result, str) and len(result):
|
||||
# return result
|
||||
# number = super().getNum(htmltree)
|
||||
# result = str(re.findall('^\[(.*?)]', number)[0])
|
||||
result = htmltree["barcode"]
|
||||
return result
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
# title = super().getTitle(htmltree)
|
||||
# result = str(re.findall('](.*?)- AIRAV-WIKI', title)[0]).strip()
|
||||
result = htmltree["name"]
|
||||
return result
|
||||
|
||||
def getStudio(self, htmltree):
|
||||
if self.addtion_Javbus:
|
||||
result = self.javbus.get('studio')
|
||||
if isinstance(result, str) and len(result):
|
||||
return result
|
||||
return super().getStudio(htmltree)
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
if self.addtion_Javbus:
|
||||
result = self.javbus.get('release')
|
||||
if isinstance(result, str) and len(result):
|
||||
return result
|
||||
try:
|
||||
return re.search(r'\d{4}-\d{2}-\d{2}', str(super().getRelease(htmltree))).group()
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getYear(self, htmltree):
|
||||
if self.addtion_Javbus:
|
||||
result = self.javbus.get('year')
|
||||
if isinstance(result, str) and len(result):
|
||||
return result
|
||||
release = self.getRelease(htmltree)
|
||||
return str(re.findall('\d{4}', release)).strip(" ['']")
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
|
||||
# return self.getTreeAll(htmltree, self.expr_outline).replace('\n','').strip()
|
||||
try:
|
||||
result = htmltree["description"]
|
||||
except:
|
||||
result = ""
|
||||
return result
|
||||
|
||||
def getRuntime(self, htmltree):
|
||||
if self.addtion_Javbus:
|
||||
result = self.javbus.get('runtime')
|
||||
if isinstance(result, str) and len(result):
|
||||
return result
|
||||
return ''
|
||||
|
||||
def getDirector(self, htmltree):
|
||||
if self.addtion_Javbus:
|
||||
result = self.javbus.get('director')
|
||||
if isinstance(result, str) and len(result):
|
||||
return result
|
||||
return ''
|
||||
|
||||
def getActors(self, htmltree):
|
||||
# a = super().getActors(htmltree)
|
||||
# b = [ i.strip() for i in a if len(i)]
|
||||
# if len(b):
|
||||
# return b
|
||||
# if self.addtion_Javbus:
|
||||
# result = self.javbus.get('actor')
|
||||
# if isinstance(result, list) and len(result):
|
||||
# return result
|
||||
# return []
|
||||
a = htmltree["actors"]
|
||||
if a:
|
||||
b = []
|
||||
for i in a:
|
||||
b.append(i["name"])
|
||||
else:
|
||||
b = []
|
||||
return b
|
||||
|
||||
def getCover(self, htmltree):
|
||||
if self.addtion_Javbus:
|
||||
result = self.javbus.get('cover')
|
||||
if isinstance(result, str) and len(result):
|
||||
return result
|
||||
result = htmltree['img_url']
|
||||
if isinstance(result, str) and len(result):
|
||||
return result
|
||||
return super().getCover(htmltree)
|
||||
|
||||
def getSeries(self, htmltree):
|
||||
if self.addtion_Javbus:
|
||||
result = self.javbus.get('series')
|
||||
if isinstance(result, str) and len(result):
|
||||
return result
|
||||
return ''
|
||||
def getExtrafanart(self,htmltree):
|
||||
try:
|
||||
result = htmltree["images"]
|
||||
except:
|
||||
result = ""
|
||||
return result
|
||||
|
||||
def getTags(self, htmltree):
|
||||
try:
|
||||
tag = htmltree["tags"]
|
||||
tags = []
|
||||
for i in tag:
|
||||
tags.append(i["name"])
|
||||
except:
|
||||
tags = []
|
||||
return tags
|
||||
259
scrapinglib/api.py
Normal file
@@ -0,0 +1,259 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
import json
|
||||
from .parser import Parser
|
||||
import config
|
||||
import importlib
|
||||
|
||||
|
||||
def search(number, sources: str = None, **kwargs):
|
||||
""" 根据`番号/电影`名搜索信息
|
||||
|
||||
:param number: number/name depends on type
|
||||
:param sources: sources string with `,` Eg: `avsox,javbus`
|
||||
:param type: `adult`, `general`
|
||||
"""
|
||||
sc = Scraping()
|
||||
return sc.search(number, sources, **kwargs)
|
||||
|
||||
|
||||
def getSupportedSources(tag='adult'):
|
||||
"""
|
||||
:param tag: `adult`, `general`
|
||||
"""
|
||||
sc = Scraping()
|
||||
if tag == 'adult':
|
||||
return ','.join(sc.adult_full_sources)
|
||||
else:
|
||||
return ','.join(sc.general_full_sources)
|
||||
|
||||
|
||||
class Scraping:
|
||||
"""
|
||||
"""
|
||||
adult_full_sources = ['javlibrary', 'javdb', 'javbus', 'airav', 'fanza', 'xcity', 'jav321',
|
||||
'mgstage', 'fc2', 'avsox', 'dlsite', 'carib', 'madou', 'msin',
|
||||
'getchu', 'gcolle', 'javday', 'pissplay', 'javmenu', 'pcolle', 'caribpr'
|
||||
]
|
||||
|
||||
general_full_sources = ['tmdb', 'imdb']
|
||||
|
||||
debug = False
|
||||
|
||||
proxies = None
|
||||
verify = None
|
||||
specifiedSource = None
|
||||
specifiedUrl = None
|
||||
|
||||
dbcookies = None
|
||||
dbsite = None
|
||||
# 使用storyline方法进一步获取故事情节
|
||||
morestoryline = False
|
||||
|
||||
def search(self, number, sources=None, proxies=None, verify=None, type='adult',
|
||||
specifiedSource=None, specifiedUrl=None,
|
||||
dbcookies=None, dbsite=None, morestoryline=False,
|
||||
debug=False):
|
||||
self.debug = debug
|
||||
self.proxies = proxies
|
||||
self.verify = verify
|
||||
self.specifiedSource = specifiedSource
|
||||
self.specifiedUrl = specifiedUrl
|
||||
self.dbcookies = dbcookies
|
||||
self.dbsite = dbsite
|
||||
self.morestoryline = morestoryline
|
||||
if type == 'adult':
|
||||
return self.searchAdult(number, sources)
|
||||
else:
|
||||
return self.searchGeneral(number, sources)
|
||||
|
||||
def searchGeneral(self, name, sources):
|
||||
""" 查询电影电视剧
|
||||
imdb,tmdb
|
||||
"""
|
||||
if self.specifiedSource:
|
||||
sources = [self.specifiedSource]
|
||||
else:
|
||||
sources = self.checkGeneralSources(sources, name)
|
||||
json_data = {}
|
||||
for source in sources:
|
||||
try:
|
||||
if self.debug:
|
||||
print('[+]select', source)
|
||||
try:
|
||||
module = importlib.import_module('.' + source, 'scrapinglib')
|
||||
parser_type = getattr(module, source.capitalize())
|
||||
parser: Parser = parser_type()
|
||||
data = parser.scrape(name, self)
|
||||
if data == 404:
|
||||
continue
|
||||
json_data = json.loads(data)
|
||||
except Exception as e:
|
||||
if config.getInstance().debug():
|
||||
print(e)
|
||||
# if any service return a valid return, break
|
||||
if self.get_data_state(json_data):
|
||||
if self.debug:
|
||||
print(f"[+]Find movie [{name}] metadata on website '{source}'")
|
||||
break
|
||||
except:
|
||||
continue
|
||||
|
||||
# Return if data not found in all sources
|
||||
if not json_data or json_data['title'] == "":
|
||||
return None
|
||||
|
||||
# If actor is anonymous, Fill in Anonymous
|
||||
if len(json_data['actor']) == 0:
|
||||
if config.getInstance().anonymous_fill() == True:
|
||||
if "zh_" in config.getInstance().get_target_language() or "ZH" in config.getInstance().get_target_language():
|
||||
json_data['actor'] = "佚名"
|
||||
else:
|
||||
json_data['actor'] = "Anonymous"
|
||||
|
||||
return json_data
|
||||
|
||||
def searchAdult(self, number, sources):
|
||||
if self.specifiedSource:
|
||||
sources = [self.specifiedSource]
|
||||
elif type(sources) is list:
|
||||
pass
|
||||
else:
|
||||
sources = self.checkAdultSources(sources, number)
|
||||
json_data = {}
|
||||
for source in sources:
|
||||
try:
|
||||
if self.debug:
|
||||
print('[+]select', source)
|
||||
try:
|
||||
module = importlib.import_module('.' + source, 'scrapinglib')
|
||||
parser_type = getattr(module, source.capitalize())
|
||||
parser: Parser = parser_type()
|
||||
data = parser.scrape(number, self)
|
||||
if data == 404:
|
||||
continue
|
||||
json_data = json.loads(data)
|
||||
except Exception as e:
|
||||
if config.getInstance().debug():
|
||||
print(e)
|
||||
# json_data = self.func_mapping[source](number, self)
|
||||
# if any service return a valid return, break
|
||||
if self.get_data_state(json_data):
|
||||
if self.debug:
|
||||
print(f"[+]Find movie [{number}] metadata on website '{source}'")
|
||||
break
|
||||
except:
|
||||
continue
|
||||
|
||||
# javdb的封面有水印,如果可以用其他源的封面来替换javdb的封面
|
||||
if 'source' in json_data and json_data['source'] == 'javdb':
|
||||
# search other sources
|
||||
# If cover not found in other source, then skip using other sources using javdb cover instead
|
||||
try:
|
||||
other_sources = sources[sources.index('javdb') + 1:]
|
||||
other_json_data = self.searchAdult(number, other_sources)
|
||||
if other_json_data is not None and 'cover' in other_json_data and other_json_data['cover'] != '':
|
||||
json_data['cover'] = other_json_data['cover']
|
||||
if self.debug:
|
||||
print(f"[+]Find movie [{number}] cover on website '{other_json_data['cover']}'")
|
||||
except:
|
||||
pass
|
||||
|
||||
# Return if data not found in all sources
|
||||
if not json_data or json_data['title'] == "":
|
||||
return None
|
||||
|
||||
# If actor is anonymous, Fill in Anonymous
|
||||
if len(json_data['actor']) == 0:
|
||||
if config.getInstance().anonymous_fill() == True:
|
||||
if "zh_" in config.getInstance().get_target_language() or "ZH" in config.getInstance().get_target_language():
|
||||
json_data['actor'] = "佚名"
|
||||
else:
|
||||
json_data['actor'] = "Anonymous"
|
||||
|
||||
return json_data
|
||||
|
||||
def checkGeneralSources(self, c_sources, name):
|
||||
if not c_sources:
|
||||
sources = self.general_full_sources
|
||||
else:
|
||||
sources = c_sources.split(',')
|
||||
|
||||
# check sources in func_mapping
|
||||
todel = []
|
||||
for s in sources:
|
||||
if not s in self.general_full_sources:
|
||||
print('[!] Source Not Exist : ' + s)
|
||||
todel.append(s)
|
||||
for d in todel:
|
||||
print('[!] Remove Source : ' + s)
|
||||
sources.remove(d)
|
||||
return sources
|
||||
|
||||
def checkAdultSources(self, c_sources, file_number):
|
||||
if not c_sources:
|
||||
sources = self.adult_full_sources
|
||||
else:
|
||||
sources = c_sources.split(',')
|
||||
|
||||
def insert(sources, source):
|
||||
if source in sources:
|
||||
sources.insert(0, sources.pop(sources.index(source)))
|
||||
return sources
|
||||
|
||||
if len(sources) <= len(self.adult_full_sources):
|
||||
# if the input file name matches certain rules,
|
||||
# move some web service to the beginning of the list
|
||||
lo_file_number = file_number.lower()
|
||||
if "carib" in sources:
|
||||
sources = insert(sources, "caribpr")
|
||||
sources = insert(sources, "carib")
|
||||
elif "item" in file_number or "GETCHU" in file_number.upper():
|
||||
sources = ["getchu"]
|
||||
elif "rj" in lo_file_number or "vj" in lo_file_number:
|
||||
sources = ["dlsite"]
|
||||
elif re.search(r"[\u3040-\u309F\u30A0-\u30FF]+", file_number):
|
||||
sources = ["dlsite", "getchu"]
|
||||
elif "pcolle" in sources and "pcolle" in lo_file_number:
|
||||
sources = ["pcolle"]
|
||||
elif "fc2" in lo_file_number:
|
||||
sources = ["fc2", "avsox", "msin"]
|
||||
elif (re.search(r"\d+\D+-", file_number) or "siro" in lo_file_number):
|
||||
if "mgstage" in sources:
|
||||
sources = insert(sources, "mgstage")
|
||||
elif "gcolle" in sources and (re.search("\d{6}", file_number)):
|
||||
sources = insert(sources, "gcolle")
|
||||
elif re.search(r"^\d{5,}", file_number) or \
|
||||
(re.search(r"^\d{6}-\d{3}", file_number)) or "heyzo" in lo_file_number:
|
||||
sources = ["avsox", "carib", "caribpr", "javbus", "xcity", "javdb"]
|
||||
elif re.search(r"^[a-z0-9]{3,}$", lo_file_number):
|
||||
if "xcity" in sources:
|
||||
sources = insert(sources, "xcity")
|
||||
if "madou" in sources:
|
||||
sources = insert(sources, "madou")
|
||||
|
||||
# check sources in func_mapping
|
||||
todel = []
|
||||
for s in sources:
|
||||
if not s in self.adult_full_sources and config.getInstance().debug():
|
||||
print('[!] Source Not Exist : ' + s)
|
||||
todel.append(s)
|
||||
for d in todel:
|
||||
if config.getInstance().debug():
|
||||
print('[!] Remove Source : ' + d)
|
||||
sources.remove(d)
|
||||
return sources
|
||||
|
||||
def get_data_state(self, data: dict) -> bool: # 元数据获取失败检测
|
||||
if "title" not in data or "number" not in data:
|
||||
return False
|
||||
if data["title"] is None or data["title"] == "" or data["title"] == "null":
|
||||
return False
|
||||
if data["number"] is None or data["number"] == "" or data["number"] == "null":
|
||||
return False
|
||||
if (data["cover"] is None or data["cover"] == "" or data["cover"] == "null") \
|
||||
and (data["cover_small"] is None or data["cover_small"] == "" or
|
||||
data["cover_small"] == "null"):
|
||||
return False
|
||||
return True
|
||||
94
scrapinglib/avsox.py
Normal file
@@ -0,0 +1,94 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Avsox(Parser):
|
||||
source = 'avsox'
|
||||
|
||||
expr_number = '//span[contains(text(),"识别码:")]/../span[2]/text()'
|
||||
expr_actor = '//a[@class="avatar-box"]'
|
||||
expr_actorphoto = '//a[@class="avatar-box"]'
|
||||
expr_title = '/html/body/div[2]/h3/text()'
|
||||
expr_studio = '//p[contains(text(),"制作商: ")]/following-sibling::p[1]/a/text()'
|
||||
expr_release = '//span[contains(text(),"发行时间:")]/../text()'
|
||||
expr_cover = '/html/body/div[2]/div[1]/div[1]/a/img/@src'
|
||||
expr_smallcover = '//*[@id="waterfall"]/div/a/div[1]/img/@src'
|
||||
expr_tags = '/html/head/meta[@name="keywords"]/@content'
|
||||
expr_label = '//p[contains(text(),"系列:")]/following-sibling::p[1]/a/text()'
|
||||
expr_series = '//span[contains(text(),"系列:")]/../span[2]/text()'
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 3
|
||||
self.originalnum = ''
|
||||
|
||||
def queryNumberUrl(self, number: str):
|
||||
upnum = number.upper()
|
||||
if 'FC2' in upnum and 'FC2-PPV' not in upnum:
|
||||
number = upnum.replace('FC2', 'FC2-PPV')
|
||||
self.number = number
|
||||
qurySiteTree = self.getHtmlTree('https://tellme.pw/avsox')
|
||||
site = self.getTreeElement(qurySiteTree, '//div[@class="container"]/div/a/@href')
|
||||
self.searchtree = self.getHtmlTree(site + '/cn/search/' + number)
|
||||
result1 = self.getTreeElement(self.searchtree, '//*[@id="waterfall"]/div/a/@href')
|
||||
if result1 == '' or result1 == 'null' or result1 == 'None' or result1.find('movie') == -1:
|
||||
self.searchtree = self.getHtmlTree(site + '/cn/search/' + number.replace('-', '_'))
|
||||
result1 = self.getTreeElement(self.searchtree, '//*[@id="waterfall"]/div/a/@href')
|
||||
if result1 == '' or result1 == 'null' or result1 == 'None' or result1.find('movie') == -1:
|
||||
self.searchtree = self.getHtmlTree(site + '/cn/search/' + number.replace('_', ''))
|
||||
result1 = self.getTreeElement(self.searchtree, '//*[@id="waterfall"]/div/a/@href')
|
||||
if result1 == '' or result1 == 'null' or result1 == 'None' or result1.find('movie') == -1:
|
||||
return None
|
||||
return "https:" + result1
|
||||
|
||||
def getNum(self, htmltree):
|
||||
new_number = self.getTreeElement(htmltree, self.expr_number)
|
||||
if new_number.upper() != self.number.upper():
|
||||
raise ValueError('number not found in ' + self.source)
|
||||
self.originalnum = new_number
|
||||
if 'FC2-PPV' in new_number.upper():
|
||||
new_number = new_number.upper().replace('FC2-PPV', 'FC2')
|
||||
self.number = new_number
|
||||
return self.number
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
return super().getTitle(htmltree).replace('/', '').strip(self.originalnum).strip()
|
||||
|
||||
def getStudio(self, htmltree):
|
||||
return super().getStudio(htmltree).replace("', '", ' ')
|
||||
|
||||
def getSmallCover(self, htmltree):
|
||||
""" 使用搜索页面的预览小图
|
||||
"""
|
||||
try:
|
||||
return self.getTreeElement(self.searchtree, self.expr_smallcover)
|
||||
except:
|
||||
self.imagecut = 1
|
||||
return ''
|
||||
|
||||
def getTags(self, htmltree):
|
||||
tags = self.getTreeElement(htmltree, self.expr_tags).split(',')
|
||||
return [i.strip() for i in tags[2:]] if len(tags) > 2 else []
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
if self.morestoryline:
|
||||
from .storyline import getStoryline
|
||||
return getStoryline(self.number, proxies=self.proxies, verify=self.verify)
|
||||
return ''
|
||||
|
||||
def getActors(self, htmltree):
|
||||
a = super().getActors(htmltree)
|
||||
d = []
|
||||
for i in a:
|
||||
d.append(i.find('span').text)
|
||||
return d
|
||||
|
||||
def getActorPhoto(self, htmltree):
|
||||
a = self.getTreeAll(htmltree, self.expr_actorphoto)
|
||||
d = {}
|
||||
for i in a:
|
||||
l = i.find('.//img').attrib['src']
|
||||
t = i.find('span').text
|
||||
p2 = {t: l}
|
||||
d.update(p2)
|
||||
return d
|
||||
106
scrapinglib/carib.py
Normal file
@@ -0,0 +1,106 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from urllib.parse import urljoin
|
||||
from lxml import html
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Carib(Parser):
|
||||
source = 'carib'
|
||||
|
||||
expr_title = "//div[@class='movie-info section']/div[@class='heading']/h1[@itemprop='name']/text()"
|
||||
expr_release = "//li[2]/span[@class='spec-content']/text()"
|
||||
expr_runtime = "//span[@class='spec-content']/span[@itemprop='duration']/text()"
|
||||
expr_actor = "//span[@class='spec-content']/a[@itemprop='actor']/span/text()"
|
||||
expr_tags = "//span[@class='spec-content']/a[@itemprop='genre']/text()"
|
||||
expr_extrafanart = "//*[@id='sampleexclude']/div[2]/div/div[@class='grid-item']/div/a/@href"
|
||||
expr_label = "//span[@class='spec-title'][contains(text(),'シリーズ')]/../span[@class='spec-content']/a/text()"
|
||||
expr_series = "//span[@class='spec-title'][contains(text(),'シリーズ')]/../span[@class='spec-content']/a/text()"
|
||||
expr_outline = "//div[@class='movie-info section']/p[@itemprop='description']/text()"
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 1
|
||||
self.uncensored = True
|
||||
|
||||
def search(self, number):
|
||||
self.number = number
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = f'https://www.caribbeancom.com/moviepages/{number}/index.html'
|
||||
htmlcode = self.getHtml(self.detailurl)
|
||||
if htmlcode == 404 or 'class="movie-info section"' not in htmlcode:
|
||||
return 404
|
||||
htmltree = html.fromstring(htmlcode)
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getStudio(self, htmltree):
|
||||
return '加勒比'
|
||||
|
||||
def getActors(self, htmltree):
|
||||
r = []
|
||||
actors = super().getActors(htmltree)
|
||||
for act in actors:
|
||||
if str(act) != '他':
|
||||
r.append(act)
|
||||
return r
|
||||
|
||||
def getNum(self, htmltree):
|
||||
return self.number
|
||||
|
||||
def getCover(self, htmltree):
|
||||
return f'https://www.caribbeancom.com/moviepages/{self.number}/images/l_l.jpg'
|
||||
|
||||
def getExtrafanart(self, htmltree):
|
||||
r = []
|
||||
genres = self.getTreeAll(htmltree, self.expr_extrafanart)
|
||||
for g in genres:
|
||||
jpg = str(g)
|
||||
if '/member/' in jpg:
|
||||
break
|
||||
else:
|
||||
r.append('https://www.caribbeancom.com' + jpg)
|
||||
return r
|
||||
|
||||
def getTrailer(self, htmltree):
|
||||
return f'https://smovie.caribbeancom.com/sample/movies/{self.number}/1080p.mp4'
|
||||
|
||||
def getActorPhoto(self, htmltree):
|
||||
htmla = htmltree.xpath("//*[@id='moviepages']/div[@class='container']/div[@class='inner-container']/div[@class='movie-info section']/ul/li[@class='movie-spec']/span[@class='spec-content']/a[@itemprop='actor']")
|
||||
names = htmltree.xpath("//*[@id='moviepages']/div[@class='container']/div[@class='inner-container']/div[@class='movie-info section']/ul/li[@class='movie-spec']/span[@class='spec-content']/a[@itemprop='actor']/span[@itemprop='name']/text()")
|
||||
t = {}
|
||||
for name, a in zip(names, htmla):
|
||||
if name.strip() == '他':
|
||||
continue
|
||||
p = {name.strip(): a.attrib['href']}
|
||||
t.update(p)
|
||||
o = {}
|
||||
for k, v in t.items():
|
||||
if '/search_act/' not in v:
|
||||
continue
|
||||
r = self.getHtml(urljoin('https://www.caribbeancom.com', v), type='object')
|
||||
if not r.ok:
|
||||
continue
|
||||
html = r.text
|
||||
pos = html.find('.full-bg')
|
||||
if pos<0:
|
||||
continue
|
||||
css = html[pos:pos+100]
|
||||
cssBGjpgs = re.findall(r'background: url\((.+\.jpg)', css, re.I)
|
||||
if not cssBGjpgs or not len(cssBGjpgs[0]):
|
||||
continue
|
||||
p = {k: urljoin(r.url, cssBGjpgs[0])}
|
||||
o.update(p)
|
||||
return o
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
if self.morestoryline:
|
||||
from .storyline import getStoryline
|
||||
result = getStoryline(self.number, uncensored=self.uncensored,
|
||||
proxies=self.proxies, verify=self.verify)
|
||||
if len(result):
|
||||
return result
|
||||
return super().getOutline(htmltree)
|
||||
|
||||
106
scrapinglib/caribpr.py
Normal file
@@ -0,0 +1,106 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from urllib.parse import urljoin
|
||||
from lxml import html
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Caribpr(Parser):
|
||||
source = 'caribpr'
|
||||
|
||||
expr_title = "//div[@class='movie-info']/div[@class='section is-wide']/div[@class='heading']/h1/text()"
|
||||
expr_release = "//li[2]/span[@class='spec-content']/text()"
|
||||
expr_runtime = "//li[3]/span[@class='spec-content']/text()"
|
||||
expr_actor = "//li[1]/span[@class='spec-content']/a[@class='spec-item']/text()"
|
||||
expr_tags = "//li[5]/span[@class='spec-content']/a[@class='spec-item']/text()"
|
||||
expr_extrafanart = "//div[@class='movie-gallery']/div[@class='section is-wide']/div[2]/div[@class='grid-item']/div/a/@href"
|
||||
# expr_label = "//span[@class='spec-title'][contains(text(),'シリーズ')]/../span[@class='spec-content']/a/text()"
|
||||
# expr_series = "//span[@class='spec-title'][contains(text(),'シリーズ')]/../span[@class='spec-content']/a/text()"
|
||||
expr_outline = "//div[@class='movie-info']/div[@class='section is-wide']/p/text()"
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 1
|
||||
self.uncensored = True
|
||||
|
||||
def search(self, number):
|
||||
self.number = number
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = f'https://www.caribbeancompr.com/moviepages/{number}/index.html'
|
||||
htmlcode = self.getHtml(self.detailurl)
|
||||
if htmlcode == 404 or 'class="movie-info"' not in htmlcode:
|
||||
return 404
|
||||
htmltree = html.fromstring(htmlcode)
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getStudio(self, htmltree):
|
||||
return '加勒比'
|
||||
|
||||
def getActors(self, htmltree):
|
||||
r = []
|
||||
actors = super().getActors(htmltree)
|
||||
for act in actors:
|
||||
if str(act) != '他':
|
||||
r.append(act)
|
||||
return r
|
||||
|
||||
def getNum(self, htmltree):
|
||||
return self.number
|
||||
|
||||
def getCover(self, htmltree):
|
||||
return f'https://www.caribbeancompr.com/moviepages/{self.number}/images/l_l.jpg'
|
||||
|
||||
def getExtrafanart(self, htmltree):
|
||||
r = []
|
||||
genres = self.getTreeAll(htmltree, self.expr_extrafanart)
|
||||
for g in genres:
|
||||
jpg = str(g)
|
||||
if '/member/' in jpg:
|
||||
break
|
||||
else:
|
||||
r.append(jpg)
|
||||
return r
|
||||
|
||||
def getTrailer(self, htmltree):
|
||||
return f'https://smovie.caribbeancompr.com/sample/movies/{self.number}/480p.mp4'
|
||||
|
||||
def getActorPhoto(self, htmltree):
|
||||
htmla = htmltree.xpath("//*[@id='moviepages']/div[@class='container']/div[@class='inner-container']/div[@class='movie-info section']/ul/li[@class='movie-spec']/span[@class='spec-content']/a[@itemprop='actor']")
|
||||
names = htmltree.xpath("//*[@id='moviepages']/div[@class='container']/div[@class='inner-container']/div[@class='movie-info section']/ul/li[@class='movie-spec']/span[@class='spec-content']/a[@itemprop='actor']/span[@itemprop='name']/text()")
|
||||
t = {}
|
||||
for name, a in zip(names, htmla):
|
||||
if name.strip() == '他':
|
||||
continue
|
||||
p = {name.strip(): a.attrib['href']}
|
||||
t.update(p)
|
||||
o = {}
|
||||
for k, v in t.items():
|
||||
if '/search_act/' not in v:
|
||||
continue
|
||||
r = self.getHtml(urljoin('https://www.caribbeancompr.com', v), type='object')
|
||||
if not r.ok:
|
||||
continue
|
||||
html = r.text
|
||||
pos = html.find('.full-bg')
|
||||
if pos<0:
|
||||
continue
|
||||
css = html[pos:pos+100]
|
||||
cssBGjpgs = re.findall(r'background: url\((.+\.jpg)', css, re.I)
|
||||
if not cssBGjpgs or not len(cssBGjpgs[0]):
|
||||
continue
|
||||
p = {k: urljoin(r.url, cssBGjpgs[0])}
|
||||
o.update(p)
|
||||
return o
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
if self.morestoryline:
|
||||
from .storyline import getStoryline
|
||||
result = getStoryline(self.number, uncensored=self.uncensored,
|
||||
proxies=self.proxies, verify=self.verify)
|
||||
if len(result):
|
||||
return result
|
||||
return super().getOutline(htmltree)
|
||||
|
||||
104
scrapinglib/dlsite.py
Normal file
@@ -0,0 +1,104 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Dlsite(Parser):
|
||||
source = 'dlsite'
|
||||
|
||||
expr_title = '/html/head/title/text()'
|
||||
expr_actor = '//th[contains(text(),"声优")]/../td/a/text()'
|
||||
expr_studio = '//th[contains(text(),"商标名")]/../td/span[1]/a/text()'
|
||||
expr_studio2 = '//th[contains(text(),"社团名")]/../td/span[1]/a/text()'
|
||||
expr_runtime = '//strong[contains(text(),"時長")]/../span/text()'
|
||||
expr_runtime2 = '//strong[contains(text(),"時長")]/../span/a/text()'
|
||||
expr_outline = '//*[@class="work_parts_area"]/p/text()'
|
||||
expr_series = '//th[contains(text(),"系列名")]/../td/a/text()'
|
||||
expr_series2 = '//th[contains(text(),"社团名")]/../td/span[1]/a/text()'
|
||||
expr_director = '//th[contains(text(),"剧情")]/../td/a/text()'
|
||||
expr_release = '//th[contains(text(),"贩卖日")]/../td/a/text()'
|
||||
expr_cover = '//*[@id="work_left"]/div/div/div[2]/div/div[1]/div[1]/ul/li[1]/picture/source/@srcset'
|
||||
expr_tags = '//th[contains(text(),"分类")]/../td/div/a/text()'
|
||||
expr_label = '//th[contains(text(),"系列名")]/../td/a/text()'
|
||||
expr_label2 = '//th[contains(text(),"社团名")]/../td/span[1]/a/text()'
|
||||
expr_extrafanart = '//*[@id="work_left"]/div/div/div[1]/div/@data-src'
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 4
|
||||
self.allow_number_change = True
|
||||
|
||||
def search(self, number):
|
||||
self.cookies = {'locale': 'zh-cn'}
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
# TODO 应该从页面内获取 number
|
||||
self.number = str(re.findall("\wJ\w+", self.detailurl)).strip(" [']")
|
||||
htmltree = self.getHtmlTree(self.detailurl)
|
||||
elif "RJ" in number or "VJ" in number:
|
||||
self.number = number.upper()
|
||||
self.detailurl = 'https://www.dlsite.com/maniax/work/=/product_id/' + self.number + '.html/?locale=zh_CN'
|
||||
htmltree = self.getHtmlTree(self.detailurl)
|
||||
else:
|
||||
self.detailurl = f'https://www.dlsite.com/maniax/fsr/=/language/jp/sex_category/male/keyword/{number}/order/trend/work_type_category/movie'
|
||||
htmltree = self.getHtmlTree(self.detailurl)
|
||||
search_result = self.getTreeAll(htmltree, '//*[@id="search_result_img_box"]/li[1]/dl/dd[2]/div[2]/a/@href')
|
||||
if len(search_result) == 0:
|
||||
number = number.replace("THE ANIMATION", "").replace("he Animation", "").replace("t", "").replace("T","")
|
||||
htmltree = self.getHtmlTree(f'https://www.dlsite.com/maniax/fsr/=/language/jp/sex_category/male/keyword/{number}/order/trend/work_type_category/movie')
|
||||
search_result = self.getTreeAll(htmltree, '//*[@id="search_result_img_box"]/li[1]/dl/dd[2]/div[2]/a/@href')
|
||||
if len(search_result) == 0:
|
||||
if "~" in number:
|
||||
number = number.replace("~","〜")
|
||||
elif "〜" in number:
|
||||
number = number.replace("〜","~")
|
||||
htmltree = self.getHtmlTree(f'https://www.dlsite.com/maniax/fsr/=/language/jp/sex_category/male/keyword/{number}/order/trend/work_type_category/movie')
|
||||
search_result = self.getTreeAll(htmltree, '//*[@id="search_result_img_box"]/li[1]/dl/dd[2]/div[2]/a/@href')
|
||||
if len(search_result) == 0:
|
||||
number = number.replace('上巻', '').replace('下巻', '').replace('前編', '').replace('後編', '')
|
||||
htmltree = self.getHtmlTree(f'https://www.dlsite.com/maniax/fsr/=/language/jp/sex_category/male/keyword/{number}/order/trend/work_type_category/movie')
|
||||
search_result = self.getTreeAll(htmltree, '//*[@id="search_result_img_box"]/li[1]/dl/dd[2]/div[2]/a/@href')
|
||||
self.detailurl = search_result[0]
|
||||
htmltree = self.getHtmlTree(self.detailurl)
|
||||
self.number = str(re.findall("\wJ\w+", self.detailurl)).strip(" [']")
|
||||
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getNum(self, htmltree):
|
||||
return self.number
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
result = super().getTitle(htmltree)
|
||||
result = result[:result.rfind(' | DLsite')]
|
||||
result = result[:result.rfind(' [')]
|
||||
if 'OFF】' in result:
|
||||
result = result[result.find('】')+1:]
|
||||
result = result.replace('【HD版】', '')
|
||||
return result
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
total = []
|
||||
result = self.getTreeAll(htmltree, self.expr_outline)
|
||||
total = [ x.strip() for x in result if x.strip()]
|
||||
return '\n'.join(total)
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
return super().getRelease(htmltree).replace('年','-').replace('月','-').replace('日','')
|
||||
|
||||
def getCover(self, htmltree):
|
||||
return 'https:' + super().getCover(htmltree).replace('.webp', '.jpg')
|
||||
|
||||
def getExtrafanart(self, htmltree):
|
||||
try:
|
||||
result = []
|
||||
for i in self.getTreeAll(self.expr_extrafanart):
|
||||
result.append("https:" + i)
|
||||
except:
|
||||
result = ''
|
||||
return result
|
||||
|
||||
def getTags(self, htmltree):
|
||||
tags = super().getTags(htmltree)
|
||||
tags.append("DLsite")
|
||||
return tags
|
||||
175
scrapinglib/fanza.py
Normal file
@@ -0,0 +1,175 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from lxml import etree
|
||||
from urllib.parse import urlencode
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Fanza(Parser):
|
||||
source = 'fanza'
|
||||
|
||||
expr_title = '//*[starts-with(@id, "title")]/text()'
|
||||
expr_actor = "//td[contains(text(),'出演者')]/following-sibling::td/span/a/text()"
|
||||
# expr_cover = './/head/meta[@property="og:image"]/@content'
|
||||
# expr_extrafanart = '//a[@name="sample-image"]/img/@src'
|
||||
expr_outline = "//div[@class='mg-b20 lh4']/text()"
|
||||
expr_outline2 = "//div[@class='mg-b20 lh4']//p/text()"
|
||||
expr_outline_og = '//head/meta[@property="og:description"]/@content'
|
||||
expr_runtime = "//td[contains(text(),'収録時間')]/following-sibling::td/text()"
|
||||
|
||||
def search(self, number):
|
||||
self.number = number
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
durl = "https://www.dmm.co.jp/age_check/=/declared=yes/?"+ urlencode({"rurl": self.detailurl})
|
||||
self.htmltree = self.getHtmlTree(durl)
|
||||
result = self.dictformat(self.htmltree)
|
||||
return result
|
||||
# fanza allow letter + number + underscore, normalize the input here
|
||||
# @note: I only find the usage of underscore as h_test123456789
|
||||
fanza_search_number = number
|
||||
# AV_Data_Capture.py.getNumber() over format the input, restore the h_ prefix
|
||||
if fanza_search_number.startswith("h-"):
|
||||
fanza_search_number = fanza_search_number.replace("h-", "h_")
|
||||
|
||||
fanza_search_number = re.sub(r"[^0-9a-zA-Z_]", "", fanza_search_number).lower()
|
||||
|
||||
fanza_urls = [
|
||||
"https://www.dmm.co.jp/digital/videoa/-/detail/=/cid=",
|
||||
"https://www.dmm.co.jp/mono/dvd/-/detail/=/cid=",
|
||||
"https://www.dmm.co.jp/digital/anime/-/detail/=/cid=",
|
||||
"https://www.dmm.co.jp/mono/anime/-/detail/=/cid=",
|
||||
"https://www.dmm.co.jp/digital/videoc/-/detail/=/cid=",
|
||||
"https://www.dmm.co.jp/digital/nikkatsu/-/detail/=/cid=",
|
||||
"https://www.dmm.co.jp/rental/-/detail/=/cid=",
|
||||
]
|
||||
|
||||
for url in fanza_urls:
|
||||
self.detailurl = url + fanza_search_number
|
||||
url = "https://www.dmm.co.jp/age_check/=/declared=yes/?"+ urlencode({"rurl": self.detailurl})
|
||||
self.htmlcode = self.getHtml(url)
|
||||
if self.htmlcode != 404 \
|
||||
and 'Sorry! This content is not available in your region.' not in self.htmlcode:
|
||||
self.htmltree = etree.HTML(self.htmlcode)
|
||||
if self.htmltree is not None:
|
||||
result = self.dictformat(self.htmltree)
|
||||
return result
|
||||
return 404
|
||||
|
||||
def getNum(self, htmltree):
|
||||
# for some old page, the input number does not match the page
|
||||
# for example, the url will be cid=test012
|
||||
# but the hinban on the page is test00012
|
||||
# so get the hinban first, and then pass it to following functions
|
||||
self.fanza_hinban = self.getFanzaString('品番:')
|
||||
self.number = self.fanza_hinban
|
||||
number_lo = self.number.lower()
|
||||
if (re.sub('-|_', '', number_lo) == self.fanza_hinban or
|
||||
number_lo.replace('-', '00') == self.fanza_hinban or
|
||||
number_lo.replace('-', '') + 'so' == self.fanza_hinban
|
||||
):
|
||||
self.number = self.number
|
||||
return self.number
|
||||
|
||||
def getStudio(self, htmltree):
|
||||
return self.getFanzaString('メーカー')
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
try:
|
||||
result = self.getTreeElement(htmltree, self.expr_outline).replace("\n", "")
|
||||
if result == '':
|
||||
result = self.getTreeElement(htmltree, self.expr_outline2).replace("\n", "")
|
||||
if "※ 配信方法によって収録内容が異なる場合があります。" == result:
|
||||
result = self.getTreeElement(htmltree, self.expr_outline_og)
|
||||
return result
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getRuntime(self, htmltree):
|
||||
return str(re.search(r'\d+', super().getRuntime(htmltree)).group()).strip(" ['']")
|
||||
|
||||
def getDirector(self, htmltree):
|
||||
if "anime" not in self.detailurl:
|
||||
return self.getFanzaString('監督:')
|
||||
return ''
|
||||
|
||||
def getActors(self, htmltree):
|
||||
if "anime" not in self.detailurl:
|
||||
return super().getActors(htmltree)
|
||||
return ''
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
result = self.getFanzaString('発売日:')
|
||||
if result == '' or result == '----':
|
||||
result = self.getFanzaString('配信開始日:')
|
||||
return result.replace("/", "-").strip('\\n')
|
||||
|
||||
def getTags(self, htmltree):
|
||||
return self.getFanzaStrings('ジャンル:')
|
||||
|
||||
def getLabel(self, htmltree):
|
||||
ret = self.getFanzaString('レーベル')
|
||||
if ret == "----":
|
||||
return ''
|
||||
return ret
|
||||
|
||||
def getSeries(self, htmltree):
|
||||
ret = self.getFanzaString('シリーズ:')
|
||||
if ret == "----":
|
||||
return ''
|
||||
return ret
|
||||
|
||||
def getCover(self, htmltree):
|
||||
cover_number = self.number
|
||||
try:
|
||||
result = htmltree.xpath('//*[@id="' + cover_number + '"]/@href')[0]
|
||||
except:
|
||||
# sometimes fanza modify _ to \u0005f for image id
|
||||
if "_" in cover_number:
|
||||
cover_number = cover_number.replace("_", r"\u005f")
|
||||
try:
|
||||
result = htmltree.xpath('//*[@id="' + cover_number + '"]/@href')[0]
|
||||
except:
|
||||
# (TODO) handle more edge case
|
||||
# print(html)
|
||||
# raise exception here, same behavior as before
|
||||
# people's major requirement is fetching the picture
|
||||
raise ValueError("can not find image")
|
||||
return result
|
||||
|
||||
def getExtrafanart(self, htmltree):
|
||||
htmltext = re.search(r'<div id=\"sample-image-block\"[\s\S]*?<br></div>\s*?</div>', self.htmlcode)
|
||||
if htmltext:
|
||||
htmltext = htmltext.group()
|
||||
extrafanart_images = re.findall(r'<img.*?src=\"(.*?)\"', htmltext)
|
||||
if extrafanart_images:
|
||||
sheet = []
|
||||
for img_url in extrafanart_images:
|
||||
url_cuts = img_url.rsplit('-', 1)
|
||||
sheet.append(url_cuts[0] + 'jp-' + url_cuts[1])
|
||||
return sheet
|
||||
return ''
|
||||
|
||||
def getTrailer(self, htmltree):
|
||||
htmltext = re.search(r'<script type=\"application/ld\+json\">[\s\S].*}\s*?</script>', self.htmlcode)
|
||||
if htmltext:
|
||||
htmltext = htmltext.group()
|
||||
url = re.search(r'\"contentUrl\":\"(.*?)\"', htmltext)
|
||||
if url:
|
||||
url = url.group(1)
|
||||
url = url.rsplit('_', 2)[0] + '_mhb_w.mp4'
|
||||
return url
|
||||
return ''
|
||||
|
||||
def getFanzaString(self, expr):
|
||||
result1 = str(self.htmltree.xpath("//td[contains(text(),'"+expr+"')]/following-sibling::td/a/text()")).strip(" ['']")
|
||||
result2 = str(self.htmltree.xpath("//td[contains(text(),'"+expr+"')]/following-sibling::td/text()")).strip(" ['']")
|
||||
return result1+result2
|
||||
|
||||
def getFanzaStrings(self, string):
|
||||
result1 = self.htmltree.xpath("//td[contains(text(),'" + string + "')]/following-sibling::td/a/text()")
|
||||
if len(result1) > 0:
|
||||
return result1
|
||||
result2 = self.htmltree.xpath("//td[contains(text(),'" + string + "')]/following-sibling::td/text()")
|
||||
return result2
|
||||
67
scrapinglib/fc2.py
Normal file
@@ -0,0 +1,67 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from lxml import etree
|
||||
from urllib.parse import urljoin
|
||||
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Fc2(Parser):
|
||||
source = 'fc2'
|
||||
|
||||
expr_title = '/html/head/title/text()'
|
||||
expr_studio = '//*[@id="top"]/div[1]/section[1]/div/section/div[2]/ul/li[3]/a/text()'
|
||||
expr_release = '//*[@id="top"]/div[1]/section[1]/div/section/div[2]/div[2]/p/text()'
|
||||
expr_runtime = "//p[@class='items_article_info']/text()"
|
||||
expr_director = '//*[@id="top"]/div[1]/section[1]/div/section/div[2]/ul/li[3]/a/text()'
|
||||
expr_actor = '//*[@id="top"]/div[1]/section[1]/div/section/div[2]/ul/li[3]/a/text()'
|
||||
expr_cover = "//div[@class='items_article_MainitemThumb']/span/img/@src"
|
||||
expr_extrafanart = '//ul[@class="items_article_SampleImagesArea"]/li/a/@href'
|
||||
expr_tags = "//a[@class='tag tagTag']/text()"
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 0
|
||||
self.allow_number_change = True
|
||||
|
||||
def search(self, number):
|
||||
self.number = number.lower().replace('fc2-ppv-', '').replace('fc2-', '')
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = 'https://adult.contents.fc2.com/article/' + self.number + '/'
|
||||
self.htmlcode = self.getHtml(self.detailurl)
|
||||
if self.htmlcode == 404:
|
||||
return 404
|
||||
htmltree = etree.HTML(self.htmlcode)
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getNum(self, htmltree):
|
||||
return 'FC2-' + self.number
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
return super().getRelease(htmltree).strip(" ['販売日 : ']").replace('/','-')
|
||||
|
||||
def getActors(self, htmltree):
|
||||
actors = super().getActors(htmltree)
|
||||
if not actors:
|
||||
actors = '素人'
|
||||
return actors
|
||||
|
||||
def getCover(self, htmltree):
|
||||
return urljoin('https://adult.contents.fc2.com', super().getCover(htmltree))
|
||||
|
||||
def getTrailer(self, htmltree):
|
||||
video_pather = re.compile(r'\'[a-zA-Z0-9]{32}\'')
|
||||
video = video_pather.findall(self.htmlcode)
|
||||
if video:
|
||||
try:
|
||||
video_url = video[0].replace('\'', '')
|
||||
video_url = 'https://adult.contents.fc2.com/api/v2/videos/' + self.number + '/sample?key=' + video_url
|
||||
url_json = eval(self.getHtml(video_url))['path'].replace('\\', '')
|
||||
return url_json
|
||||
except:
|
||||
return ''
|
||||
else:
|
||||
return ''
|
||||
73
scrapinglib/gcolle.py
Normal file
@@ -0,0 +1,73 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from lxml import etree
|
||||
from .httprequest import request_session
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Gcolle(Parser):
|
||||
source = 'gcolle'
|
||||
|
||||
expr_r18 = '//*[@id="main_content"]/table[1]/tbody/tr/td[2]/table/tbody/tr/td/h4/a[2]/@href'
|
||||
expr_number = '//td[contains(text(),"商品番号")]/../td[2]/text()'
|
||||
expr_title = '//*[@id="cart_quantity"]/table/tr[1]/td/h1/text()'
|
||||
expr_studio = '//td[contains(text(),"アップロード会員名")]/b/text()'
|
||||
expr_director = '//td[contains(text(),"アップロード会員名")]/b/text()'
|
||||
expr_actor = '//td[contains(text(),"アップロード会員名")]/b/text()'
|
||||
expr_label = '//td[contains(text(),"アップロード会員名")]/b/text()'
|
||||
expr_series = '//td[contains(text(),"アップロード会員名")]/b/text()'
|
||||
expr_release = '//td[contains(text(),"商品登録日")]/../td[2]/time/@datetime'
|
||||
expr_cover = '//*[@id="cart_quantity"]/table/tr[3]/td/table/tr/td/a/@href'
|
||||
expr_tags = '//*[@id="cart_quantity"]/table/tr[4]/td/a/text()'
|
||||
expr_outline = '//*[@id="cart_quantity"]/table/tr[3]/td/p/text()'
|
||||
expr_extrafanart = '//*[@id="cart_quantity"]/table/tr[3]/td/div/img/@src'
|
||||
expr_extrafanart2 = '//*[@id="cart_quantity"]/table/tr[3]/td/div/a/img/@src'
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 4
|
||||
|
||||
def search(self, number: str):
|
||||
self.number = number.upper().replace('GCOLLE-', '')
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = 'https://gcolle.net/product_info.php/products_id/' + self.number
|
||||
session = request_session(cookies=self.cookies, proxies=self.proxies, verify=self.verify)
|
||||
htmlcode = session.get(self.detailurl).text
|
||||
htmltree = etree.HTML(htmlcode)
|
||||
|
||||
r18url = self.getTreeElement(htmltree, self.expr_r18)
|
||||
if r18url and r18url.startswith('http'):
|
||||
htmlcode = session.get(r18url).text
|
||||
htmltree = etree.HTML(htmlcode)
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getNum(self, htmltree):
|
||||
num = super().getNum(htmltree)
|
||||
if self.number != num:
|
||||
raise Exception(f'[!] {self.number}: find [{num}] in gcolle, not match')
|
||||
return "GCOLLE-" + str(num)
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
result = self.getTreeAll(htmltree, self.expr_outline)
|
||||
try:
|
||||
return "\n".join(result)
|
||||
except:
|
||||
return ""
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
return re.findall('\d{4}-\d{2}-\d{2}', super().getRelease(htmltree))[0]
|
||||
|
||||
def getCover(self, htmltree):
|
||||
return "https:" + super().getCover(htmltree)
|
||||
|
||||
def getExtrafanart(self, htmltree):
|
||||
extrafanart = self.getTreeAll(htmltree, self.expr_extrafanart)
|
||||
if len(extrafanart) == 0:
|
||||
extrafanart = self.getTreeAll(htmltree, self.expr_extrafanart2)
|
||||
# Add "https:" in each extrafanart url
|
||||
for i in range(len(extrafanart)):
|
||||
extrafanart[i] = 'https:' + extrafanart[i]
|
||||
return extrafanart
|
||||
175
scrapinglib/getchu.py
Normal file
@@ -0,0 +1,175 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
import json
|
||||
from urllib.parse import quote
|
||||
|
||||
from scrapinglib import httprequest
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Getchu():
|
||||
source = 'getchu'
|
||||
|
||||
def scrape(self, number, core: None):
|
||||
dl = dlGetchu()
|
||||
www = wwwGetchu()
|
||||
number = number.replace("-C", "")
|
||||
dic = {}
|
||||
if "item" in number:
|
||||
sort = ["dl.scrape(number, core)", "www.scrape(number, core)"]
|
||||
else:
|
||||
sort = ["www.scrape(number, core)", "dl.scrape(number, core)"]
|
||||
for i in sort:
|
||||
try:
|
||||
dic = eval(i)
|
||||
if dic != None and json.loads(dic).get('title') != '':
|
||||
break
|
||||
except:
|
||||
pass
|
||||
return dic
|
||||
|
||||
class wwwGetchu(Parser):
|
||||
expr_title = '//*[@id="soft-title"]/text()'
|
||||
expr_cover = '//head/meta[@property="og:image"]/@content'
|
||||
expr_director = "//td[contains(text(),'ブランド')]/following-sibling::td/a[1]/text()"
|
||||
expr_studio = "//td[contains(text(),'ブランド')]/following-sibling::td/a[1]/text()"
|
||||
expr_actor = "//td[contains(text(),'ブランド')]/following-sibling::td/a[1]/text()"
|
||||
expr_label = "//td[contains(text(),'ジャンル:')]/following-sibling::td/text()"
|
||||
expr_release = "//td[contains(text(),'発売日:')]/following-sibling::td/a/text()"
|
||||
expr_tags = "//td[contains(text(),'カテゴリ')]/following-sibling::td/a/text()"
|
||||
expr_outline = "//div[contains(text(),'商品紹介')]/following-sibling::div/text()"
|
||||
expr_extrafanart = "//div[contains(text(),'サンプル画像')]/following-sibling::div/a/@href"
|
||||
expr_series = "//td[contains(text(),'ジャンル:')]/following-sibling::td/text()"
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 0
|
||||
self.allow_number_change = True
|
||||
|
||||
self.cookies = {'getchu_adalt_flag': 'getchu.com', "adult_check_flag": "1"}
|
||||
self.GETCHU_WWW_SEARCH_URL = 'http://www.getchu.com/php/search.phtml?genre=anime_dvd&search_keyword=_WORD_&check_key_dtl=1&submit='
|
||||
|
||||
def queryNumberUrl(self, number):
|
||||
if 'GETCHU' in number.upper():
|
||||
idn = re.findall('\d+',number)[0]
|
||||
return "http://www.getchu.com/soft.phtml?id=" + idn
|
||||
else:
|
||||
queryUrl = self.GETCHU_WWW_SEARCH_URL.replace("_WORD_", quote(number, encoding="euc_jp"))
|
||||
# NOTE dont know why will try 2 times
|
||||
retry = 2
|
||||
for i in range(retry):
|
||||
queryTree = self.getHtmlTree(queryUrl)
|
||||
detailurl = self.getTreeElement(queryTree, '//*[@id="detail_block"]/div/table/tr[1]/td/a[1]/@href')
|
||||
if detailurl:
|
||||
break
|
||||
if detailurl == "":
|
||||
return None
|
||||
return detailurl.replace('../', 'http://www.getchu.com/')
|
||||
|
||||
def getHtml(self, url, type = None):
|
||||
""" 访问网页(指定EUC-JP)
|
||||
"""
|
||||
resp = httprequest.get(url, cookies=self.cookies, proxies=self.proxies, extra_headers=self.extraheader, encoding='euc_jis_2004', verify=self.verify, return_type=type)
|
||||
if '<title>404 Page Not Found' in resp \
|
||||
or '<title>未找到页面' in resp \
|
||||
or '404 Not Found' in resp \
|
||||
or '<title>404' in resp \
|
||||
or '<title>お探しの商品が見つかりません' in resp:
|
||||
return 404
|
||||
return resp
|
||||
|
||||
def getNum(self, htmltree):
|
||||
return 'GETCHU-' + re.findall('\d+', self.detailurl.replace("http://www.getchu.com/soft.phtml?id=", ""))[0]
|
||||
|
||||
def getActors(self, htmltree):
|
||||
return super().getDirector(htmltree)
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
outline = ''
|
||||
_list = self.getTreeAll(htmltree, self.expr_outline)
|
||||
for i in _list:
|
||||
outline = outline + i.strip()
|
||||
return outline
|
||||
|
||||
def getCover(self, htmltree):
|
||||
url = super().getCover(htmltree)
|
||||
if "getchu.com" in url:
|
||||
return url
|
||||
return "http://www.getchu.com" + url
|
||||
|
||||
def getExtrafanart(self, htmltree):
|
||||
arts = super().getExtrafanart(htmltree)
|
||||
extrafanart = []
|
||||
for i in arts:
|
||||
i = "http://www.getchu.com" + i.replace("./", '/')
|
||||
if 'jpg' in i:
|
||||
extrafanart.append(i)
|
||||
return extrafanart
|
||||
|
||||
def extradict(self, dic: dict):
|
||||
""" 额外新增的 headers
|
||||
"""
|
||||
dic['headers'] = {'referer': self.detailurl}
|
||||
return dic
|
||||
|
||||
def getTags(self, htmltree):
|
||||
tags = super().getTags(htmltree)
|
||||
tags.append("Getchu")
|
||||
return tags
|
||||
|
||||
|
||||
class dlGetchu(wwwGetchu):
|
||||
""" 二者基本一致
|
||||
headers extrafanart 略有区别
|
||||
"""
|
||||
expr_title = "//div[contains(@style,'color: #333333; padding: 3px 0px 0px 5px;')]/text()"
|
||||
expr_director = "//td[contains(text(),'作者')]/following-sibling::td/text()"
|
||||
expr_studio = "//td[contains(text(),'サークル')]/following-sibling::td/a/text()"
|
||||
expr_label = "//td[contains(text(),'サークル')]/following-sibling::td/a/text()"
|
||||
expr_runtime = "//td[contains(text(),'画像数&ページ数')]/following-sibling::td/text()"
|
||||
expr_release = "//td[contains(text(),'配信開始日')]/following-sibling::td/text()"
|
||||
expr_tags = "//td[contains(text(),'趣向')]/following-sibling::td/a/text()"
|
||||
expr_outline = "//*[contains(text(),'作品内容')]/following-sibling::td/text()"
|
||||
expr_extrafanart = "//td[contains(@style,'background-color: #444444;')]/a/@href"
|
||||
expr_series = "//td[contains(text(),'サークル')]/following-sibling::td/a/text()"
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 4
|
||||
self.allow_number_change = True
|
||||
|
||||
self.cookies = {"adult_check_flag": "1"}
|
||||
self.extraheader = {"Referer": "https://dl.getchu.com/"}
|
||||
|
||||
self.GETCHU_DL_SEARCH_URL = 'https://dl.getchu.com/search/search_list.php?dojin=1&search_category_id=&search_keyword=_WORD_&btnWordSearch=%B8%A1%BA%F7&action=search&set_category_flag=1'
|
||||
self.GETCHU_DL_URL = 'https://dl.getchu.com/i/item_WORD_'
|
||||
|
||||
def queryNumberUrl(self, number):
|
||||
if "item" in number or 'GETCHU' in number.upper():
|
||||
self.number = re.findall('\d+',number)[0]
|
||||
else:
|
||||
queryUrl = self.GETCHU_DL_SEARCH_URL.replace("_WORD_", quote(number, encoding="euc_jp"))
|
||||
queryTree = self.getHtmlTree(queryUrl)
|
||||
detailurl = self.getTreeElement(queryTree, '/html/body/div[1]/table/tr/td/table[4]/tr/td[2]/table/tr[2]/td/table/tr/td/table/tr/td[2]/div/a[1]/@href')
|
||||
if detailurl == "":
|
||||
return None
|
||||
self.number = re.findall('\d+', detailurl)[0]
|
||||
return self.GETCHU_DL_URL.replace("_WORD_", self.number)
|
||||
|
||||
def getNum(self, htmltree):
|
||||
return 'GETCHU-' + re.findall('\d+', self.number)[0]
|
||||
|
||||
def extradict(self, dic: dict):
|
||||
return dic
|
||||
|
||||
def getExtrafanart(self, htmltree):
|
||||
arts = self.getTreeAll(htmltree, self.expr_extrafanart)
|
||||
extrafanart = []
|
||||
for i in arts:
|
||||
i = "https://dl.getchu.com" + i
|
||||
extrafanart.append(i)
|
||||
return extrafanart
|
||||
|
||||
def getTags(self, htmltree):
|
||||
tags = super().getTags(htmltree)
|
||||
tags.append("Getchu")
|
||||
return tags
|
||||
193
scrapinglib/httprequest.py
Normal file
@@ -0,0 +1,193 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import mechanicalsoup
|
||||
import requests
|
||||
from requests.adapters import HTTPAdapter
|
||||
from urllib3.util.retry import Retry
|
||||
from cloudscraper import create_scraper
|
||||
|
||||
import config
|
||||
|
||||
G_USER_AGENT = r'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.133 Safari/537.36'
|
||||
G_DEFAULT_TIMEOUT = 10
|
||||
|
||||
|
||||
def get(url: str, cookies=None, ua: str = None, extra_headers=None, return_type: str = None, encoding: str = None,
|
||||
retry: int = 3, timeout: int = G_DEFAULT_TIMEOUT, proxies=None, verify=None):
|
||||
"""
|
||||
网页请求核心函数
|
||||
|
||||
是否使用代理应由上层处理
|
||||
"""
|
||||
errors = ""
|
||||
headers = {"User-Agent": ua or G_USER_AGENT}
|
||||
if extra_headers != None:
|
||||
headers.update(extra_headers)
|
||||
for i in range(retry):
|
||||
try:
|
||||
result = requests.get(url, headers=headers, timeout=timeout, proxies=proxies,
|
||||
verify=verify, cookies=cookies)
|
||||
if return_type == "object":
|
||||
return result
|
||||
elif return_type == "content":
|
||||
return result.content
|
||||
else:
|
||||
result.encoding = encoding or result.apparent_encoding
|
||||
return result.text
|
||||
except Exception as e:
|
||||
if config.getInstance().debug():
|
||||
print(f"[-]Connect: {url} retry {i + 1}/{retry}")
|
||||
errors = str(e)
|
||||
if config.getInstance().debug():
|
||||
if "getaddrinfo failed" in errors:
|
||||
print("[-]Connect Failed! Please Check your proxy config")
|
||||
print("[-]" + errors)
|
||||
else:
|
||||
print("[-]" + errors)
|
||||
print('[-]Connect Failed! Please check your Proxy or Network!')
|
||||
raise Exception('Connect Failed')
|
||||
|
||||
|
||||
def post(url: str, data: dict=None, files=None, cookies=None, ua: str=None, return_type: str=None, encoding: str=None,
|
||||
retry: int=3, timeout: int=G_DEFAULT_TIMEOUT, proxies=None, verify=None):
|
||||
"""
|
||||
是否使用代理应由上层处理
|
||||
"""
|
||||
errors = ""
|
||||
headers = {"User-Agent": ua or G_USER_AGENT}
|
||||
|
||||
for i in range(retry):
|
||||
try:
|
||||
result = requests.post(url, data=data, files=files, headers=headers, timeout=timeout, proxies=proxies,
|
||||
verify=verify, cookies=cookies)
|
||||
if return_type == "object":
|
||||
return result
|
||||
elif return_type == "content":
|
||||
return result.content
|
||||
else:
|
||||
result.encoding = encoding or result.apparent_encoding
|
||||
return result
|
||||
except Exception as e:
|
||||
if config.getInstance().debug():
|
||||
print(f"[-]Connect: {url} retry {i + 1}/{retry}")
|
||||
errors = str(e)
|
||||
if config.getInstance().debug():
|
||||
if "getaddrinfo failed" in errors:
|
||||
print("[-]Connect Failed! Please Check your proxy config")
|
||||
print("[-]" + errors)
|
||||
else:
|
||||
print("[-]" + errors)
|
||||
print('[-]Connect Failed! Please check your Proxy or Network!')
|
||||
raise Exception('Connect Failed')
|
||||
|
||||
|
||||
class TimeoutHTTPAdapter(HTTPAdapter):
|
||||
def __init__(self, *args, **kwargs):
|
||||
self.timeout = G_DEFAULT_TIMEOUT
|
||||
if "timeout" in kwargs:
|
||||
self.timeout = kwargs["timeout"]
|
||||
del kwargs["timeout"]
|
||||
super().__init__(*args, **kwargs)
|
||||
|
||||
def send(self, request, **kwargs):
|
||||
timeout = kwargs.get("timeout")
|
||||
if timeout is None:
|
||||
kwargs["timeout"] = self.timeout
|
||||
return super().send(request, **kwargs)
|
||||
|
||||
|
||||
def request_session(cookies=None, ua: str=None, retry: int=3, timeout: int=G_DEFAULT_TIMEOUT, proxies=None, verify=None):
|
||||
"""
|
||||
keep-alive
|
||||
"""
|
||||
session = requests.Session()
|
||||
retries = Retry(total=retry, connect=retry, backoff_factor=1,
|
||||
status_forcelist=[429, 500, 502, 503, 504])
|
||||
session.mount("https://", TimeoutHTTPAdapter(max_retries=retries, timeout=timeout))
|
||||
session.mount("http://", TimeoutHTTPAdapter(max_retries=retries, timeout=timeout))
|
||||
if isinstance(cookies, dict) and len(cookies):
|
||||
requests.utils.add_dict_to_cookiejar(session.cookies, cookies)
|
||||
if verify:
|
||||
session.verify = verify
|
||||
if proxies:
|
||||
session.proxies = proxies
|
||||
session.headers = {"User-Agent": ua or G_USER_AGENT}
|
||||
return session
|
||||
|
||||
|
||||
# storyline xcity only
|
||||
def get_html_by_form(url, form_select: str = None, fields: dict = None, cookies: dict = None, ua: str = None,
|
||||
return_type: str = None, encoding: str = None,
|
||||
retry: int = 3, timeout: int = G_DEFAULT_TIMEOUT, proxies=None, verify=None):
|
||||
session = requests.Session()
|
||||
if isinstance(cookies, dict) and len(cookies):
|
||||
requests.utils.add_dict_to_cookiejar(session.cookies, cookies)
|
||||
retries = Retry(total=retry, connect=retry, backoff_factor=1,
|
||||
status_forcelist=[429, 500, 502, 503, 504])
|
||||
session.mount("https://", TimeoutHTTPAdapter(max_retries=retries, timeout=timeout))
|
||||
session.mount("http://", TimeoutHTTPAdapter(max_retries=retries, timeout=timeout))
|
||||
if verify:
|
||||
session.verify = verify
|
||||
if proxies:
|
||||
session.proxies = proxies
|
||||
try:
|
||||
browser = mechanicalsoup.StatefulBrowser(user_agent=ua or G_USER_AGENT, session=session)
|
||||
result = browser.open(url)
|
||||
if not result.ok:
|
||||
return None
|
||||
form = browser.select_form() if form_select is None else browser.select_form(form_select)
|
||||
if isinstance(fields, dict):
|
||||
for k, v in fields.items():
|
||||
browser[k] = v
|
||||
response = browser.submit_selected()
|
||||
|
||||
if return_type == "object":
|
||||
return response
|
||||
elif return_type == "content":
|
||||
return response.content
|
||||
elif return_type == "browser":
|
||||
return response, browser
|
||||
else:
|
||||
result.encoding = encoding or "utf-8"
|
||||
return response.text
|
||||
except requests.exceptions.ProxyError:
|
||||
print("[-]get_html_by_form() Proxy error! Please check your Proxy")
|
||||
except Exception as e:
|
||||
print(f'[-]get_html_by_form() Failed! {e}')
|
||||
return None
|
||||
|
||||
# storyline javdb only
|
||||
def get_html_by_scraper(url: str = None, cookies: dict = None, ua: str = None, return_type: str = None,
|
||||
encoding: str = None, retry: int = 3, proxies=None, timeout: int = G_DEFAULT_TIMEOUT, verify=None):
|
||||
session = create_scraper(browser={'custom': ua or G_USER_AGENT, })
|
||||
if isinstance(cookies, dict) and len(cookies):
|
||||
requests.utils.add_dict_to_cookiejar(session.cookies, cookies)
|
||||
retries = Retry(total=retry, connect=retry, backoff_factor=1,
|
||||
status_forcelist=[429, 500, 502, 503, 504])
|
||||
session.mount("https://", TimeoutHTTPAdapter(max_retries=retries, timeout=timeout))
|
||||
session.mount("http://", TimeoutHTTPAdapter(max_retries=retries, timeout=timeout))
|
||||
if verify:
|
||||
session.verify = verify
|
||||
if proxies:
|
||||
session.proxies = proxies
|
||||
try:
|
||||
if isinstance(url, str) and len(url):
|
||||
result = session.get(str(url))
|
||||
else: # 空url参数直接返回可重用scraper对象,无需设置return_type
|
||||
return session
|
||||
if not result.ok:
|
||||
return None
|
||||
if return_type == "object":
|
||||
return result
|
||||
elif return_type == "content":
|
||||
return result.content
|
||||
elif return_type == "scraper":
|
||||
return result, session
|
||||
else:
|
||||
result.encoding = encoding or "utf-8"
|
||||
return result.text
|
||||
except requests.exceptions.ProxyError:
|
||||
print("[-]get_html_by_scraper() Proxy error! Please check your Proxy")
|
||||
except Exception as e:
|
||||
print(f"[-]get_html_by_scraper() failed. {e}")
|
||||
return None
|
||||
24
scrapinglib/imdb.py
Normal file
@@ -0,0 +1,24 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Imdb(Parser):
|
||||
source = 'imdb'
|
||||
imagecut = 0
|
||||
|
||||
expr_title = '//h1[@data-testid="hero-title-block__title"]/text()'
|
||||
expr_release = '//a[contains(text(),"Release date")]/following-sibling::div[1]/ul/li/a/text()'
|
||||
expr_cover = '//head/meta[@property="og:image"]/@content'
|
||||
expr_outline = '//head/meta[@property="og:description"]/@content'
|
||||
expr_actor = '//h3[contains(text(),"Top cast")]/../../../following-sibling::div[1]/div[2]/div/div/a/text()'
|
||||
expr_tags = '//div[@data-testid="genres"]/div[2]/a/ul/li/text()'
|
||||
|
||||
def queryNumberUrl(self, number):
|
||||
"""
|
||||
TODO 区分 ID 与 名称
|
||||
"""
|
||||
id = number
|
||||
movieUrl = "https://www.imdb.com/title/" + id
|
||||
return movieUrl
|
||||
60
scrapinglib/jav321.py
Normal file
@@ -0,0 +1,60 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from lxml import etree
|
||||
from . import httprequest
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Jav321(Parser):
|
||||
source = 'jav321'
|
||||
|
||||
expr_title = "/html/body/div[2]/div[1]/div[1]/div[1]/h3/text()"
|
||||
expr_cover = "/html/body/div[2]/div[2]/div[1]/p/a/img/@src"
|
||||
expr_outline = "/html/body/div[2]/div[1]/div[1]/div[2]/div[3]/div/text()"
|
||||
expr_number = '//b[contains(text(),"品番")]/following-sibling::node()'
|
||||
expr_actor = '//b[contains(text(),"出演者")]/following-sibling::a[starts-with(@href,"/star")]/text()'
|
||||
expr_label = '//b[contains(text(),"メーカー")]/following-sibling::a[starts-with(@href,"/company")]/text()'
|
||||
expr_tags = '//b[contains(text(),"ジャンル")]/following-sibling::a[starts-with(@href,"/genre")]/text()'
|
||||
expr_studio = '//b[contains(text(),"メーカー")]/following-sibling::a[starts-with(@href,"/company")]/text()'
|
||||
expr_release = '//b[contains(text(),"配信開始日")]/following-sibling::node()'
|
||||
expr_runtime = '//b[contains(text(),"収録時間")]/following-sibling::node()'
|
||||
expr_series = '//b[contains(text(),"シリーズ")]/following-sibling::node()'
|
||||
expr_extrafanart = '//div[@class="col-md-3"]/div[@class="col-xs-12 col-md-12"]/p/a/img/@src'
|
||||
|
||||
def queryNumberUrl(self, number):
|
||||
return 'https://www.jav321.com/search'
|
||||
|
||||
def getHtmlTree(self, url):
|
||||
"""
|
||||
特殊处理 仅获取页面调用一次
|
||||
"""
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
resp = httprequest.get(self.detailurl, cookies=self.cookies, proxies=self.proxies, verify=self.verify)
|
||||
self.detailhtml = resp
|
||||
return etree.fromstring(resp, etree.HTMLParser())
|
||||
resp = httprequest.post(url, data={"sn": self.number}, cookies=self.cookies, proxies=self.proxies, verify=self.verify)
|
||||
if "/video/" in resp.url:
|
||||
self.detailurl = resp.url
|
||||
self.detailhtml = resp.text
|
||||
return etree.fromstring(resp.text, etree.HTMLParser())
|
||||
return None
|
||||
|
||||
def getNum(self, htmltree):
|
||||
return super().getNum(htmltree).split(": ")[1]
|
||||
|
||||
def getTrailer(self, htmltree):
|
||||
videourl_pather = re.compile(r'<source src=\"(.*?)\"')
|
||||
videourl = videourl_pather.findall(self.detailhtml)
|
||||
if videourl:
|
||||
url = videourl[0].replace('awscc3001.r18.com', 'cc3001.dmm.co.jp').replace('cc3001.r18.com', 'cc3001.dmm.co.jp')
|
||||
return url
|
||||
else:
|
||||
return ''
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
return super().getRelease(htmltree).split(": ")[1]
|
||||
|
||||
def getRuntime(self, htmltree):
|
||||
return super().getRuntime(htmltree).split(": ")[1]
|
||||
140
scrapinglib/javbus.py
Normal file
@@ -0,0 +1,140 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
import os
|
||||
import secrets
|
||||
import inspect
|
||||
from lxml import etree
|
||||
from urllib.parse import urljoin
|
||||
from .parser import Parser
|
||||
|
||||
class Javbus(Parser):
|
||||
|
||||
source = 'javbus'
|
||||
|
||||
expr_number = '/html/head/meta[@name="keywords"]/@content'
|
||||
expr_title = '/html/head/title/text()'
|
||||
expr_studio = '//span[contains(text(),"製作商:")]/../a/text()'
|
||||
expr_studio2 = '//span[contains(text(),"メーカー:")]/../a/text()'
|
||||
expr_director = '//span[contains(text(),"導演:")]/../a/text()'
|
||||
expr_directorJa = '//span[contains(text(),"監督:")]/../a/text()'
|
||||
expr_series = '//span[contains(text(),"系列:")]/../a/text()'
|
||||
expr_series2 = '//span[contains(text(),"シリーズ:")]/../a/text()'
|
||||
expr_label = '//span[contains(text(),"系列:")]/../a/text()'
|
||||
expr_cover = '//a[@class="bigImage"]/@href'
|
||||
expr_release = '/html/body/div[5]/div[1]/div[2]/p[2]/text()'
|
||||
expr_runtime = '/html/body/div[5]/div[1]/div[2]/p[3]/text()'
|
||||
expr_actor = '//div[@class="star-name"]/a'
|
||||
expr_actorphoto = '//div[@class="star-name"]/../a/img'
|
||||
expr_extrafanart = '//div[@id="sample-waterfall"]/a/@href'
|
||||
expr_tags = '/html/head/meta[@name="keywords"]/@content'
|
||||
expr_uncensored = '//*[@id="navbar"]/ul[1]/li[@class="active"]/a[contains(@href,"uncensored")]'
|
||||
|
||||
def search(self, number):
|
||||
self.number = number
|
||||
try:
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
htmltree = self.getHtmlTree(self.detailurl)
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
try:
|
||||
self.detailurl = 'https://www.javbus.com/' + number
|
||||
self.htmlcode = self.getHtml(self.detailurl)
|
||||
except:
|
||||
mirror_url = "https://www." + secrets.choice([
|
||||
'buscdn.fun', 'busdmm.fun', 'busfan.fun', 'busjav.fun',
|
||||
'cdnbus.fun',
|
||||
'dmmbus.fun', 'dmmsee.fun',
|
||||
'seedmm.fun',
|
||||
]) + "/"
|
||||
self.detailurl = mirror_url + number
|
||||
self.htmlcode = self.getHtml(self.detailurl)
|
||||
if self.htmlcode == 404:
|
||||
return 404
|
||||
htmltree = etree.fromstring(self.htmlcode,etree.HTMLParser())
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
except:
|
||||
self.searchUncensored(number)
|
||||
|
||||
def searchUncensored(self, number):
|
||||
""" 二次搜索无码
|
||||
"""
|
||||
self.imagecut = 0
|
||||
self.uncensored = True
|
||||
|
||||
w_number = number.replace('.', '-')
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = 'https://www.javbus.red/' + w_number
|
||||
self.htmlcode = self.getHtml(self.detailurl)
|
||||
if self.htmlcode == 404:
|
||||
return 404
|
||||
htmltree = etree.fromstring(self.htmlcode, etree.HTMLParser())
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getNum(self, htmltree):
|
||||
return super().getNum(htmltree).split(',')[0]
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
title = super().getTitle(htmltree)
|
||||
title = str(re.findall('^.+?\s+(.*) - JavBus$', title)[0]).strip()
|
||||
return title
|
||||
|
||||
def getStudio(self, htmltree):
|
||||
if self.uncensored:
|
||||
return self.getTreeElement(htmltree, self.expr_studio2)
|
||||
else:
|
||||
return self.getTreeElement(htmltree, self.expr_studio)
|
||||
|
||||
def getCover(self, htmltree):
|
||||
return urljoin("https://www.javbus.com", super().getCover(htmltree))
|
||||
|
||||
def getRuntime(self, htmltree):
|
||||
return super().getRuntime(htmltree).strip(" ['']分鐘")
|
||||
|
||||
def getActors(self, htmltree):
|
||||
actors = super().getActors(htmltree)
|
||||
b=[]
|
||||
for i in actors:
|
||||
b.append(i.attrib['title'])
|
||||
return b
|
||||
|
||||
def getActorPhoto(self, htmltree):
|
||||
actors = self.getTreeAll(htmltree, self.expr_actorphoto)
|
||||
d = {}
|
||||
for i in actors:
|
||||
p = i.attrib['src']
|
||||
if "nowprinting.gif" in p:
|
||||
continue
|
||||
t = i.attrib['title']
|
||||
d[t] = urljoin("https://www.javbus.com", p)
|
||||
return d
|
||||
|
||||
def getDirector(self, htmltree):
|
||||
if self.uncensored:
|
||||
return self.getTreeElement(htmltree, self.expr_directorJa)
|
||||
else:
|
||||
return self.getTreeElement(htmltree, self.expr_director)
|
||||
|
||||
def getSeries(self, htmltree):
|
||||
if self.uncensored:
|
||||
return self.getTreeElement(htmltree, self.expr_series2)
|
||||
else:
|
||||
return self.getTreeElement(htmltree, self.expr_series)
|
||||
|
||||
def getTags(self, htmltree):
|
||||
tags = self.getTreeElement(htmltree, self.expr_tags).split(',')
|
||||
return tags[2:]
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
if self.morestoryline:
|
||||
if any(caller for caller in inspect.stack() if os.path.basename(caller.filename) == 'airav.py'):
|
||||
return '' # 从airav.py过来的调用不计算outline直接返回,避免重复抓取数据拖慢处理速度
|
||||
from .storyline import getStoryline
|
||||
return getStoryline(self.number , uncensored = self.uncensored,
|
||||
proxies=self.proxies, verify=self.verify)
|
||||
return ''
|
||||
46
scrapinglib/javday.py
Normal file
@@ -0,0 +1,46 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from lxml import etree
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Javday(Parser):
|
||||
source = 'javday'
|
||||
|
||||
expr_url = '/html/head/meta[@property="og:url"]/@content'
|
||||
expr_cover = '/html/head/meta[@property="og:image"]/@content'
|
||||
expr_tags = '/html/head/meta[@name="keywords"]/@content'
|
||||
expr_title = "/html/head/title/text()"
|
||||
expr_actor = "//span[@class='vod_actor']/a/text()"
|
||||
expr_studio = '//span[@class="producer"]/a/text()'
|
||||
expr_number = '//span[@class="jpnum"]/text()'
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 4
|
||||
self.uncensored = True
|
||||
|
||||
def search(self, number):
|
||||
self.number = number.strip().upper()
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = "https://javday.tv/videos/" + self.number.replace("-","") + "/"
|
||||
self.htmlcode = self.getHtml(self.detailurl)
|
||||
if self.htmlcode == 404:
|
||||
return 404
|
||||
htmltree = etree.fromstring(self.htmlcode, etree.HTMLParser())
|
||||
self.detailurl = self.getTreeElement(htmltree, self.expr_url)
|
||||
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
title = super().getTitle(htmltree)
|
||||
# 删除番号和网站名
|
||||
result = title.replace(self.number,"").replace("- JAVDAY.TV","").strip()
|
||||
return result
|
||||
|
||||
def getTags(self, htmltree) -> list:
|
||||
tags = super().getTags(htmltree)
|
||||
return [tag for tag in tags if 'JAVDAY.TV' not in tag]
|
||||
|
||||
242
scrapinglib/javdb.py
Normal file
@@ -0,0 +1,242 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from urllib.parse import urljoin
|
||||
from lxml import etree
|
||||
from .httprequest import request_session
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Javdb(Parser):
|
||||
source = 'javdb'
|
||||
|
||||
expr_number = '//strong[contains(text(),"番號")]/../span/text()'
|
||||
expr_number2 = '//strong[contains(text(),"番號")]/../span/a/text()'
|
||||
expr_title = "/html/head/title/text()"
|
||||
expr_title_no = '//*[contains(@class,"movie-list")]/div/a/div[contains(@class, "video-title")]/text()'
|
||||
expr_runtime = '//strong[contains(text(),"時長")]/../span/text()'
|
||||
expr_runtime2 = '//strong[contains(text(),"時長")]/../span/a/text()'
|
||||
expr_uncensored = '//strong[contains(text(),"類別")]/../span/a[contains(@href,"/tags/uncensored?") or contains(@href,"/tags/western?")]'
|
||||
expr_actor = '//span[@class="value"]/a[contains(@href,"/actors/")]/text()'
|
||||
expr_actor2 = '//span[@class="value"]/a[contains(@href,"/actors/")]/../strong/@class'
|
||||
expr_release = '//strong[contains(text(),"日期")]/../span/text()'
|
||||
expr_release_no = '//*[contains(@class,"movie-list")]/div/a/div[contains(@class, "meta")]/text()'
|
||||
expr_studio = '//strong[contains(text(),"片商")]/../span/a/text()'
|
||||
expr_studio2 = '//strong[contains(text(),"賣家:")]/../span/a/text()'
|
||||
expr_director = '//strong[contains(text(),"導演")]/../span/text()'
|
||||
expr_director2 = '//strong[contains(text(),"導演")]/../span/a/text()'
|
||||
expr_cover = "//div[contains(@class, 'column-video-cover')]/a/img/@src"
|
||||
expr_cover2 = "//div[contains(@class, 'column-video-cover')]/img/@src"
|
||||
expr_cover_no = '//*[contains(@class,"movie-list")]/div/a/div[contains(@class, "cover")]/img/@src'
|
||||
expr_trailer = '//span[contains(text(),"預告片")]/../../video/source/@src'
|
||||
expr_extrafanart = "//article[@class='message video-panel']/div[@class='message-body']/div[@class='tile-images preview-images']/a[contains(@href,'/samples/')]/@href"
|
||||
expr_tags = '//strong[contains(text(),"類別")]/../span/a/text()'
|
||||
expr_tags2 = '//strong[contains(text(),"類別")]/../span/text()'
|
||||
expr_series = '//strong[contains(text(),"系列")]/../span/text()'
|
||||
expr_series2 = '//strong[contains(text(),"系列")]/../span/a/text()'
|
||||
expr_label = '//strong[contains(text(),"系列")]/../span/text()'
|
||||
expr_label2 = '//strong[contains(text(),"系列")]/../span/a/text()'
|
||||
expr_userrating = '//span[@class="score-stars"]/../text()'
|
||||
expr_uservotes = '//span[@class="score-stars"]/../text()'
|
||||
expr_actorphoto = '//strong[contains(text(),"演員:")]/../span/a[starts-with(@href,"/actors/")]'
|
||||
|
||||
def extraInit(self):
|
||||
self.fixstudio = False
|
||||
self.noauth = False
|
||||
|
||||
def updateCore(self, core):
|
||||
if core.proxies:
|
||||
self.proxies = core.proxies
|
||||
if core.verify:
|
||||
self.verify = core.verify
|
||||
if core.morestoryline:
|
||||
self.morestoryline = True
|
||||
if core.specifiedSource == self.source:
|
||||
self.specifiedUrl = core.specifiedUrl
|
||||
# special
|
||||
if core.dbcookies:
|
||||
self.cookies = core.dbcookies
|
||||
else:
|
||||
self.cookies = {'over18':'1', 'theme':'auto', 'locale':'zh'}
|
||||
if core.dbsite:
|
||||
self.dbsite = core.dbsite
|
||||
else:
|
||||
self.dbsite = 'javdb'
|
||||
|
||||
def search(self, number: str):
|
||||
self.number = number
|
||||
self.session = request_session(cookies=self.cookies, proxies=self.proxies, verify=self.verify)
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = self.queryNumberUrl(number)
|
||||
self.deatilpage = self.session.get(self.detailurl).text
|
||||
if '此內容需要登入才能查看或操作' in self.deatilpage or '需要VIP權限才能訪問此內容' in self.deatilpage:
|
||||
self.noauth = True
|
||||
self.imagecut = 0
|
||||
result = self.dictformat(self.querytree)
|
||||
else:
|
||||
htmltree = etree.fromstring(self.deatilpage, etree.HTMLParser())
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def queryNumberUrl(self, number):
|
||||
javdb_url = 'https://' + self.dbsite + '.com/search?q=' + number + '&f=all'
|
||||
try:
|
||||
resp = self.session.get(javdb_url)
|
||||
except Exception as e:
|
||||
#print(e)
|
||||
raise Exception(f'[!] {self.number}: page not fond in javdb')
|
||||
|
||||
self.querytree = etree.fromstring(resp.text, etree.HTMLParser())
|
||||
# javdb sometime returns multiple results,
|
||||
# and the first elememt maybe not the one we are looking for
|
||||
# iterate all candidates and find the match one
|
||||
urls = self.getTreeAll(self.querytree, '//*[contains(@class,"movie-list")]/div/a/@href')
|
||||
# 记录一下欧美的ids ['Blacked','Blacked']
|
||||
if re.search(r'[a-zA-Z]+\.\d{2}\.\d{2}\.\d{2}', number):
|
||||
correct_url = urls[0]
|
||||
else:
|
||||
ids = self.getTreeAll(self.querytree, '//*[contains(@class,"movie-list")]/div/a/div[contains(@class, "video-title")]/strong/text()')
|
||||
try:
|
||||
self.queryid = ids.index(number)
|
||||
correct_url = urls[self.queryid]
|
||||
except:
|
||||
# 为避免获得错误番号,只要精确对应的结果
|
||||
if ids[0].upper() != number.upper():
|
||||
raise ValueError("number not found in javdb")
|
||||
correct_url = urls[0]
|
||||
return urljoin(resp.url, correct_url)
|
||||
|
||||
def getNum(self, htmltree):
|
||||
if self.noauth:
|
||||
return self.number
|
||||
# 番号被分割开,需要合并后才是完整番号
|
||||
part1 = self.getTreeElement(htmltree, self.expr_number)
|
||||
part2 = self.getTreeElement(htmltree, self.expr_number2)
|
||||
dp_number = part2 + part1
|
||||
# NOTE 检测匹配与更新 self.number
|
||||
if dp_number.upper() != self.number.upper():
|
||||
raise Exception(f'[!] {self.number}: find [{dp_number}] in javdb, not match')
|
||||
self.number = dp_number
|
||||
return self.number
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
if self.noauth:
|
||||
return self.getTreeElement(htmltree, self.expr_title_no, self.queryid)
|
||||
browser_title = super().getTitle(htmltree)
|
||||
title = browser_title[:browser_title.find(' | JavDB')].strip()
|
||||
return title.replace(self.number, '').strip()
|
||||
|
||||
def getCover(self, htmltree):
|
||||
if self.noauth:
|
||||
return self.getTreeElement(htmltree, self.expr_cover_no, self.queryid)
|
||||
return super().getCover(htmltree)
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
if self.noauth:
|
||||
return self.getTreeElement(htmltree, self.expr_release_no, self.queryid).strip()
|
||||
return super().getRelease(htmltree)
|
||||
|
||||
def getDirector(self, htmltree):
|
||||
return self.getTreeElementbyExprs(htmltree, self.expr_director, self.expr_director2)
|
||||
|
||||
def getSeries(self, htmltree):
|
||||
# NOTE 不清楚javdb是否有一部影片多个series的情况,暂时保留
|
||||
results = self.getTreeAllbyExprs(htmltree, self.expr_series, self.expr_series2)
|
||||
result = ''.join(results)
|
||||
if not result and self.fixstudio:
|
||||
result = self.getStudio(htmltree)
|
||||
return result
|
||||
|
||||
def getLabel(self, htmltree):
|
||||
results = self.getTreeAllbyExprs(htmltree, self.expr_label, self.expr_label2)
|
||||
result = ''.join(results)
|
||||
if not result and self.fixstudio:
|
||||
result = self.getStudio(htmltree)
|
||||
return result
|
||||
|
||||
def getActors(self, htmltree):
|
||||
actors = self.getTreeAll(htmltree, self.expr_actor)
|
||||
genders = self.getTreeAll(htmltree, self.expr_actor2)
|
||||
r = []
|
||||
idx = 0
|
||||
# NOTE only female, we dont care others
|
||||
actor_gendor = 'female'
|
||||
for act in actors:
|
||||
if((actor_gendor == 'all')
|
||||
or (actor_gendor == 'both' and genders[idx] in ['symbol female', 'symbol male'])
|
||||
or (actor_gendor == 'female' and genders[idx] == 'symbol female')
|
||||
or (actor_gendor == 'male' and genders[idx] == 'symbol male')):
|
||||
r.append(act)
|
||||
idx = idx + 1
|
||||
if re.match(r'FC2-[\d]+', self.number, re.A) and not r:
|
||||
r = '素人'
|
||||
self.fixstudio = True
|
||||
return r
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
if self.morestoryline:
|
||||
from .storyline import getStoryline
|
||||
return getStoryline(self.number, self.getUncensored(htmltree),
|
||||
proxies=self.proxies, verify=self.verify)
|
||||
return ''
|
||||
|
||||
def getTrailer(self, htmltree):
|
||||
video = super().getTrailer(htmltree)
|
||||
# 加上数组判空
|
||||
if video:
|
||||
if not 'https:' in video:
|
||||
video_url = 'https:' + video
|
||||
else:
|
||||
video_url = video
|
||||
else:
|
||||
video_url = ''
|
||||
return video_url
|
||||
|
||||
def getTags(self, htmltree):
|
||||
return self.getTreeAllbyExprs(htmltree, self.expr_tags, self.expr_tags2)
|
||||
|
||||
def getUserRating(self, htmltree):
|
||||
try:
|
||||
numstrs = self.getTreeElement(htmltree, self.expr_userrating)
|
||||
nums = re.findall('[0-9.]+', numstrs)
|
||||
return float(nums[0])
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getUserVotes(self, htmltree):
|
||||
try:
|
||||
result = self.getTreeElement(htmltree, self.expr_uservotes)
|
||||
v = re.findall('[0-9.]+', result)
|
||||
return int(v[1])
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getaphoto(self, url, session):
|
||||
html_page = session.get(url).text
|
||||
img_url = re.findall(r'<span class\=\"avatar\" style\=\"background\-image\: url\((.*?)\)', html_page)
|
||||
return img_url[0] if img_url else ''
|
||||
|
||||
def getActorPhoto(self, htmltree):
|
||||
actorall = self.getTreeAll(htmltree, self.expr_actorphoto)
|
||||
if not actorall:
|
||||
return {}
|
||||
actors = self.getActors(htmltree)
|
||||
actor_photo = {}
|
||||
for i in actorall:
|
||||
x = re.findall(r'/actors/(.*)', i.attrib['href'], re.A)
|
||||
if not len(x) or not len(x[0]) or i.text not in actors:
|
||||
continue
|
||||
# NOTE: https://c1.jdbstatic.com 会经常变动,直接使用页面内的地址获取
|
||||
# actor_id = x[0]
|
||||
# pic_url = f"https://c1.jdbstatic.com/avatars/{actor_id[:2].lower()}/{actor_id}.jpg"
|
||||
# if not self.session.head(pic_url).ok:
|
||||
try:
|
||||
pic_url = self.getaphoto(urljoin('https://javdb.com', i.attrib['href']), self.session)
|
||||
if len(pic_url):
|
||||
actor_photo[i.text] = pic_url
|
||||
except:
|
||||
pass
|
||||
return actor_photo
|
||||
|
||||
84
scrapinglib/javlibrary.py
Normal file
@@ -0,0 +1,84 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from lxml import etree
|
||||
from .httprequest import request_session
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Javlibrary(Parser):
|
||||
source = 'javlibrary'
|
||||
|
||||
expr_number = '//div[@id="video_id"]/table/tr/td[@class="text"]/text()'
|
||||
expr_title = '//div[@id="video_title"]/h3/a/text()'
|
||||
expr_actor = '//div[@id="video_cast"]/table/tr/td[@class="text"]/span/span[@class="star"]/a/text()'
|
||||
expr_tags = '//div[@id="video_genres"]/table/tr/td[@class="text"]/span/a/text()'
|
||||
expr_cover = '//img[@id="video_jacket_img"]/@src'
|
||||
expr_release = '//div[@id="video_date"]/table/tr/td[@class="text"]/text()'
|
||||
expr_studio = '//div[@id="video_maker"]/table/tr/td[@class="text"]/span/a/text()'
|
||||
expr_runtime = '//div[@id="video_length"]/table/tr/td/span[@class="text"]/text()'
|
||||
expr_userrating = '//div[@id="video_review"]/table/tr/td/span[@class="score"]/text()'
|
||||
expr_director = '//div[@id="video_director"]/table/tr/td[@class="text"]/span/a/text()'
|
||||
expr_extrafanart = '//div[@class="previewthumbs"]/img/@src'
|
||||
|
||||
def extraInit(self):
|
||||
self.htmltree = None
|
||||
|
||||
def updateCore(self, core):
|
||||
if core.proxies:
|
||||
self.proxies = core.proxies
|
||||
if core.verify:
|
||||
self.verify = core.verify
|
||||
if core.morestoryline:
|
||||
self.morestoryline = True
|
||||
if core.specifiedSource == self.source:
|
||||
self.specifiedUrl = core.specifiedUrl
|
||||
self.cookies = {'over18':'1'}
|
||||
|
||||
def search(self, number):
|
||||
self.number = number.upper()
|
||||
self.session = request_session(cookies=self.cookies, proxies=self.proxies, verify=self.verify)
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = self.queryNumberUrl(self.number)
|
||||
if not self.detailurl:
|
||||
return 404
|
||||
if self.htmltree is None:
|
||||
deatils = self.session.get(self.detailurl)
|
||||
self.htmltree = etree.fromstring(deatils.text, etree.HTMLParser())
|
||||
result = self.dictformat(self.htmltree)
|
||||
return result
|
||||
|
||||
def queryNumberUrl(self, number:str):
|
||||
queryUrl = "http://www.javlibrary.com/cn/vl_searchbyid.php?keyword=" + number
|
||||
queryResult = self.session.get(queryUrl)
|
||||
|
||||
if queryResult and "/?v=jav" in queryResult.url:
|
||||
self.htmltree = etree.fromstring(queryResult.text, etree.HTMLParser())
|
||||
return queryResult.url
|
||||
else:
|
||||
queryTree = etree.fromstring(queryResult.text, etree.HTMLParser())
|
||||
numbers = queryTree.xpath('//div[@class="id"]/text()')
|
||||
if number in numbers:
|
||||
urls = queryTree.xpath('//div[@class="id"]/../@href')
|
||||
detailurl = urls[numbers.index(number)]
|
||||
return "http://www.javlibrary.com/cn" + detailurl.strip('.')
|
||||
return None
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
title = super().getTitle(htmltree)
|
||||
title = title.replace(self.getNum(htmltree), '').strip()
|
||||
return title
|
||||
|
||||
def getCover(self, htmltree):
|
||||
url = super().getCover(htmltree)
|
||||
if not url.startswith('http'):
|
||||
url = 'https:' + url
|
||||
return url
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
if self.morestoryline:
|
||||
from .storyline import getStoryline
|
||||
return getStoryline(self.number, self.getUncensored(htmltree),
|
||||
proxies=self.proxies, verify=self.verify)
|
||||
return ''
|
||||
61
scrapinglib/javmenu.py
Normal file
@@ -0,0 +1,61 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from lxml import etree
|
||||
from urllib.parse import urljoin
|
||||
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Javmenu(Parser):
|
||||
source = 'javmenu'
|
||||
|
||||
expr_title = '/html/head/meta[@property="og:title"]/@content'
|
||||
expr_cover = '/html/head/meta[@property="og:image"]/@content'
|
||||
|
||||
expr_number = '//span[contains(text(),"番號") or contains(text(),"番号")]/../a/text()'
|
||||
expr_number2 = '//span[contains(text(),"番號") or contains(text(),"番号")]/../span[2]/text()'
|
||||
expr_runtime = '//span[contains(text(),"時長;") or contains(text(),"时长")]/../span[2]/text()'
|
||||
expr_release = '//span[contains(text(),"日期")]/../span[2]/text()'
|
||||
expr_studio = '//span[contains(text(),"製作")]/../span[2]/a/text()'
|
||||
|
||||
expr_actor = '//a[contains(@class,"actress")]/text()'
|
||||
expr_tags = '//a[contains(@class,"genre")]/text()'
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 4
|
||||
self.uncensored = True
|
||||
|
||||
def search(self, number):
|
||||
self.number = number
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = 'https://javmenu.com/zh/' + self.number + '/'
|
||||
self.htmlcode = self.getHtml(self.detailurl)
|
||||
if self.htmlcode == 404:
|
||||
return 404
|
||||
htmltree = etree.HTML(self.htmlcode)
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getNum(self, htmltree):
|
||||
# 番号被分割开,需要合并后才是完整番号
|
||||
part1 = self.getTreeElement(htmltree, self.expr_number)
|
||||
part2 = self.getTreeElement(htmltree, self.expr_number2)
|
||||
dp_number = part1 + part2
|
||||
# NOTE 检测匹配与更新 self.number
|
||||
if dp_number.upper() != self.number.upper():
|
||||
raise Exception(f'[!] {self.number}: find [{dp_number}] in javmenu, not match')
|
||||
self.number = dp_number
|
||||
return self.number
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
browser_title = super().getTitle(htmltree)
|
||||
# 删除番号
|
||||
number = re.findall("\d+",self.number)[1]
|
||||
title = browser_title.split(number,1)[-1]
|
||||
title = title.replace(' | JAV目錄大全 | 每日更新',"")
|
||||
title = title.replace(' | JAV目录大全 | 每日更新',"").strip()
|
||||
return title.replace(self.number, '').strip()
|
||||
|
||||
94
scrapinglib/madou.py
Normal file
@@ -0,0 +1,94 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from lxml import etree
|
||||
from urllib.parse import urlparse, unquote
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
NUM_RULES3=[
|
||||
r'(mmz{2,4})-?(\d{2,})(-ep\d*|-\d*)?.*',
|
||||
r'(msd)-?(\d{2,})(-ep\d*|-\d*)?.*',
|
||||
r'(yk)-?(\d{2,})(-ep\d*|-\d*)?.*',
|
||||
r'(pm)-?(\d{2,})(-ep\d*|-\d*)?.*',
|
||||
r'(mky-[a-z]{2,2})-?(\d{2,})(-ep\d*|-\d*)?.*',
|
||||
]
|
||||
|
||||
# modou提取number
|
||||
def change_number(number):
|
||||
number = number.lower().strip()
|
||||
m = re.search(r'(md[a-z]{0,2})-?(\d{2,})(-ep\d*|-\d*)?.*', number, re.I)
|
||||
if m:
|
||||
return f'{m.group(1)}{m.group(2).zfill(4)}{m.group(3) or ""}'
|
||||
for rules in NUM_RULES3:
|
||||
m = re.search(rules, number, re.I)
|
||||
if m:
|
||||
return f'{m.group(1)}{m.group(2).zfill(3)}{m.group(3) or ""}'
|
||||
return number
|
||||
|
||||
|
||||
|
||||
class Madou(Parser):
|
||||
source = 'madou'
|
||||
|
||||
expr_url = '//a[@class="share-weixin"]/@data-url'
|
||||
expr_title = "/html/head/title/text()"
|
||||
expr_studio = '//a[@rel="category tag"]/text()'
|
||||
expr_tags = '/html/head/meta[@name="keywords"]/@content'
|
||||
|
||||
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 4
|
||||
self.uncensored = True
|
||||
self.allow_number_change = True
|
||||
|
||||
def search(self, number):
|
||||
self.number = change_number(number)
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = "https://madou.club/" + number + ".html"
|
||||
self.htmlcode = self.getHtml(self.detailurl)
|
||||
if self.htmlcode == 404:
|
||||
return 404
|
||||
htmltree = etree.fromstring(self.htmlcode, etree.HTMLParser())
|
||||
self.detailurl = self.getTreeElement(htmltree, self.expr_url)
|
||||
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getNum(self, htmltree):
|
||||
try:
|
||||
# 解码url
|
||||
filename = unquote(urlparse(self.detailurl).path)
|
||||
# 裁剪文件名
|
||||
result = filename[1:-5].upper().strip()
|
||||
# 移除中文
|
||||
if result.upper() != self.number.upper():
|
||||
result = re.split(r'[^\x00-\x7F]+', result, 1)[0]
|
||||
# 移除多余的符号
|
||||
return result.strip('-')
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
# <title>MD0140-2 / 家有性事EP2 爱在身边-麻豆社</title>
|
||||
# <title>MAD039 机灵可爱小叫花 强诱僧人迫犯色戒-麻豆社</title>
|
||||
# <title>MD0094/贫嘴贱舌中出大嫂/坏嫂嫂和小叔偷腥内射受孕-麻豆社</title>
|
||||
# <title>TM0002-我的痴女女友-麻豆社</title>
|
||||
browser_title = str(super().getTitle(htmltree))
|
||||
title = str(re.findall(r'^[A-Z0-9 //\-]*(.*)-麻豆社$', browser_title)[0]).strip()
|
||||
return title
|
||||
|
||||
def getCover(self, htmltree):
|
||||
try:
|
||||
url = str(re.findall("shareimage : '(.*?)'", self.htmlcode)[0])
|
||||
return url.strip()
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getTags(self, htmltree):
|
||||
studio = self.getStudio(htmltree)
|
||||
tags = super().getTags(htmltree)
|
||||
return [tag for tag in tags if studio not in tag and '麻豆' not in tag]
|
||||
55
scrapinglib/mgstage.py
Normal file
@@ -0,0 +1,55 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Mgstage(Parser):
|
||||
source = 'mgstage'
|
||||
|
||||
expr_number = '//th[contains(text(),"品番:")]/../td/a/text()'
|
||||
expr_title = '//*[@id="center_column"]/div[1]/h1/text()'
|
||||
expr_studio = '//th[contains(text(),"メーカー:")]/../td/a/text()'
|
||||
expr_outline = '//dl[@id="introduction"]/dd/p/text()'
|
||||
expr_runtime = '//th[contains(text(),"収録時間:")]/../td/a/text()'
|
||||
expr_director = '//th[contains(text(),"シリーズ")]/../td/a/text()'
|
||||
expr_actor = '//th[contains(text(),"出演:")]/../td/a/text()'
|
||||
expr_release = '//th[contains(text(),"配信開始日:")]/../td/a/text()'
|
||||
expr_cover = '//*[@id="EnlargeImage"]/@href'
|
||||
expr_label = '//th[contains(text(),"レーベル:")]/../td/a/text()'
|
||||
expr_tags = '//th[contains(text(),"ジャンル:")]/../td/a/text()'
|
||||
expr_tags2 = '//th[contains(text(),"ジャンル:")]/../td/text()'
|
||||
expr_series = '//th[contains(text(),"シリーズ")]/../td/a/text()'
|
||||
expr_extrafanart = '//a[@class="sample_image"]/@href'
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 4
|
||||
|
||||
def search(self, number):
|
||||
self.number = number.upper()
|
||||
self.cookies = {'adc': '1'}
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = 'https://www.mgstage.com/product/product_detail/' + str(self.number) + '/'
|
||||
htmltree = self.getHtmlTree(self.detailurl)
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
return super().getTitle(htmltree).replace('/', ',').strip()
|
||||
|
||||
def getTags(self, htmltree):
|
||||
return self.getTreeAllbyExprs(htmltree, self.expr_tags, self.expr_tags2)
|
||||
|
||||
def getTreeAll(self, tree, expr):
|
||||
alls = super().getTreeAll(tree, expr)
|
||||
return [ x.strip() for x in alls if x.strip()]
|
||||
|
||||
def getTreeElement(self, tree, expr, index=0):
|
||||
if expr == '':
|
||||
return ''
|
||||
result1 = ''.join(self.getTreeAll(tree, expr))
|
||||
result2 = ''.join(self.getTreeAll(tree, expr.replace('td/a/','td/')))
|
||||
if result1 == result2:
|
||||
return result1
|
||||
return result1 + result2
|
||||
70
scrapinglib/msin.py
Normal file
@@ -0,0 +1,70 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from lxml import etree
|
||||
from .httprequest import request_session
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Msin(Parser):
|
||||
source = 'msin'
|
||||
|
||||
expr_number = '//div[@class="mv_fileName"]/text()'
|
||||
expr_title = '//div[@class="mv_title"]/text()'
|
||||
expr_title_unsubscribe = '//div[@class="mv_title unsubscribe"]/text()'
|
||||
expr_studio = '//a[@class="mv_writer"]/text()'
|
||||
expr_director = '//a[@class="mv_writer"]/text()'
|
||||
expr_actor = '//div[contains(text(),"出演者:")]/following-sibling::div[1]/div/div[@class="performer_text"]/a/text()'
|
||||
expr_label = '//a[@class="mv_mfr"]/text()'
|
||||
expr_series = '//a[@class="mv_mfr"]/text()'
|
||||
expr_release = '//a[@class="mv_createDate"]/text()'
|
||||
expr_cover = '//div[@class="movie_top"]/img/@src'
|
||||
expr_tags = '//div[@class="mv_tag"]/label/text()'
|
||||
expr_genres = '//div[@class="mv_genre"]/label/text()'
|
||||
|
||||
# expr_outline = '//p[@class="fo-14"]/text()'
|
||||
# expr_extrafanart = '//*[@class="item-nav"]/ul/li/a/img/@src'
|
||||
# expr_extrafanart2 = '//*[@id="cart_quantity"]/table/tr[3]/td/div/a/img/@src'
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 4
|
||||
|
||||
def search(self, number: str):
|
||||
self.number = number.lower().replace('fc2-ppv-', '').replace('fc2-', '')
|
||||
self.cookies = {"age": "off"}
|
||||
self.detailurl = 'https://db.msin.jp/search/movie?str=fc2-ppv-' + self.number
|
||||
session = request_session(cookies=self.cookies, proxies=self.proxies, verify=self.verify)
|
||||
htmlcode = session.get(self.detailurl).text
|
||||
htmltree = etree.HTML(htmlcode)
|
||||
# if title are null, use unsubscribe title
|
||||
if super().getTitle(htmltree) == "":
|
||||
self.expr_title = self.expr_title_unsubscribe
|
||||
# if tags are null, use genres
|
||||
if len(super().getTags(htmltree)) == 0:
|
||||
self.expr_tags = self.expr_genres
|
||||
if len(super().getActors(htmltree)) == 0:
|
||||
self.expr_actor = self.expr_director
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getActors(self, htmltree):
|
||||
actors = super().getActors(htmltree)
|
||||
i = 0
|
||||
while i < len(actors):
|
||||
actors[i] = actors[i].replace("(FC2動画)", "")
|
||||
i = i + 1
|
||||
return actors
|
||||
|
||||
def getTags(self, htmltree) -> list:
|
||||
return super().getTags(htmltree)
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
return super().getRelease(htmltree).replace('年', '-').replace('月', '-').replace('日', '')
|
||||
|
||||
def getCover(self, htmltree):
|
||||
if ".gif" in super().getCover(htmltree) and len(super().getExtrafanart(htmltree)) != 0:
|
||||
return super().getExtrafanart(htmltree)[0]
|
||||
return super().getCover(htmltree)
|
||||
|
||||
def getNum(self, htmltree):
|
||||
return 'FC2-' + self.number
|
||||
323
scrapinglib/parser.py
Normal file
@@ -0,0 +1,323 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import json
|
||||
import re
|
||||
from lxml import etree, html
|
||||
|
||||
import config
|
||||
from . import httprequest
|
||||
from .utils import getTreeElement, getTreeAll
|
||||
|
||||
class Parser:
|
||||
""" 基础刮削类
|
||||
"""
|
||||
source = 'base'
|
||||
# xpath expr
|
||||
expr_number = ''
|
||||
expr_title = ''
|
||||
expr_studio = ''
|
||||
expr_studio2 = ''
|
||||
expr_runtime = ''
|
||||
expr_runtime2 = ''
|
||||
expr_release = ''
|
||||
expr_outline = ''
|
||||
expr_director = ''
|
||||
expr_actor = ''
|
||||
expr_tags = ''
|
||||
expr_label = ''
|
||||
expr_label2 = ''
|
||||
expr_series = ''
|
||||
expr_series2 = ''
|
||||
expr_cover = ''
|
||||
expr_cover2 = ''
|
||||
expr_smallcover = ''
|
||||
expr_extrafanart = ''
|
||||
expr_trailer = ''
|
||||
expr_actorphoto = ''
|
||||
expr_uncensored = ''
|
||||
expr_userrating = ''
|
||||
expr_uservotes = ''
|
||||
|
||||
def init(self):
|
||||
""" 初始化参数
|
||||
"""
|
||||
# 推荐剪切poster封面:
|
||||
# `0` 复制cover
|
||||
# `1` 裁剪cover
|
||||
# `3` 下载小封面
|
||||
self.imagecut = 1
|
||||
self.uncensored = False
|
||||
self.allow_number_change = False
|
||||
# update
|
||||
self.proxies = None
|
||||
self.verify = None
|
||||
self.extraheader = None
|
||||
self.cookies = None
|
||||
self.morestoryline = False
|
||||
self.specifiedUrl = None
|
||||
self.extraInit()
|
||||
|
||||
def extraInit(self):
|
||||
""" 自定义初始化内容
|
||||
"""
|
||||
pass
|
||||
|
||||
def scrape(self, number, core: None):
|
||||
""" 刮削番号
|
||||
"""
|
||||
# 每次调用,初始化参数
|
||||
self.init()
|
||||
self.updateCore(core)
|
||||
result = self.search(number)
|
||||
return result
|
||||
|
||||
def search(self, number):
|
||||
""" 查询番号
|
||||
|
||||
查询主要流程:
|
||||
1. 获取 url
|
||||
2. 获取详情页面
|
||||
3. 解析
|
||||
4. 返回 result
|
||||
"""
|
||||
self.number = number
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
self.detailurl = self.queryNumberUrl(number)
|
||||
if not self.detailurl:
|
||||
return 404
|
||||
htmltree = self.getHtmlTree(self.detailurl)
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def updateCore(self, core):
|
||||
""" 从`core`内更新参数
|
||||
|
||||
针对需要传递的参数: cookies, proxy等
|
||||
子类继承后修改
|
||||
"""
|
||||
if not core:
|
||||
return
|
||||
if core.proxies:
|
||||
self.proxies = core.proxies
|
||||
if core.verify:
|
||||
self.verify = core.verify
|
||||
if core.morestoryline:
|
||||
self.morestoryline = True
|
||||
if core.specifiedSource == self.source:
|
||||
self.specifiedUrl = core.specifiedUrl
|
||||
|
||||
def queryNumberUrl(self, number):
|
||||
""" 根据番号查询详细信息url
|
||||
|
||||
需要针对不同站点修改,或者在上层直接获取
|
||||
备份查询页面,预览图可能需要
|
||||
"""
|
||||
url = "http://detailurl.ai/" + number
|
||||
return url
|
||||
|
||||
def getHtml(self, url, type = None):
|
||||
""" 访问网页
|
||||
"""
|
||||
resp = httprequest.get(url, cookies=self.cookies, proxies=self.proxies, extra_headers=self.extraheader, verify=self.verify, return_type=type)
|
||||
if '<title>404 Page Not Found' in resp \
|
||||
or '<title>未找到页面' in resp \
|
||||
or '404 Not Found' in resp \
|
||||
or '<title>404' in resp \
|
||||
or '<title>お探しの商品が見つかりません' in resp:
|
||||
return 404
|
||||
return resp
|
||||
|
||||
def getHtmlTree(self, url, type = None):
|
||||
""" 访问网页,返回`etree`
|
||||
"""
|
||||
resp = self.getHtml(url, type)
|
||||
if resp == 404:
|
||||
return 404
|
||||
ret = etree.fromstring(resp, etree.HTMLParser())
|
||||
return ret
|
||||
|
||||
def dictformat(self, htmltree):
|
||||
try:
|
||||
dic = {
|
||||
'number': self.getNum(htmltree),
|
||||
'title': self.getTitle(htmltree),
|
||||
'studio': self.getStudio(htmltree),
|
||||
'release': self.getRelease(htmltree),
|
||||
'year': self.getYear(htmltree),
|
||||
'outline': self.getOutline(htmltree),
|
||||
'runtime': self.getRuntime(htmltree),
|
||||
'director': self.getDirector(htmltree),
|
||||
'actor': self.getActors(htmltree),
|
||||
'actor_photo': self.getActorPhoto(htmltree),
|
||||
'cover': self.getCover(htmltree),
|
||||
'cover_small': self.getSmallCover(htmltree),
|
||||
'extrafanart': self.getExtrafanart(htmltree),
|
||||
'trailer': self.getTrailer(htmltree),
|
||||
'tag': self.getTags(htmltree),
|
||||
'label': self.getLabel(htmltree),
|
||||
'series': self.getSeries(htmltree),
|
||||
'userrating': self.getUserRating(htmltree),
|
||||
'uservotes': self.getUserVotes(htmltree),
|
||||
'uncensored': self.getUncensored(htmltree),
|
||||
'website': self.detailurl,
|
||||
'source': self.source,
|
||||
'imagecut': self.getImagecut(htmltree),
|
||||
}
|
||||
dic = self.extradict(dic)
|
||||
except Exception as e:
|
||||
if config.getInstance().debug():
|
||||
print(e)
|
||||
dic = {"title": ""}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, separators=(',', ':'))
|
||||
return js
|
||||
|
||||
def extradict(self, dic:dict):
|
||||
""" 额外修改dict
|
||||
"""
|
||||
return dic
|
||||
|
||||
def getNum(self, htmltree):
|
||||
""" 增加 strip 过滤
|
||||
"""
|
||||
return self.getTreeElement(htmltree, self.expr_number)
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
return self.getTreeElement(htmltree, self.expr_title).strip()
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
return self.getTreeElement(htmltree, self.expr_release).strip().replace('/','-')
|
||||
|
||||
def getYear(self, htmltree):
|
||||
""" year基本都是从release中解析的
|
||||
"""
|
||||
try:
|
||||
release = self.getRelease(htmltree)
|
||||
return str(re.findall('\d{4}', release)).strip(" ['']")
|
||||
except:
|
||||
return release
|
||||
|
||||
def getRuntime(self, htmltree):
|
||||
return self.getTreeElementbyExprs(htmltree, self.expr_runtime, self.expr_runtime2).strip().rstrip('mi')
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
return self.getTreeElement(htmltree, self.expr_outline).strip()
|
||||
|
||||
def getDirector(self, htmltree):
|
||||
return self.getTreeElement(htmltree, self.expr_director).strip()
|
||||
|
||||
def getActors(self, htmltree) -> list:
|
||||
return self.getTreeAll(htmltree, self.expr_actor)
|
||||
|
||||
def getTags(self, htmltree) -> list:
|
||||
alls = self.getTreeAll(htmltree, self.expr_tags)
|
||||
tags = []
|
||||
for t in alls:
|
||||
for tag in t.strip().split(','):
|
||||
tag = tag.strip()
|
||||
if tag:
|
||||
tags.append(tag)
|
||||
return tags
|
||||
|
||||
def getStudio(self, htmltree):
|
||||
return self.getTreeElementbyExprs(htmltree, self.expr_studio, self.expr_studio2)
|
||||
|
||||
def getLabel(self, htmltree):
|
||||
return self.getTreeElementbyExprs(htmltree, self.expr_label, self.expr_label2)
|
||||
|
||||
def getSeries(self, htmltree):
|
||||
return self.getTreeElementbyExprs(htmltree, self.expr_series, self.expr_series2)
|
||||
|
||||
def getCover(self, htmltree):
|
||||
return self.getTreeElementbyExprs(htmltree, self.expr_cover, self.expr_cover2)
|
||||
|
||||
def getSmallCover(self, htmltree):
|
||||
return self.getTreeElement(htmltree, self.expr_smallcover)
|
||||
|
||||
def getExtrafanart(self, htmltree) -> list:
|
||||
return self.getTreeAll(htmltree, self.expr_extrafanart)
|
||||
|
||||
def getTrailer(self, htmltree):
|
||||
return self.getTreeElement(htmltree, self.expr_trailer)
|
||||
|
||||
def getActorPhoto(self, htmltree) -> dict:
|
||||
return {}
|
||||
|
||||
def getUncensored(self, htmltree) -> bool:
|
||||
"""
|
||||
tag: 無码 無修正 uncensored 无码
|
||||
title: 無碼 無修正 uncensored
|
||||
"""
|
||||
if self.uncensored:
|
||||
return self.uncensored
|
||||
tags = [x.lower() for x in self.getTags(htmltree) if len(x)]
|
||||
title = self.getTitle(htmltree)
|
||||
if self.expr_uncensored:
|
||||
u = self.getTreeAll(htmltree, self.expr_uncensored)
|
||||
self.uncensored = bool(u)
|
||||
elif '無码' in tags or '無修正' in tags or 'uncensored' in tags or '无码' in tags:
|
||||
self.uncensored = True
|
||||
elif '無码' in title or '無修正' in title or 'uncensored' in title.lower():
|
||||
self.uncensored = True
|
||||
return self.uncensored
|
||||
|
||||
def getImagecut(self, htmltree):
|
||||
""" 修正 无码poster不裁剪cover
|
||||
"""
|
||||
# if self.imagecut == 1 and self.getUncensored(htmltree):
|
||||
# self.imagecut = 0
|
||||
return self.imagecut
|
||||
|
||||
def getUserRating(self, htmltree):
|
||||
numstrs = self.getTreeElement(htmltree, self.expr_userrating)
|
||||
nums = re.findall('[0-9.]+', numstrs)
|
||||
if len(nums) == 1:
|
||||
return float(nums[0])
|
||||
return ''
|
||||
|
||||
def getUserVotes(self, htmltree):
|
||||
votestrs = self.getTreeElement(htmltree, self.expr_uservotes)
|
||||
votes = re.findall('[0-9]+', votestrs)
|
||||
if len(votes) == 1:
|
||||
return int(votes[0])
|
||||
return ''
|
||||
|
||||
def getTreeElement(self, tree: html.HtmlElement, expr, index=0):
|
||||
""" 根据表达式从`xmltree`中获取匹配值,默认 index 为 0
|
||||
"""
|
||||
return getTreeElement(tree, expr, index)
|
||||
|
||||
def getTreeAll(self, tree: html.HtmlElement, expr):
|
||||
""" 根据表达式从`xmltree`中获取全部匹配值
|
||||
"""
|
||||
return getTreeAll(tree, expr)
|
||||
|
||||
def getTreeElementbyExprs(self, tree: html.HtmlElement, expr, expr2=''):
|
||||
""" 多个表达式获取element
|
||||
使用内部的 getTreeElement 防止继承修改后出现问题
|
||||
"""
|
||||
try:
|
||||
first = self.getTreeElement(tree, expr).strip()
|
||||
if first:
|
||||
return first
|
||||
second = self.getTreeElement(tree, expr2).strip()
|
||||
if second:
|
||||
return second
|
||||
return ''
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getTreeAllbyExprs(self, tree: html.HtmlElement, expr, expr2=''):
|
||||
""" 多个表达式获取所有element
|
||||
合并并剔除重复元素
|
||||
"""
|
||||
try:
|
||||
result1 = self.getTreeAll(tree, expr)
|
||||
result2 = self.getTreeAll(tree, expr2)
|
||||
clean = [ x.strip() for x in result1 if x.strip() and x.strip() != ',']
|
||||
clean2 = [ x.strip() for x in result2 if x.strip() and x.strip() != ',']
|
||||
result = list(set(clean + clean2))
|
||||
return result
|
||||
except:
|
||||
return []
|
||||
58
scrapinglib/pcolle.py
Normal file
@@ -0,0 +1,58 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from lxml import etree
|
||||
from .httprequest import request_session
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Pcolle(Parser):
|
||||
source = 'pcolle'
|
||||
|
||||
expr_number = '//th[contains(text(),"商品ID")]/../td/text()'
|
||||
expr_title = '//div[@class="title-04"]/div/text()'
|
||||
expr_studio = '//th[contains(text(),"販売会員")]/../td/a/text()'
|
||||
expr_director = '//th[contains(text(),"販売会員")]/../td/a/text()'
|
||||
expr_actor = '//th[contains(text(),"販売会員")]/../td/a/text()'
|
||||
expr_label = '//th[contains(text(),"カテゴリー")]/../td/ul/li/a/text()'
|
||||
expr_series = '//th[contains(text(),"カテゴリー")]/../td/ul/li/a/text()'
|
||||
expr_release = '//th[contains(text(),"販売開始日")]/../td/text()'
|
||||
expr_cover = '/html/body/div[1]/div/div[4]/div[2]/div/div[1]/div/article/a/img/@src'
|
||||
expr_tags = '//p[contains(text(),"商品タグ")]/../ul/li/a/text()'
|
||||
expr_outline = '//p[@class="fo-14"]/text()'
|
||||
expr_extrafanart = '//*[@class="item-nav"]/ul/li/a/img/@src'
|
||||
|
||||
# expr_extrafanart2 = '//*[@id="cart_quantity"]/table/tr[3]/td/div/a/img/@src'
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 4
|
||||
|
||||
def search(self, number: str):
|
||||
self.number = number.upper().replace('PCOLLE-', '')
|
||||
self.detailurl = 'https://www.pcolle.com/product/detail/?product_id=' + self.number
|
||||
session = request_session(cookies=self.cookies, proxies=self.proxies, verify=self.verify)
|
||||
htmlcode = session.get(self.detailurl).text
|
||||
htmltree = etree.HTML(htmlcode)
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getNum(self, htmltree):
|
||||
num = super().getNum(htmltree).upper()
|
||||
if self.number != num:
|
||||
raise Exception(f'[!] {self.number}: find [{num}] in pcolle, not match')
|
||||
return "PCOLLE-" + str(num)
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
result = self.getTreeAll(htmltree, self.expr_outline)
|
||||
try:
|
||||
return "\n".join(result)
|
||||
except:
|
||||
return ""
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
return super().getRelease(htmltree).replace('年', '-').replace('月', '-').replace('日', '')
|
||||
|
||||
def getCover(self, htmltree):
|
||||
if ".gif" in super().getCover(htmltree) and len(super().getExtrafanart(htmltree)) != 0:
|
||||
return super().getExtrafanart(htmltree)[0]
|
||||
return super().getCover(htmltree)
|
||||
87
scrapinglib/pissplay.py
Normal file
@@ -0,0 +1,87 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
from lxml import etree
|
||||
from .parser import Parser
|
||||
from datetime import datetime
|
||||
|
||||
# 搜刮 https://pissplay.com/ 中的视频
|
||||
# pissplay中的视频没有番号,所以要通过文件名搜索
|
||||
# 只用文件名和网站视频名完全一致时才可以被搜刮
|
||||
class Pissplay(Parser):
|
||||
source = 'pissplay'
|
||||
|
||||
expr_number = '//*[@id="video_title"]/text()' #这个网站上的视频没有番号,因此用标题代替
|
||||
expr_title = '//*[@id="video_title"]/text()'
|
||||
expr_cover = '/html/head//meta[@property="og:image"]/@content'
|
||||
expr_tags = '//div[@id="video_tags"]/a/text()'
|
||||
expr_release = '//div[@class="video_date"]/text()'
|
||||
expr_outline = '//*[@id="video_description"]/p//text()'
|
||||
|
||||
def extraInit(self):
|
||||
self.imagecut = 0 # 不裁剪封面
|
||||
self.specifiedSource = None
|
||||
|
||||
def search(self, number):
|
||||
self.number = number.strip().upper()
|
||||
if self.specifiedUrl:
|
||||
self.detailurl = self.specifiedUrl
|
||||
else:
|
||||
newName = re.sub(r"[^a-zA-Z0-9 ]", "", number) # 删除特殊符号
|
||||
self.detailurl = "https://pissplay.com/videos/" + newName.lower().replace(" ","-") + "/"
|
||||
self.htmlcode = self.getHtml(self.detailurl)
|
||||
if self.htmlcode == 404:
|
||||
return 404
|
||||
htmltree = etree.fromstring(self.htmlcode, etree.HTMLParser())
|
||||
result = self.dictformat(htmltree)
|
||||
return result
|
||||
|
||||
def getNum(self, htmltree):
|
||||
title = self.getTitle(htmltree)
|
||||
return title
|
||||
|
||||
def getTitle(self, htmltree):
|
||||
title = super().getTitle(htmltree)
|
||||
title = re.sub(r"[^a-zA-Z0-9 ]", "", title) # 删除特殊符号
|
||||
return title
|
||||
|
||||
def getCover(self, htmltree):
|
||||
url = super().getCover(htmltree)
|
||||
if not url.startswith('http'):
|
||||
url = 'https:' + url
|
||||
return url
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
releaseDate = super().getRelease(htmltree)
|
||||
isoData = datetime.strptime(releaseDate, '%d %b %Y').strftime('%Y-%m-%d')
|
||||
return isoData
|
||||
|
||||
def getStudio(self, htmltree):
|
||||
return 'PissPlay'
|
||||
|
||||
def getTags(self, htmltree):
|
||||
tags = self.getTreeAll(htmltree, self.expr_tags)
|
||||
if 'Guests' in tags:
|
||||
if tags[0] == 'Collaboration' or tags[0] == 'Toilet for a Day' or tags[0] == 'Collaboration':
|
||||
del tags[1]
|
||||
else:
|
||||
tags = tags[1:]
|
||||
return tags
|
||||
|
||||
def getActors(self, htmltree) -> list:
|
||||
tags = self.getTreeAll(htmltree, self.expr_tags)
|
||||
if 'Guests' in tags:
|
||||
if tags[0] == 'Collaboration' or tags[0] == 'Toilet for a Day' or tags[0] == 'Collaboration':
|
||||
return [tags[1]]
|
||||
else:
|
||||
return [tags[0]]
|
||||
else:
|
||||
return ['Bruce and Morgan']
|
||||
|
||||
def getOutline(self, htmltree):
|
||||
outline = self.getTreeAll(htmltree, self.expr_outline)
|
||||
if '– Morgan xx' in outline:
|
||||
num = outline.index('– Morgan xx')
|
||||
outline = outline[:num]
|
||||
rstring = ''.join(outline).replace("&","and")
|
||||
return rstring
|
||||
274
scrapinglib/storyline.py
Normal file
@@ -0,0 +1,274 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
此部分暂未修改
|
||||
|
||||
"""
|
||||
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
import time
|
||||
import secrets
|
||||
import builtins
|
||||
import config
|
||||
|
||||
from urllib.parse import urljoin
|
||||
from lxml.html import fromstring
|
||||
from multiprocessing.dummy import Pool as ThreadPool
|
||||
|
||||
from .airav import Airav
|
||||
from .xcity import Xcity
|
||||
from .httprequest import get_html_by_form, get_html_by_scraper, request_session
|
||||
|
||||
# 舍弃 Amazon 源
|
||||
G_registered_storyline_site = {"airavwiki", "airav", "avno1", "xcity", "58avgo"}
|
||||
|
||||
G_mode_txt = ('顺序执行','线程池')
|
||||
def is_japanese(raw: str) -> bool:
|
||||
"""
|
||||
日语简单检测
|
||||
"""
|
||||
return bool(re.search(r'[\u3040-\u309F\u30A0-\u30FF\uFF66-\uFF9F]', raw, re.UNICODE))
|
||||
|
||||
class noThread(object):
|
||||
def map(self, fn, param):
|
||||
return list(builtins.map(fn, param))
|
||||
def __enter__(self):
|
||||
return self
|
||||
def __exit__(self, exc_type, exc_val, exc_tb):
|
||||
pass
|
||||
|
||||
|
||||
# 获取剧情介绍 从列表中的站点同时查,取值优先级从前到后
|
||||
def getStoryline(number, title=None, sites: list=None, uncensored=None, proxies=None, verify=None):
|
||||
start_time = time.time()
|
||||
debug = False
|
||||
storyine_sites = config.getInstance().storyline_site().split(",") # "1:airav,4:airavwiki".split(',')
|
||||
if uncensored:
|
||||
storyine_sites = config.getInstance().storyline_uncensored_site().split(
|
||||
",") + storyine_sites # "3:58avgo".split(',')
|
||||
else:
|
||||
storyine_sites = config.getInstance().storyline_censored_site().split(
|
||||
",") + storyine_sites # "2:airav,5:xcity".split(',')
|
||||
r_dup = set()
|
||||
sort_sites = []
|
||||
for s in storyine_sites:
|
||||
if s in G_registered_storyline_site and s not in r_dup:
|
||||
sort_sites.append(s)
|
||||
r_dup.add(s)
|
||||
# sort_sites.sort()
|
||||
mp_args = ((site, number, title, debug, proxies, verify) for site in sort_sites)
|
||||
cores = min(len(sort_sites), os.cpu_count())
|
||||
if cores == 0:
|
||||
return ''
|
||||
run_mode = 1
|
||||
with ThreadPool(cores) if run_mode > 0 else noThread() as pool:
|
||||
results = pool.map(getStoryline_mp, mp_args)
|
||||
sel = ''
|
||||
|
||||
# 以下debug结果输出会写入日志
|
||||
s = f'[!]Storyline{G_mode_txt[run_mode]}模式运行{len(sort_sites)}个任务共耗时(含启动开销){time.time() - start_time:.3f}秒,结束于{time.strftime("%H:%M:%S")}'
|
||||
sel_site = ''
|
||||
for site, desc in zip(sort_sites, results):
|
||||
if isinstance(desc, str) and len(desc):
|
||||
if not is_japanese(desc):
|
||||
sel_site, sel = site, desc
|
||||
break
|
||||
if not len(sel_site):
|
||||
sel_site, sel = site, desc
|
||||
for site, desc in zip(sort_sites, results):
|
||||
sl = len(desc) if isinstance(desc, str) else 0
|
||||
s += f',[选中{site}字数:{sl}]' if site == sel_site else f',{site}字数:{sl}' if sl else f',{site}:空'
|
||||
if config.getInstance().debug():
|
||||
print(s)
|
||||
return sel
|
||||
|
||||
|
||||
def getStoryline_mp(args):
|
||||
(site, number, title, debug, proxies, verify) = args
|
||||
start_time = time.time()
|
||||
storyline = None
|
||||
if not isinstance(site, str):
|
||||
return storyline
|
||||
elif site == "airavwiki":
|
||||
storyline = getStoryline_airavwiki(number, debug, proxies, verify)
|
||||
elif site == "airav":
|
||||
storyline = getStoryline_airav(number, debug, proxies, verify)
|
||||
elif site == "avno1":
|
||||
storyline = getStoryline_avno1(number, debug, proxies, verify)
|
||||
elif site == "xcity":
|
||||
storyline = getStoryline_xcity(number, debug, proxies, verify)
|
||||
elif site == "58avgo":
|
||||
storyline = getStoryline_58avgo(number, debug, proxies, verify)
|
||||
if not debug:
|
||||
return storyline
|
||||
if config.getInstance().debug():
|
||||
print("[!]MP 线程[{}]运行{:.3f}秒,结束于{}返回结果: {}".format(
|
||||
site,
|
||||
time.time() - start_time,
|
||||
time.strftime("%H:%M:%S"),
|
||||
storyline if isinstance(storyline, str) and len(storyline) else '[空]')
|
||||
)
|
||||
return storyline
|
||||
|
||||
|
||||
def getStoryline_airav(number, debug, proxies, verify):
|
||||
try:
|
||||
site = secrets.choice(('airav.cc','airav4.club'))
|
||||
url = f'https://{site}/searchresults.aspx?Search={number}&Type=0'
|
||||
session = request_session(proxies=proxies, verify=verify)
|
||||
res = session.get(url)
|
||||
if not res:
|
||||
raise ValueError(f"get_html_by_session('{url}') failed")
|
||||
lx = fromstring(res.text)
|
||||
urls = lx.xpath('//div[@class="resultcontent"]/ul/li/div/a[@class="ga_click"]/@href')
|
||||
txts = lx.xpath('//div[@class="resultcontent"]/ul/li/div/a[@class="ga_click"]/h3[@class="one_name ga_name"]/text()')
|
||||
detail_url = None
|
||||
for txt, url in zip(txts, urls):
|
||||
if re.search(number, txt, re.I):
|
||||
detail_url = urljoin(res.url, url)
|
||||
break
|
||||
if detail_url is None:
|
||||
raise ValueError("number not found")
|
||||
res = session.get(detail_url)
|
||||
if not res.ok:
|
||||
raise ValueError(f"session.get('{detail_url}') failed")
|
||||
lx = fromstring(res.text)
|
||||
t = str(lx.xpath('/html/head/title/text()')[0]).strip()
|
||||
airav_number = str(re.findall(r'^\s*\[(.*?)]', t)[0])
|
||||
if not re.search(number, airav_number, re.I):
|
||||
raise ValueError(f"page number ->[{airav_number}] not match")
|
||||
desc = str(lx.xpath('//span[@id="ContentPlaceHolder1_Label2"]/text()')[0]).strip()
|
||||
return desc
|
||||
except Exception as e:
|
||||
if debug:
|
||||
print(f"[-]MP getStoryline_airav Error: {e},number [{number}].")
|
||||
pass
|
||||
return None
|
||||
|
||||
|
||||
def getStoryline_airavwiki(number, debug, proxies, verify):
|
||||
try:
|
||||
kwd = number[:6] if re.match(r'\d{6}[\-_]\d{2,3}', number) else number
|
||||
airavwiki = Airav()
|
||||
airavwiki.addtion_Javbus = False
|
||||
airavwiki.proxies = proxies
|
||||
airavwiki.verify = verify
|
||||
jsons = airavwiki.search(kwd)
|
||||
outline = json.loads(jsons).get('outline')
|
||||
return outline
|
||||
except Exception as e:
|
||||
if debug:
|
||||
print(f"[-]MP def getStoryline_airavwiki Error: {e}, number [{number}].")
|
||||
pass
|
||||
return ''
|
||||
|
||||
|
||||
def getStoryline_58avgo(number, debug, proxies, verify):
|
||||
try:
|
||||
url = 'http://58avgo.com/cn/index.aspx' + secrets.choice([
|
||||
'', '?status=3', '?status=4', '?status=7', '?status=9', '?status=10', '?status=11', '?status=12',
|
||||
'?status=1&Sort=Playon', '?status=1&Sort=dateupload', 'status=1&Sort=dateproduce'
|
||||
]) # 随机选一个,避免网站httpd日志中单个ip的请求太过单一
|
||||
kwd = number[:6] if re.match(r'\d{6}[\-_]\d{2,3}', number) else number
|
||||
result, browser = get_html_by_form(url,
|
||||
fields = {'ctl00$TextBox_SearchKeyWord' : kwd},
|
||||
proxies=proxies, verify=verify,
|
||||
return_type = 'browser')
|
||||
if not result:
|
||||
raise ValueError(f"get_html_by_form('{url}','{number}') failed")
|
||||
if f'searchresults.aspx?Search={kwd}' not in browser.url:
|
||||
raise ValueError("number not found")
|
||||
s = browser.page.select('div.resultcontent > ul > li.listItem > div.one-info-panel.one > a.ga_click')
|
||||
link = None
|
||||
for a in s:
|
||||
title = a.h3.text.strip()
|
||||
list_number = title[title.rfind(' ')+1:].strip()
|
||||
if re.search(number, list_number, re.I):
|
||||
link = a
|
||||
break
|
||||
if link is None:
|
||||
raise ValueError("number not found")
|
||||
result = browser.follow_link(link)
|
||||
if not result.ok or 'playon.aspx' not in browser.url:
|
||||
raise ValueError("detail page not found")
|
||||
title = browser.page.select_one('head > title').text.strip()
|
||||
detail_number = str(re.findall('\[(.*?)]', title)[0])
|
||||
if not re.search(number, detail_number, re.I):
|
||||
raise ValueError(f"detail page number not match, got ->[{detail_number}]")
|
||||
return browser.page.select_one('#ContentPlaceHolder1_Label2').text.strip()
|
||||
except Exception as e:
|
||||
if debug:
|
||||
print(f"[-]MP getOutline_58avgo Error: {e}, number [{number}].")
|
||||
pass
|
||||
return ''
|
||||
|
||||
|
||||
def getStoryline_avno1(number, debug, proxies, verify): #获取剧情介绍 从avno1.cc取得
|
||||
try:
|
||||
site = secrets.choice(['1768av.club','2nine.net','av999.tv','avno1.cc',
|
||||
'hotav.biz','iqq2.xyz','javhq.tv',
|
||||
'www.hdsex.cc','www.porn18.cc','www.xxx18.cc',])
|
||||
url = f'http://{site}/cn/search.php?kw_type=key&kw={number}'
|
||||
lx = fromstring(get_html_by_scraper(url, proxies=proxies, verify=verify))
|
||||
descs = lx.xpath('//div[@class="type_movie"]/div/ul/li/div/@data-description')
|
||||
titles = lx.xpath('//div[@class="type_movie"]/div/ul/li/div/a/h3/text()')
|
||||
if not descs or not len(descs):
|
||||
raise ValueError(f"number not found")
|
||||
partial_num = bool(re.match(r'\d{6}[\-_]\d{2,3}', number))
|
||||
for title, desc in zip(titles, descs):
|
||||
page_number = title[title.rfind(' ')+1:].strip()
|
||||
if not partial_num:
|
||||
# 不选择title中带破坏版的简介
|
||||
if re.match(f'^{number}$', page_number, re.I) and title.rfind('破坏版')== -1:
|
||||
return desc.strip()
|
||||
elif re.search(number, page_number, re.I):
|
||||
return desc.strip()
|
||||
raise ValueError(f"page number ->[{page_number}] not match")
|
||||
except Exception as e:
|
||||
if debug:
|
||||
print(f"[-]MP getOutline_avno1 Error: {e}, number [{number}].")
|
||||
pass
|
||||
return ''
|
||||
|
||||
|
||||
def getStoryline_avno1OLD(number, debug, proxies, verify): #获取剧情介绍 从avno1.cc取得
|
||||
try:
|
||||
url = 'http://www.avno1.cc/cn/' + secrets.choice(['usercenter.php?item=' +
|
||||
secrets.choice(['pay_support', 'qa', 'contact', 'guide-vpn']),
|
||||
'?top=1&cat=hd', '?top=1', '?cat=hd', 'porn', '?cat=jp', '?cat=us', 'recommend_category.php'
|
||||
]) # 随机选一个,避免网站httpd日志中单个ip的请求太过单一
|
||||
result, browser = get_html_by_form(url,
|
||||
form_select='div.wrapper > div.header > div.search > form',
|
||||
fields = {'kw' : number},
|
||||
proxies=proxies, verify=verify,
|
||||
return_type = 'browser')
|
||||
if not result:
|
||||
raise ValueError(f"get_html_by_form('{url}','{number}') failed")
|
||||
s = browser.page.select('div.type_movie > div > ul > li > div')
|
||||
for div in s:
|
||||
title = div.a.h3.text.strip()
|
||||
page_number = title[title.rfind(' ')+1:].strip()
|
||||
if re.search(number, page_number, re.I):
|
||||
return div['data-description'].strip()
|
||||
raise ValueError(f"page number ->[{page_number}] not match")
|
||||
except Exception as e:
|
||||
if debug:
|
||||
print(f"[-]MP getOutline_avno1 Error: {e}, number [{number}].")
|
||||
pass
|
||||
return ''
|
||||
|
||||
|
||||
def getStoryline_xcity(number, debug, proxies, verify): #获取剧情介绍 从xcity取得
|
||||
try:
|
||||
xcityEngine = Xcity()
|
||||
xcityEngine.proxies = proxies
|
||||
xcityEngine.verify = verify
|
||||
jsons = xcityEngine.search(number)
|
||||
outline = json.loads(jsons).get('outline')
|
||||
return outline
|
||||
except Exception as e:
|
||||
if debug:
|
||||
print(f"[-]MP getOutline_xcity Error: {e}, number [{number}].")
|
||||
pass
|
||||
return ''
|
||||
35
scrapinglib/tmdb.py
Normal file
@@ -0,0 +1,35 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Tmdb(Parser):
|
||||
"""
|
||||
两种实现,带apikey与不带key
|
||||
apikey
|
||||
"""
|
||||
source = 'tmdb'
|
||||
imagecut = 0
|
||||
apikey = None
|
||||
|
||||
expr_title = '//head/meta[@property="og:title"]/@content'
|
||||
expr_release = '//div/span[@class="release"]/text()'
|
||||
expr_cover = '//head/meta[@property="og:image"]/@content'
|
||||
expr_outline = '//head/meta[@property="og:description"]/@content'
|
||||
|
||||
# def search(self, number):
|
||||
# self.detailurl = self.queryNumberUrl(number)
|
||||
# detailpage = self.getHtml(self.detailurl)
|
||||
|
||||
def queryNumberUrl(self, number):
|
||||
"""
|
||||
TODO 区分 ID 与 名称
|
||||
"""
|
||||
id = number
|
||||
movieUrl = "https://www.themoviedb.org/movie/" + id + "?language=zh-CN"
|
||||
return movieUrl
|
||||
|
||||
def getCover(self, htmltree):
|
||||
return "https://www.themoviedb.org" + self.getTreeElement(htmltree, self.expr_cover)
|
||||
|
||||
31
scrapinglib/utils.py
Normal file
@@ -0,0 +1,31 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
from lxml.html import HtmlElement
|
||||
|
||||
def getTreeElement(tree: HtmlElement, expr='', index=0):
|
||||
""" 根据表达式从`xmltree`中获取匹配值,默认 index 为 0
|
||||
:param tree (html.HtmlElement)
|
||||
:param expr
|
||||
:param index
|
||||
"""
|
||||
if expr == '':
|
||||
return ''
|
||||
result = tree.xpath(expr)
|
||||
try:
|
||||
return result[index]
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getTreeAll(tree: HtmlElement, expr=''):
|
||||
""" 根据表达式从`xmltree`中获取全部匹配值
|
||||
:param tree (html.HtmlElement)
|
||||
:param expr
|
||||
:param index
|
||||
"""
|
||||
if expr == '':
|
||||
return []
|
||||
result = tree.xpath(expr)
|
||||
try:
|
||||
return result
|
||||
except:
|
||||
return []
|
||||
92
scrapinglib/xcity.py
Normal file
@@ -0,0 +1,92 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
import re
|
||||
import secrets
|
||||
from urllib.parse import urljoin
|
||||
from .httprequest import get_html_by_form
|
||||
from .parser import Parser
|
||||
|
||||
|
||||
class Xcity(Parser):
|
||||
source = 'xcity'
|
||||
|
||||
expr_number = '//*[@id="hinban"]/text()'
|
||||
expr_title = '//*[@id="program_detail_title"]/text()'
|
||||
expr_actor = '//ul/li[@class="credit-links"]/a/text()'
|
||||
expr_actor_link = '//ul/li[@class="credit-links"]/a'
|
||||
expr_actorphoto = '//div[@class="frame"]/div/p/img/@src'
|
||||
expr_studio = '//*[@id="avodDetails"]/div/div[3]/div[2]/div/ul[1]/li[4]/a/span/text()'
|
||||
expr_studio2 = '//strong[contains(text(),"片商")]/../following-sibling::span/a/text()'
|
||||
expr_runtime = '//span[@class="koumoku" and text()="収録時間"]/../text()'
|
||||
expr_label = '//*[@id="avodDetails"]/div/div[3]/div[2]/div/ul[1]/li[5]/a/span/text()'
|
||||
expr_release = '//*[@id="avodDetails"]/div/div[3]/div[2]/div/ul[1]/li[2]/text()'
|
||||
expr_tags = '//span[@class="koumoku" and text()="ジャンル"]/../a[starts-with(@href,"/avod/genre/")]/text()'
|
||||
expr_cover = '//*[@id="avodDetails"]/div/div[3]/div[1]/p/a/@href'
|
||||
expr_director = '//*[@id="program_detail_director"]/text()'
|
||||
expr_series = "//span[contains(text(),'シリーズ')]/../a/span/text()"
|
||||
expr_series2 = "//span[contains(text(),'シリーズ')]/../span/text()"
|
||||
expr_extrafanart = '//div[@id="sample_images"]/div/a/@href'
|
||||
expr_outline = '//head/meta[@property="og:description"]/@content'
|
||||
|
||||
def queryNumberUrl(self, number):
|
||||
xcity_number = number.replace('-','')
|
||||
query_result, browser = get_html_by_form(
|
||||
'https://xcity.jp/' + secrets.choice(['sitemap/','policy/','law/','help/','main/']),
|
||||
fields = {'q' : xcity_number.lower()},
|
||||
cookies=self.cookies, proxies=self.proxies, verify=self.verify,
|
||||
return_type = 'browser')
|
||||
if not query_result or not query_result.ok:
|
||||
raise ValueError("xcity.py: page not found")
|
||||
prelink = browser.links('avod\/detail')[0]['href']
|
||||
return urljoin('https://xcity.jp', prelink)
|
||||
|
||||
def getStudio(self, htmltree):
|
||||
return super().getStudio(htmltree).strip('+').replace("', '", '').replace('"', '')
|
||||
|
||||
def getRuntime(self, htmltree):
|
||||
return self.getTreeElement(htmltree, self.expr_runtime, 1).strip()
|
||||
|
||||
def getRelease(self, htmltree):
|
||||
try:
|
||||
result = self.getTreeElement(htmltree, self.expr_release, 1)
|
||||
return re.findall('\d{4}/\d{2}/\d{2}', result)[0].replace('/','-')
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getCover(self, htmltree):
|
||||
try:
|
||||
result = super().getCover(htmltree)
|
||||
return 'https:' + result
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getDirector(self, htmltree):
|
||||
try:
|
||||
result = super().getDirector(htmltree).replace(u'\n','').replace(u'\t', '')
|
||||
return result
|
||||
except:
|
||||
return ''
|
||||
|
||||
def getActorPhoto(self, htmltree):
|
||||
treea = self.getTreeAll(htmltree, self.expr_actor_link)
|
||||
t = {i.text.strip(): i.attrib['href'] for i in treea}
|
||||
o = {}
|
||||
for k, v in t.items():
|
||||
actorpageUrl = "https://xcity.jp" + v
|
||||
try:
|
||||
adtree = self.getHtmlTree(actorpageUrl)
|
||||
picUrl = self.getTreeElement(adtree, self.expr_actorphoto)
|
||||
if 'noimage.gif' in picUrl:
|
||||
continue
|
||||
o[k] = urljoin("https://xcity.jp", picUrl)
|
||||
except:
|
||||
pass
|
||||
return o
|
||||
|
||||
def getExtrafanart(self, htmltree):
|
||||
arts = self.getTreeAll(htmltree, self.expr_extrafanart)
|
||||
extrafanart = []
|
||||
for i in arts:
|
||||
i = "https:" + i
|
||||
extrafanart.append(i)
|
||||
return extrafanart
|
||||
104
siro.py
@@ -1,104 +0,0 @@
|
||||
import re
|
||||
from lxml import etree
|
||||
import json
|
||||
from bs4 import BeautifulSoup
|
||||
from ADC_function import *
|
||||
|
||||
def getTitle(a):
|
||||
try:
|
||||
html = etree.fromstring(a, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="center_column"]/div[2]/h1/text()')).strip(" ['']")
|
||||
return result.replace('/', ',')
|
||||
except:
|
||||
return ''
|
||||
def getActor(a): #//*[@id="center_column"]/div[2]/div[1]/div/table/tbody/tr[1]/td/text()
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result1=str(html.xpath('//th[contains(text(),"出演:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
result2=str(html.xpath('//th[contains(text(),"出演:")]/../td/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
return str(result1+result2).strip('+').replace("', '",'').replace('"','').replace('/',',')
|
||||
def getStudio(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) #//table/tr[1]/td[1]/text()
|
||||
result1=str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
result2=str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
return str(result1+result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getRuntime(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"収録時間:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"収録時間:")]/../td/text()')).strip(" ['']").strip('\\n ').strip('\\n')
|
||||
return str(result1 + result2).strip('+').rstrip('mi')
|
||||
def getLabel(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"シリーズ:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getNum(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"品番:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"品番:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+')
|
||||
def getYear(getRelease):
|
||||
try:
|
||||
result = str(re.search('\d{4}',getRelease).group())
|
||||
return result
|
||||
except:
|
||||
return getRelease
|
||||
def getRelease(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"配信開始日:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"配信開始日:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+')
|
||||
def getTag(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"ジャンル:")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"ジャンル:")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+').replace("', '\\n",",").replace("', '","").replace('"','')
|
||||
def getCover(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="center_column"]/div[2]/div[1]/div/div/h2/img/@src')).strip(" ['']")
|
||||
return result
|
||||
def getDirector(a):
|
||||
html = etree.fromstring(a, etree.HTMLParser()) # //table/tr[1]/td[1]/text()
|
||||
result1 = str(html.xpath('//th[contains(text(),"シリーズ")]/../td/a/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
result2 = str(html.xpath('//th[contains(text(),"シリーズ")]/../td/text()')).strip(" ['']").strip('\\n ').strip(
|
||||
'\\n')
|
||||
return str(result1 + result2).strip('+').replace("', '",'').replace('"','')
|
||||
def getOutline(htmlcode):
|
||||
html = etree.fromstring(htmlcode, etree.HTMLParser())
|
||||
result = str(html.xpath('//*[@id="introduction"]/dd/p[1]/text()')).strip(" ['']")
|
||||
return result
|
||||
def main(number2):
|
||||
number=number2.upper()
|
||||
htmlcode=get_html('https://www.mgstage.com/product/product_detail/'+str(number)+'/',cookies={'adc':'1'})
|
||||
soup = BeautifulSoup(htmlcode, 'lxml')
|
||||
a = str(soup.find(attrs={'class': 'detail_data'})).replace('\n ','').replace(' ','').replace('\n ','').replace('\n ','')
|
||||
dic = {
|
||||
'title': getTitle(htmlcode).replace("\\n",'').replace(' ',''),
|
||||
'studio': getStudio(a),
|
||||
'outline': getOutline(htmlcode),
|
||||
'runtime': getRuntime(a),
|
||||
'director': getDirector(a),
|
||||
'actor': getActor(a),
|
||||
'release': getRelease(a),
|
||||
'number': getNum(a),
|
||||
'cover': getCover(htmlcode),
|
||||
'imagecut': 0,
|
||||
'tag': getTag(a),
|
||||
'label':getLabel(a),
|
||||
'year': getYear(getRelease(a)), # str(re.search('\d{4}',getRelease(a)).group()),
|
||||
'actor_photo': '',
|
||||
'website':'https://www.mgstage.com/product/product_detail/'+str(number)+'/',
|
||||
'source': 'siro.py',
|
||||
}
|
||||
js = json.dumps(dic, ensure_ascii=False, sort_keys=True, indent=4, separators=(',', ':'),)#.encode('UTF-8')
|
||||
return js
|
||||
|
||||
#print(main('300maan-373'))
|
||||
@@ -1,5 +1,5 @@
|
||||
{
|
||||
"version": "1.3",
|
||||
"version_show":"1.3",
|
||||
"download": "https://github.com/wenead99/AV_Data_Capture/releases"
|
||||
"version": "4.6.7",
|
||||
"version_show": "4.6.7",
|
||||
"download": "https://github.com/yoshiko2/AV_Data_Capture/releases"
|
||||
}
|
||||
|
||||
12
wrapper/FreeBSD.sh
Executable file
@@ -0,0 +1,12 @@
|
||||
pkg install python39 py39-requests py39-pip py39-lxml py39-pillow py39-cloudscraper py39-pysocks git zip py39-beautifulsoup448 py39-mechanicalsoup
|
||||
pip install pyinstaller
|
||||
pyinstaller --onefile Movie_Data_Capture.py --hidden-import ADC_function.py --hidden-import core.py \
|
||||
--hidden-import "ImageProcessing.cnn" \
|
||||
--python-option u \
|
||||
--add-data "$(python3.9 -c 'import cloudscraper as _; print(_.__path__[0])' | tail -n 1):cloudscraper" \
|
||||
--add-data "$(python3.9 -c 'import opencc as _; print(_.__path__[0])' | tail -n 1):opencc" \
|
||||
--add-data "$(python3.9 -c 'import face_recognition_models as _; print(_.__path__[0])' | tail -n 1):face_recognition_models" \
|
||||
--add-data "Img:Img" \
|
||||
--add-data "config.ini:." \
|
||||
|
||||
cp config.ini ./dist
|
||||
24
wrapper/Linux.sh
Executable file
@@ -0,0 +1,24 @@
|
||||
#if [ '$(dpkg --print-architecture)' != 'amd64' ] || [ '$(dpkg --print-architecture)' != 'i386' ]; then
|
||||
# apt install python3 python3-pip git sudo libxml2-dev libxslt-dev build-essential wget nano libcmocka-dev libcmocka0 -y
|
||||
# apt install zlib* libjpeg-dev -y
|
||||
#wget https://files.pythonhosted.org/packages/82/96/21ba3619647bac2b34b4996b2dbbea8e74a703767ce24192899d9153c058/pyinstaller-4.0.tar.gz
|
||||
#tar -zxvf pyinstaller-4.0.tar.gz
|
||||
#cd pyinstaller-4.0/bootloader
|
||||
#sed -i "s/ '-Werror',//" wscript
|
||||
#python3 ./waf distclean all
|
||||
#cd ../
|
||||
#python3 setup.py install
|
||||
#cd ../
|
||||
#fi
|
||||
pip3 install -r requirements.txt
|
||||
pip3 install cloudscraper==1.2.52
|
||||
pyinstaller --onefile Movie_Data_Capture.py --hidden-import ADC_function.py --hidden-import core.py \
|
||||
--hidden-import "ImageProcessing.cnn" \
|
||||
--python-option u \
|
||||
--add-data "$(python3 -c 'import cloudscraper as _; print(_.__path__[0])' | tail -n 1):cloudscraper" \
|
||||
--add-data "$(python3 -c 'import opencc as _; print(_.__path__[0])' | tail -n 1):opencc" \
|
||||
--add-data "$(python3 -c 'import face_recognition_models as _; print(_.__path__[0])' | tail -n 1):face_recognition_models" \
|
||||
--add-data "Img:Img" \
|
||||
--add-data "config.ini:." \
|
||||
|
||||
cp config.ini ./dist
|
||||
329
xlog.py
Executable file
@@ -0,0 +1,329 @@
|
||||
import os
|
||||
import sys
|
||||
import time
|
||||
from datetime import datetime
|
||||
import traceback
|
||||
import threading
|
||||
import json
|
||||
import shutil
|
||||
|
||||
CRITICAL = 50
|
||||
FATAL = CRITICAL
|
||||
ERROR = 40
|
||||
WARNING = 30
|
||||
WARN = WARNING
|
||||
INFO = 20
|
||||
DEBUG = 10
|
||||
NOTSET = 0
|
||||
|
||||
|
||||
class Logger:
|
||||
def __init__(self, name, buffer_size=0, file_name=None, roll_num=1):
|
||||
self.err_color = '\033[0m'
|
||||
self.warn_color = '\033[0m'
|
||||
self.debug_color = '\033[0m'
|
||||
self.reset_color = '\033[0m'
|
||||
self.set_console_color = lambda color: sys.stderr.write(color)
|
||||
self.name = str(name)
|
||||
self.file_max_size = 1024 * 1024
|
||||
self.buffer_lock = threading.Lock()
|
||||
self.buffer = {} # id => line
|
||||
self.buffer_size = buffer_size
|
||||
self.last_no = 0
|
||||
self.min_level = NOTSET
|
||||
self.log_fd = None
|
||||
self.roll_num = roll_num
|
||||
if file_name:
|
||||
self.set_file(file_name)
|
||||
|
||||
def set_buffer(self, buffer_size):
|
||||
with self.buffer_lock:
|
||||
self.buffer_size = buffer_size
|
||||
buffer_len = len(self.buffer)
|
||||
if buffer_len > self.buffer_size:
|
||||
for i in range(self.last_no - buffer_len, self.last_no - self.buffer_size):
|
||||
try:
|
||||
del self.buffer[i]
|
||||
except:
|
||||
pass
|
||||
|
||||
def setLevel(self, level):
|
||||
if level == "DEBUG":
|
||||
self.min_level = DEBUG
|
||||
elif level == "INFO":
|
||||
self.min_level = INFO
|
||||
elif level == "WARN":
|
||||
self.min_level = WARN
|
||||
elif level == "ERROR":
|
||||
self.min_level = ERROR
|
||||
elif level == "FATAL":
|
||||
self.min_level = FATAL
|
||||
else:
|
||||
print(("log level not support:%s", level))
|
||||
|
||||
def set_color(self):
|
||||
self.err_color = None
|
||||
self.warn_color = None
|
||||
self.debug_color = None
|
||||
self.reset_color = None
|
||||
self.set_console_color = lambda x: None
|
||||
if hasattr(sys.stderr, 'isatty') and sys.stderr.isatty():
|
||||
if os.name == 'nt':
|
||||
self.err_color = 0x04
|
||||
self.warn_color = 0x06
|
||||
self.debug_color = 0x002
|
||||
self.reset_color = 0x07
|
||||
|
||||
import ctypes
|
||||
SetConsoleTextAttribute = ctypes.windll.kernel32.SetConsoleTextAttribute
|
||||
GetStdHandle = ctypes.windll.kernel32.GetStdHandle
|
||||
self.set_console_color = lambda color: SetConsoleTextAttribute(GetStdHandle(-11), color)
|
||||
|
||||
elif os.name == 'posix':
|
||||
self.err_color = '\033[31m'
|
||||
self.warn_color = '\033[33m'
|
||||
self.debug_color = '\033[32m'
|
||||
self.reset_color = '\033[0m'
|
||||
|
||||
self.set_console_color = lambda color: sys.stderr.write(color)
|
||||
|
||||
def set_file(self, file_name):
|
||||
self.log_filename = file_name
|
||||
if os.path.isfile(file_name):
|
||||
self.file_size = os.path.getsize(file_name)
|
||||
if self.file_size > self.file_max_size:
|
||||
self.roll_log()
|
||||
self.file_size = 0
|
||||
else:
|
||||
self.file_size = 0
|
||||
|
||||
self.log_fd = open(file_name, "a+")
|
||||
|
||||
def roll_log(self):
|
||||
for i in range(self.roll_num, 1, -1):
|
||||
new_name = "%s.%d" % (self.log_filename, i)
|
||||
old_name = "%s.%d" % (self.log_filename, i - 1)
|
||||
if not os.path.isfile(old_name):
|
||||
continue
|
||||
|
||||
# self.info("roll_log %s -> %s", old_name, new_name)
|
||||
shutil.move(old_name, new_name)
|
||||
|
||||
shutil.move(self.log_filename, self.log_filename + ".1")
|
||||
|
||||
def log_console(self, level, console_color, fmt, *args, **kwargs):
|
||||
try:
|
||||
console_string = '[%s] %s\n' % (level, fmt % args)
|
||||
self.set_console_color(console_color)
|
||||
sys.stderr.write(console_string)
|
||||
self.set_console_color(self.reset_color)
|
||||
except:
|
||||
pass
|
||||
|
||||
def log_to_file(self, level, console_color, fmt, *args, **kwargs):
|
||||
if self.log_fd:
|
||||
if level == 'e':
|
||||
string = '%s' % (fmt % args)
|
||||
else:
|
||||
time_str = datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")[:23]
|
||||
string = '%s [%s] [%s] %s\n' % (time_str, self.name, level, fmt % args)
|
||||
|
||||
self.log_fd.write(string)
|
||||
try:
|
||||
self.log_fd.flush()
|
||||
except:
|
||||
pass
|
||||
|
||||
self.file_size += len(string)
|
||||
if self.file_size > self.file_max_size:
|
||||
self.log_fd.close()
|
||||
self.log_fd = None
|
||||
self.roll_log()
|
||||
self.log_fd = open(self.log_filename, "w")
|
||||
self.file_size = 0
|
||||
|
||||
def log(self, level, console_color, html_color, fmt, *args, **kwargs):
|
||||
self.buffer_lock.acquire()
|
||||
try:
|
||||
self.log_console(level, console_color, fmt, *args, **kwargs)
|
||||
|
||||
self.log_to_file(level, console_color, fmt, *args, **kwargs)
|
||||
|
||||
if self.buffer_size:
|
||||
self.last_no += 1
|
||||
self.buffer[self.last_no] = string
|
||||
buffer_len = len(self.buffer)
|
||||
if buffer_len > self.buffer_size:
|
||||
del self.buffer[self.last_no - self.buffer_size]
|
||||
except Exception as e:
|
||||
string = '%s - [%s]LOG_EXCEPT: %s, Except:%s<br> %s' % (
|
||||
time.ctime()[4:-5], level, fmt % args, e, traceback.format_exc())
|
||||
self.last_no += 1
|
||||
self.buffer[self.last_no] = string
|
||||
buffer_len = len(self.buffer)
|
||||
if buffer_len > self.buffer_size:
|
||||
del self.buffer[self.last_no - self.buffer_size]
|
||||
finally:
|
||||
self.buffer_lock.release()
|
||||
|
||||
def debug(self, fmt, *args, **kwargs):
|
||||
if self.min_level > DEBUG:
|
||||
return
|
||||
self.log('-', self.debug_color, '21610b', fmt, *args, **kwargs)
|
||||
|
||||
def info(self, fmt, *args, **kwargs):
|
||||
if self.min_level > INFO:
|
||||
return
|
||||
self.log('+', self.reset_color, '000000', fmt, *args)
|
||||
|
||||
def warning(self, fmt, *args, **kwargs):
|
||||
if self.min_level > WARN:
|
||||
return
|
||||
self.log('#', self.warn_color, 'FF8000', fmt, *args, **kwargs)
|
||||
|
||||
def warn(self, fmt, *args, **kwargs):
|
||||
self.warning(fmt, *args, **kwargs)
|
||||
|
||||
def error(self, fmt, *args, **kwargs):
|
||||
if self.min_level > ERROR:
|
||||
return
|
||||
self.log('!', self.err_color, 'FE2E2E', fmt, *args, **kwargs)
|
||||
|
||||
def exception(self, fmt, *args, **kwargs):
|
||||
self.error(fmt, *args, **kwargs)
|
||||
string = '%s' % (traceback.format_exc())
|
||||
self.log_to_file('e', self.err_color, string)
|
||||
|
||||
def critical(self, fmt, *args, **kwargs):
|
||||
if self.min_level > CRITICAL:
|
||||
return
|
||||
self.log('!', self.err_color, 'D7DF01', fmt, *args, **kwargs)
|
||||
|
||||
def tofile(self, fmt, *args, **kwargs):
|
||||
self.log_to_file('@', self.warn_color, fmt, *args, **kwargs)
|
||||
|
||||
# =================================================================
|
||||
def set_buffer_size(self, set_size):
|
||||
self.buffer_lock.acquire()
|
||||
self.buffer_size = set_size
|
||||
buffer_len = len(self.buffer)
|
||||
if buffer_len > self.buffer_size:
|
||||
for i in range(self.last_no - buffer_len, self.last_no - self.buffer_size):
|
||||
try:
|
||||
del self.buffer[i]
|
||||
except:
|
||||
pass
|
||||
self.buffer_lock.release()
|
||||
|
||||
def get_last_lines(self, max_lines):
|
||||
self.buffer_lock.acquire()
|
||||
buffer_len = len(self.buffer)
|
||||
if buffer_len > max_lines:
|
||||
first_no = self.last_no - max_lines
|
||||
else:
|
||||
first_no = self.last_no - buffer_len + 1
|
||||
|
||||
jd = {}
|
||||
if buffer_len > 0:
|
||||
for i in range(first_no, self.last_no + 1):
|
||||
jd[i] = self.unicode_line(self.buffer[i])
|
||||
self.buffer_lock.release()
|
||||
return json.dumps(jd)
|
||||
|
||||
def get_new_lines(self, from_no):
|
||||
self.buffer_lock.acquire()
|
||||
jd = {}
|
||||
first_no = self.last_no - len(self.buffer) + 1
|
||||
if from_no < first_no:
|
||||
from_no = first_no
|
||||
|
||||
if self.last_no >= from_no:
|
||||
for i in range(from_no, self.last_no + 1):
|
||||
jd[i] = self.unicode_line(self.buffer[i])
|
||||
self.buffer_lock.release()
|
||||
return json.dumps(jd)
|
||||
|
||||
def unicode_line(self, line):
|
||||
try:
|
||||
if type(line) is str:
|
||||
return line
|
||||
else:
|
||||
return str(line, errors='ignore')
|
||||
except Exception as e:
|
||||
print(("unicode err:%r" % e))
|
||||
print(("line can't decode:%s" % line))
|
||||
print(("Except stack:%s" % traceback.format_exc()))
|
||||
return ""
|
||||
|
||||
|
||||
loggerDict = {}
|
||||
|
||||
|
||||
def getLogger(name=None, buffer_size=0, file_name=None, roll_num=1):
|
||||
global loggerDict, default_log
|
||||
if name is None:
|
||||
for n in loggerDict:
|
||||
name = n
|
||||
break
|
||||
if name is None:
|
||||
name = u"default"
|
||||
|
||||
if not isinstance(name, str):
|
||||
raise TypeError('A logger name must be string or Unicode')
|
||||
if isinstance(name, bytes):
|
||||
name = name.encode('utf-8')
|
||||
|
||||
if name in loggerDict:
|
||||
return loggerDict[name]
|
||||
else:
|
||||
logger_instance = Logger(name, buffer_size, file_name, roll_num)
|
||||
loggerDict[name] = logger_instance
|
||||
default_log = logger_instance
|
||||
return logger_instance
|
||||
|
||||
|
||||
default_log = getLogger()
|
||||
|
||||
|
||||
def debg(fmt, *args, **kwargs):
|
||||
default_log.debug(fmt, *args, **kwargs)
|
||||
|
||||
|
||||
def info(fmt, *args, **kwargs):
|
||||
default_log.info(fmt, *args, **kwargs)
|
||||
|
||||
|
||||
def warn(fmt, *args, **kwargs):
|
||||
default_log.warning(fmt, *args, **kwargs)
|
||||
|
||||
|
||||
def erro(fmt, *args, **kwargs):
|
||||
default_log.error(fmt, *args, **kwargs)
|
||||
|
||||
|
||||
def excp(fmt, *args, **kwargs):
|
||||
default_log.exception(fmt, *args, **kwargs)
|
||||
|
||||
|
||||
def crit(fmt, *args, **kwargs):
|
||||
default_log.critical(fmt, *args, **kwargs)
|
||||
|
||||
|
||||
def tofile(fmt, *args, **kwargs):
|
||||
default_log.tofile(fmt, *args, **kwargs)
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
log_file = os.path.join(os.path.dirname(sys.argv[0]), "test.log")
|
||||
getLogger().set_file(log_file)
|
||||
debg("debug")
|
||||
info("info")
|
||||
warn("warning")
|
||||
erro("error")
|
||||
crit("critical")
|
||||
tofile("write to file only")
|
||||
|
||||
try:
|
||||
1 / 0
|
||||
except Exception as e:
|
||||
excp("An error has occurred")
|
||||